







(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
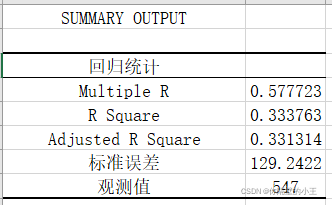
其中,
Multiple R:相关系数R,值在-1与1之间,越接近-1,代表越高的负相关,反之,代表越高的正相关关系。
R Square:测定系数,也叫拟合优度。是相关系数R的平方,同时也等于表2中回归分析SS/(回归分析SS+残差SS),这个值在0~1之间,越大,代表回归模型与实际数据的拟合程度越高。当这个值大于0.8时表示强正相关。
Adjusted R Square:校正的测定系数,对两个具有不同个数的自变量的回归方程进行比较时,还必须考虑方程所包含的自变量个数的影响,为此提出,所谓“最优”回归方程是指校正的决定系数最大者。
标准误差:等于残差SS / 残差df 的平方根,标准误差越小越好。
观测值:表示有多少个数据
表1里我们重点看R Square-测定系数
第二个表格-方差分析

回归分析df:回归分析模型的自由度,以样本来估计总体时,样本中独立或能自由变化的个数
在表二中我们中带你关注 Significance F的值它在显著性水平下的Fα临界值,即F检验的P值,代表弃真概率,F检验主要是检验因变量与自变量之间的线性关系是否显著,用线性模型来描述他们之间的关系是否恰当,越小越显著。
第三个表格

**Intercept Coefficients:**表示截距的回归值
**标准误差:**标准误差越小精度越高
**P-value:**也就是P值,用来检验回归方程系数的显著性,一般以此来衡量检验结果是否具有显著性,如果P值>0.05, 则结果不具有显著的统计学意义,如果0.01<P值<0.05,则结果具有显著的统计学意义,如果P<=0.01,则结果具有极其显著的统计学意义。
希望对大家进行数据分析有所帮助!
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









