







学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
==================================================================
为了使用 Python 和 OpenCV 执行人脸识别,我们需要安装两个额外的库:
pip install dlib
或者你可以从源代码编译:
git clone https://github.com/davisking/dlib.git
cd dlib
mkdir build
cd build
cmake … -DUSE_AVX_INSTRUCTIONS=1
cmake --build .
cd …
python setup.py install --yes USE_AVX_INSTRUCTIONS
如果安装失败可以尝试:
pip install dlib-bin
效果一样,但是这样做只有能安装CPU版本,缺点就是慢。
如果你有一个兼容 CUDA 的 GPU,你可以安装支持 GPU 的 dlib,使面部识别更快、更高效。 为此,我建议从源代码安装 dlib,因为您可以更好地控制构建:
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake … -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd …
$ python setup.py install --yes USE_AVX_INSTRUCTIONS --yes DLIB_USE_CUDA
建议用GPU版本,如果安装失败参考这篇文章:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/121470556?spm=1001.2014.3001.5501
=================================================================================
face_recognition 模块可以通过一个简单的 pip 命令安装:
pip install face_recognition
=====================================================================
您还需要我的便利功能包 imutils。 你可以通过 pip 将它安装在你的 Python 虚拟环境中:
pip install imutils
==================================================================
数据集来源网络搜索,我选取了几名大家认识的人物,有Biden、chenglong、mayun、Trump、yangmi、zhaoliying等。每个人物放入3-4张图片,如下图:
获得此图像数据集,我们将:
-
为数据集中的每个人脸创建 128 维嵌入
-
使用这些嵌入来识别图像和视频流中人物的面部
制作数据集的方法:
===================================================================
myface
├── dataset
├─dataset
│ ├─Biden
│ ├─chenglong
│ ├─mayun
│ ├─Trump
│ ├─yangmi
│ └─zhaoliying
├── encode_faces.py
├── recognize_faces_image.py
├── recognize_faces_video.py
└── encodings.pickle
我们的项目有 4 个顶级目录:
-
dataset/ :包含六个字符的面部图像,根据它们各自的名称组织到子目录中。 。
-
output/ :这是您可以存储处理过的人脸识别视频的地方。 我要把我的一个留在文件夹里——原侏罗纪公园电影中的经典“午餐场景”。
-
videos/ :输入视频应存储在此文件夹中。 该文件夹还包含“午餐场景”视频,但尚未经过我们的人脸识别系统。
我们在根目录下还有 6 个文件:
-
encode_faces.py :人脸的编码(128 维向量)是用这个脚本构建的。
-
identify_faces_image.py :识别单个图像中的人脸(基于数据集中的编码)。
-
identify_faces_video.py :识别来自网络摄像头的实时视频流中的人脸并输出视频。
-
encodings.pickle :面部识别编码通过 encode_faces.py 从您的数据集生成,然后序列化到磁盘。
创建图像数据集后(使用 search_bing_api.py ),我们将运行 encode_faces.py 来构建嵌入。 然后,我们将运行识别脚本来实际识别人脸。
=================================================================================
在识别图像和视频中的人脸之前,我们首先需要量化训练集中的人脸。 请记住,我们实际上并不是在这里训练网络——网络已经被训练为在大约 300 万张图像的数据集上创建 128 维嵌入。
当然可以从头开始训练网络,甚至可以微调现有模型的权重。一般情况。
使用预训练网络然后使用它为我们数据集中的 29张人脸中的每一张构建 128 维嵌入更容易。
然后,在分类过程中,我们可以使用一个简单的 k-NN 模型 + 投票来进行最终的人脸分类。 其他传统的机器学习模型也可以在这里使用。 要构建我们的人脸嵌入,
请新建 encode_faces.py:
import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
dataset_path=‘dataset’
encodings_path=‘encodings.pickle’
detection_method=‘cnn’
获取数据集中输入图像的路径
print(“[INFO] quantifying faces…”)
imagePaths = list(paths.list_images(dataset_path))
初始化已知编码和已知名称的列表
knownEncodings = []
knownNames = []
遍历图像路径
for (i, imagePath) in enumerate(imagePaths):
从图片路径中提取人名
print(“[INFO] processing image {}/{}”.format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
加载输入图像并从 BGR 转换(OpenCV 排序)
到 dlib 排序(RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
检测边界框的 (x, y) 坐标
对应输入图像中的每个人脸
boxes = face_recognition.face_locations(rgb, model=detection_method)
计算人脸的嵌入
encodings = face_recognition.face_encodings(rgb, boxes)
遍历 encodings
for encoding in encodings:
将每个编码 + 名称添加到我们的已知名称集中
编码
knownEncodings.append(encoding)
knownNames.append(name)
导入包,定义全局变量
变量的含义:
-
dataset_path:数据集的路径。
-
encodings_path :我们的人脸编码被写入这个参数指向的文件路径。
-
detection_method :在我们对图像中的人脸进行编码之前,我们首先需要检测它们。 或者两种人脸检测方法包括 hog 或 cnn 。
现在我们已经定义了我们的参数,让我们获取数据集中文件的路径(以及执行两个初始化):
输入数据集目录的路径来构建其中包含的所有图像路径的列表。
在循环之前分别初始化两个列表 knownEncodings 和 knownNames 。 这两个列表将包含数据集中每个人的面部编码和相应的姓名。
这个循环将循环 19次,对应于我们在数据集中的 19张人脸图像。
遍历每个图像的路径。从 imagePath中提取人名。 然后让我们加载图像,同时将 imagePath 传递给 cv2.imread。 OpenCV 使用BGR 颜色通道,但 dlib 实际上期望 RGB。 face_recognition 模块使用 dlib ,交换颜色空间。 接下来,让我们定位人脸并计算编码:
对于循环的每次迭代,我们将检测一张脸,查找/定位了她的面孔,从而生成了面孔框列表。 我们将两个参数传递给 face_recognition.face_locations 方法:
-
rgb :我们的 RGB 图像。
-
model:cnn 或 hog(该值包含在与“detection_method”键关联的命令行参数字典中)。 CNN方法更准确但速度更慢。 HOG 速度更快,但准确度较低。
然后,将面部的边界框转换为 128 个数字的列表。这称为将面部编码为向量,而 face_recognition.face_encodings 方法会处理它。 编码和名称附加到适当的列表(knownEncodings 和 knownNames)。然后,将继续对数据集中的所有 19张图像执行此操作。
dump the facial encodings + names to disk
print(“[INFO] serializing encodings…”)
data = {“encodings”: knownEncodings, “names”: knownNames}
f = open(args[“encodings”], “wb”)
f.write(pickle.dumps(data))
f.close()
构造了一个带有两个键的字典—— “encodings” 和 “names” 。
将名称和编码转储到磁盘以备将来调用。运行encode_faces.py
D:\ProgramData\Anaconda3\python.exe D:/cv/myface/encode_faces.py
[INFO] quantifying faces…
[INFO] processing image 1/19
[INFO] processing image 2/19
[INFO] processing image 3/19
[INFO] processing image 4/19
[INFO] processing image 5/19
[INFO] processing image 6/19
[INFO] processing image 7/19
[INFO] processing image 8/19
[INFO] processing image 9/19
[INFO] processing image 10/19
[INFO] processing image 11/19
[INFO] processing image 12/19
[INFO] processing image 13/19
[INFO] processing image 14/19
[INFO] processing image 15/19
[INFO] processing image 16/19
[INFO] processing image 17/19
[INFO] processing image 18/19
[INFO] processing image 19/19
[INFO] serializing encodings…
Process finished with exit code 0
正如输出中看到的,我们现在有一个名为 encodings.pickle 的文件——该文件包含我们数据集中每个人脸的 128 维人脸嵌入。
===================================================================
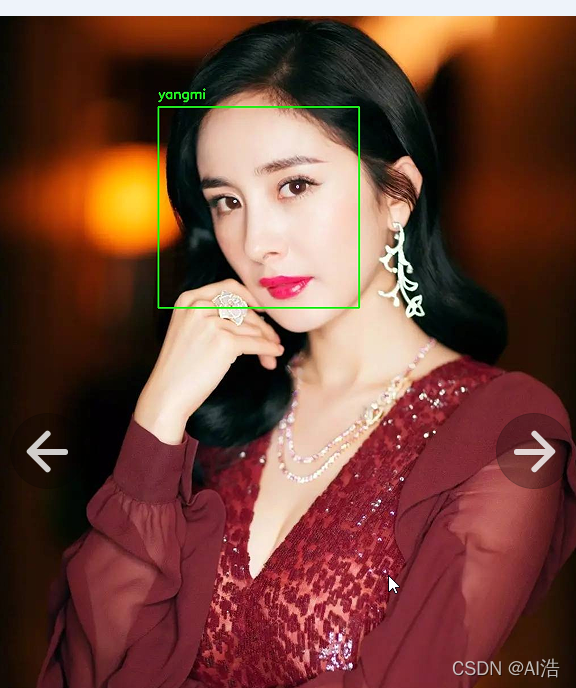
现在我们已经为数据集中的每个图像创建了 128 维人脸嵌入,现在我们可以使用 OpenCV、Python 和深度学习来识别图像中的人脸。 打开recognize_faces_image.py 并插入以下代码:
import face_recognition
import pickle
import cv2
encodings_path=‘encodings.pickle’
image_path=‘11.jpg’
detection_method=‘cnn’
load the known faces and embeddings
print(“[INFO] loading encodings…”)
data = pickle.loads(open(encodings_path, “rb”).read())
加载输入图像并将其从 BGR 转换为 RGB
image = cv2.imread(image_path)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
检测输入图像中每个人脸对应的边界框的 (x, y) 坐标,然后计算每个人脸的面部嵌入
print(“[INFO] recognizing faces…”)
boxes = face_recognition.face_locations(rgb,model=detection_method)
encodings = face_recognition.face_encodings(rgb, boxes)
初始化检测到的每个人脸的名字列表
names = []
循环面部嵌入
for encoding in encodings:
尝试将输入图像中的每个人脸与我们已知的编码相匹配
matches = face_recognition.compare_faces(data[“encodings”],encoding)
name = “Unknown”
检查是否有匹配的
if True in matches:
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









