







现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Elasticsearch查询原理
本文档深入探讨了Elasticsearch的查询原理,包括单个ID查询文档和多个ID查询文档的流程。在搜索查询方面,通过两阶段查询,首先在各个分片拷贝中搜索匹配的文档标识符,然后在协调节点合并结果并获取完整文档。此外,全文检索的执行流程也得到了详细解释,从分析器处理查询词到构建查询语法树、匹配文档、评分和排序等步骤,分析其复杂的工作流程。
1. ES配置
本文的介绍使用三节点的集群配置,索引分片配置为7.x版本默认的一主一副

2. 文档ID查询
Elasticsearch中的查询主要分为两类,Get请求:通过ID查询特定Doc;Search请求:通过Query查询匹配Doc。
2.1 单个ID查询文档
例如:当 ES客户端 将 单文档id Get请求发送到节点 2 时,节点 2 将作为协调节点来处理查询请求。由于哈希取模运算确定了文档所在的分片为 shard3,因此查询流程如下:
- 协调节点处理:节点 2(协调节点)接收到查询请求后,它将确定文档所在的分片为 shard3。
- 分片路由:节点 2 根据分片路由 知道 shard3 的主分片在节点 3 上,因此它将查询请求转发到节点 3。
- 文档检索:一旦查询请求到达节点 3,它将在 shard3 的主分片上执行文档检索操作并将检索到的文档结果返回给协调节点(节点 2)
- 最终返回:最后协调节点(节点 2)将收到来自数据节点(节点 3)的文档结果,并将其返回给客户端。
所以,查询流程如下:
ES客户端 -> Node 2 (协调节点) -> Node 3 (数据节点) -> Node 2 (协调节点) -> ES客户端
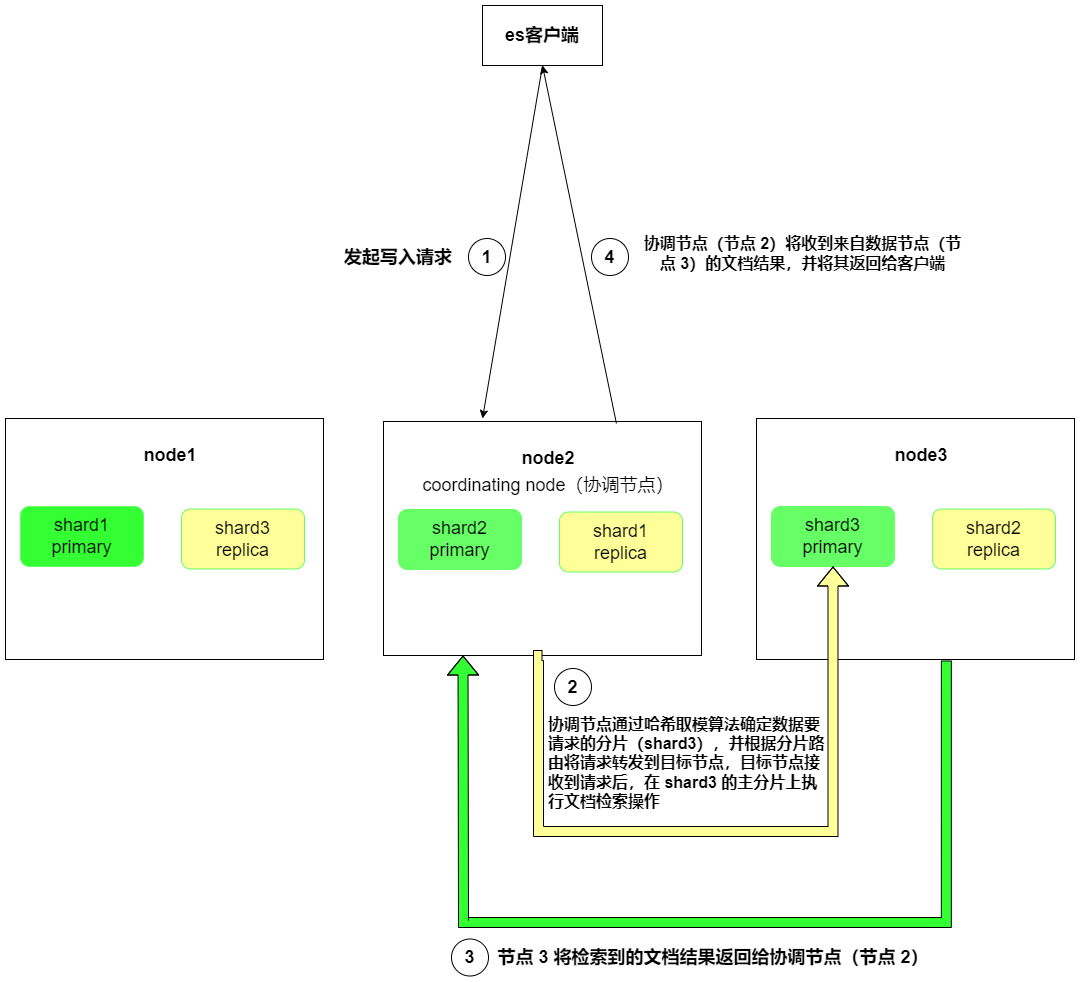
2.2 多个ID查询文档
对于 mget 请求,Elasticsearch 客户端会一次性发送多个文档ID,并且在协调节点(这里是节点 2)进行路由和汇总查询结果。
多文档ID查询(mget 请求)的流程:
- 协调节点处理:节点 2(协调节点)接收到
mget请求后,会根据每个文档ID的哈希值确定对应的分片。 - 分片路由:协调节点会根据每个文档ID的哈希值确定其所在的分片,并将查询请求路由到负责相应分片的节点上。
- 并行查询:每个数据节点接收到查询请求后,并行地搜索相应的文档。每个节点将同时处理其负责的文档ID的查询请求。
- 结果汇总:每个数据节点将查询结果返回给协调节点。
- 结果返回:协调节点收到来自数据节点的查询结果后,会将它们汇总并返回给 Elasticsearch 客户端。
3.搜索(Search)查询
3.1 索引建立
进行全文检索前,先回顾一下索引文档时的如何对全文进行分析处理
建立索引的过程中,对全文数据进行分析在Elasticsearch(ES)中通过分词组件和语言处理组件来完成。作用包括:
- 分词器:将文本分割为单个词条,例如按空格和标点符号进行分割,得到的单词称为词元(Token)。
- 字符过滤器:对文本进行预处理,例如去除HTML标签,替换符号,将"&"转换为"and"等操作。
- Token过滤器:根据停止词表删除无用词元,如"and"、“the"等,或者根据同义词表添加词条,比如"jump"和"leap”。
- 过滤器语言处理:对词元(Token)进行与语言相关的处理,例如转换为小写、词干提取、将单词转换为词根等形式。这些处理后的结果称为词(Term)。
完成分析后,将分析器输出的词传递给索引组件,生成倒排索引和正排索引,并将其存储到文件系统中。
下面图示参考:https://blog.csdn.net/weixin_41947378/article/details/109405386 3.6 创建索引流程总结
注意,以下表示一个es节点

在Elasticsearch中,配置分词器(Tokenizer)和语言处理组件(Token Filter)是通过创建或修改索引的分析器(Analyzer)来实现的。下面是一个简单的配置示例:
{
"settings": {
"analysis": {
"analyzer": {
"my\_analyzer": { // 这里是自定义的分析器名称
"type": "custom", // 自定义分析器
"tokenizer": "standard", // 使用标准分词器作为分词器
"char\_filter": ["remove\_symbols"], // 使用字符过滤器去除无用符号
"filter": [
"lowercase", // 将所有词元转换为小写
"english\_stop" // 停用词过滤器
]
}
},
"filter": {
"english\_stop": { // 停用词过滤器的配置
"type": "stop", // 停用词类型
"stopwords": "\_english\_" // 使用内置的英文停用词表
}
},
"char\_filter": {
"remove\_symbols": {
"type": "mapping",
"mappings": ["=>", ",", ".", "!"] // 需要移除的符号列表
}
}
}
}
}
要应用此配置,可以在创建索引时指定该分析器,或者在已有索引上修改分析器配置。例如:
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "my\_analyzer" // 指定使用自定义分析器
}
}
}
}
当文档的content字段被索引时,将会使用my_analyzer分析器进行文本分析和处理。
3.2 文档读取过程
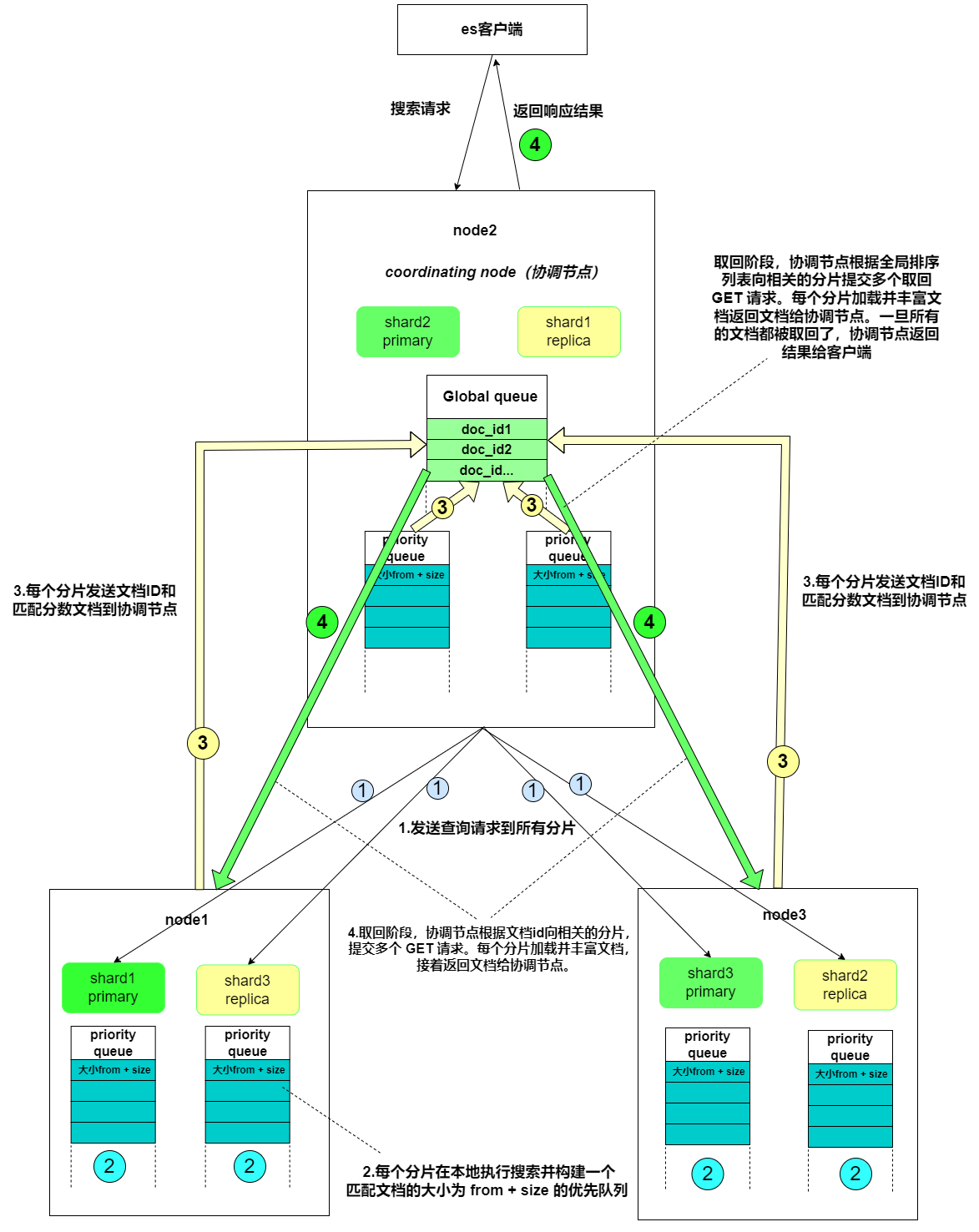
- 搜索系统通常采用两阶段查询(query_then_fetch):首先在第一阶段查询到匹配的文档标识符(DocID),然后在第二阶段查询这些标识符对应的完整文档。
- 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
- 每个分片返回各自优先队列中 所有文档的 ID 和排序值(例如 _score) 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
3.3 执行全文检索
- 分析器(Analyzer)处理查询词:首先,针对查询语句中的检索词,使用相同的分析器进行分析。分析器会将查询词拆分成词项(Tokens),这与建立索引时的处理方式相同。
- 构建查询语法树:根据查询语句的语法规则,将其转换成一棵语法树。这棵语法树描述了查询的逻辑结构,包括查询条件之间的逻辑关系以及操作符的作用。
- 匹配文档:根据语法树,在索引中查找符合查询条件的文档。这一步涉及到倒排索引的使用,根据词项快速定位匹配的文档。
- 评分:对匹配到的文档列表进行相关性评分。评分策略通常使用 **TF/IDF(词频-逆文档频率)或 BM25(BM25算法)**等算法,根据查询词项在文档中的出现频率、在索引中的逆文档频率等因素计算文档的相关性分数。
- 排序:根据评分结果,对匹配到的文档列表进行排序。相关性分数高的文档排在前面,以便用户首先看到最相关的结果。

3.4 TF/IDF模型和BM25算法
1.算分逻辑的步骤
Elasticsearch的算分逻辑是基于文档的相关性评分,通常使用**TF/IDF(词频-逆文档频率)或BM25(BM25算法)**等算法来计算。在搜索查询中,算分逻辑可以简单概括为以下几个步骤:
- 词项匹配度计算:首先,根据查询语句中的词项在文档中的出现频率(TF)以及在整个索引中的逆文档频率(IDF),计算每个词项的匹配度得分。
- 字段权重计算:对于查询语句中的每个字段,可以为其指定不同的权重,以反映字段在整个查询中的重要性。字段权重可以通过配置或者默认值进行设置。
- 文档长度归一化:由于文档长度可能不同,需要对匹配到的文档进行长度归一化,以确保长文档和短文档在得分计算中公平竞争。
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









