







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
res = urllib.request.urlopen(req)
print(res.getcode()) # 得到响应码,200表示请求成功
html = res.read().decode(‘utf-8’)
print(type(html)) # <class ‘str’>,得到的是json数据
json数据转字典
dic = json.loads(html)
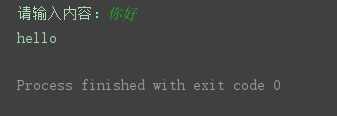
result = dic[“translateResult”] # [[{‘src’: ‘你好’, ‘tgt’: ‘hello’}]]
print(result[0][0][‘tgt’])
另一个简单的示例:
import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
url = ‘https://www.httpbin.org/post’ # post请求测试地址
将表单数据转换为bytes类型,并设置编码方式为utf-8
print()
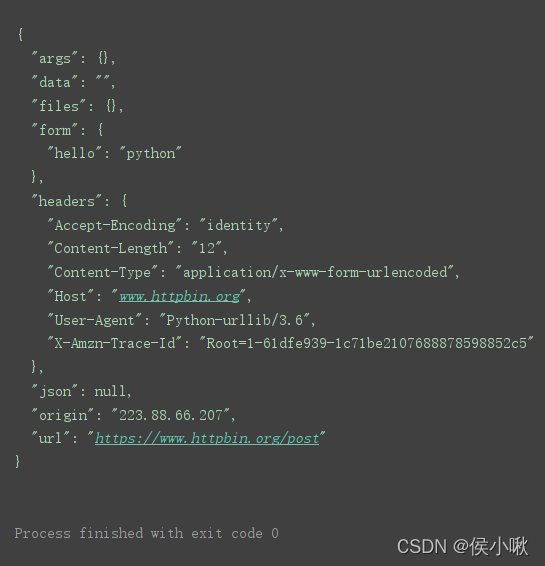
data = bytes(urllib.parse.urlencode({‘hello’: ‘python’}), encoding=‘utf-8’)
response = urllib.request.urlopen(url=url, data=data) # 发送网络请求
print(response.read().decode(‘utf-8’)) # 读取HTML代码并进行
================================================================================
urlopen()的timeout参数用于设置请求超时,该参数以秒为单位,表示如果在请求时超出了设置的时间还没有得到响应时就会抛出异常。
import urllib.request
url = ‘https://www.python.org/’
response = urllib.request.urlopen(url=url, timeout=0.1) # 设置超时时间为0.1秒
print(response.read().decode(‘utf-8’))
因为0.1秒设置的过快,结果因超时而产生异常,报错。
通常根据网络环境不同,设置一个合理的时间,如2秒,3秒。
对该网络超时异常进行捕捉并处理:
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
import socket # 导入socket模块
url = ‘https://www.python.org/’ # 请求地址
try:
发送网络请求,设置超时时间为0.1秒
response = urllib.request.urlopen(url=url, timeout=0.1)
print(response.read().decode(‘utf-8’)) # 读取HTML代码并进行utf-8解码
except urllib.error.URLError as error: # 处理异常
if isinstance(error.reason, socket.timeout): # 判断异常是否为超时异常
print(‘当前任务已超时,即将执行下一任务!’)

6. 复杂网络请求_urllib.request.Request()
==========================================================================================================
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
参数说明:
-
url:访问网站的完整url地址
-
data:默认为None,表示请求方式为get请求;如果需要实现post请求,需要字典形式的数据作为参数。
-
headers:设置请求头部信息,字典类型。
-
origin_req_host:用于设置请求方的host名称或者IP。
-
unverifiable:用于设置网页是否需要验证,默认值为False。
-
method:用于设置请求方式,如GET,POST。
=============================================================================
url = ‘https://www.baidu.com’
定义请求头信息
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36’}
创建Request对象
r = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen® # 发送网络请求
print(response.read().decode(‘utf-8’)) # 读取HTML代码并进行utf-8解码
import urllib.request # 导入urllib.request模块
import urllib.parse # 导入urllib.parse模块
url = ‘https://www.httpbin.org/post’ # 请求地址
定义请求头信息
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36’}
将表单数据转换为bytes类型,并设置编码方式为utf-8
data = bytes(urllib.parse.urlencode({‘hello’: ‘python’}),encoding=‘utf-8’)
创建Request对象
r = urllib.request.Request(url=url,data=data,headers=headers,method=‘POST’)
response = urllib.request.urlopen® # 发送网络请求
print(response.read().decode(‘utf-8’)) # 读取HTML代码并进行utf-8解码
创建出一个Request对象,然后直接调用urlopen()函数。
创建Request也被称为创建请求对象。

=======================================================================================
Cookies是服务器向客户端返回响应数据时所留下的标记。当客户再次访问服务器时会携带这个标记。一般登录一个页面成功后,会在浏览器的cookie中保留一些信息,再次访问时服务器核对后即可确认当前用户登录过,此时可直接将登录后的数据返回。
import urllib.request
url = “https://www.csdn.net/”
opener = urllib.request.build_opener() # 获取opener对象
resp = opener.open(url)
print(resp.read().decode())
因为urlopen()方法不支持代理、cookie等其他的HTTP/GTTPS高级功能,所以这里不用urlopen()发送请求,而需要创建一个opener对象(这本来是urllib2中的方法)。示例如下。学习过程中这里作为了解即可,建议重点研究/使用requests库。
import urllib.request # 导入urllib.request模块
import http.cookiejar # 导入http.cookiejar子模块
登录后页面的请求地址
url = ‘xxx’
cookie_file = ‘cookie.txt’ # cookie文件
cookie = http.cookiejar.LWPCookieJar() # 创建LWPCookieJar对象
读取cookie文件内容
cookie.load(cookie_file,ignore_expires=True,ignore_discard=True)
生成cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
创建opener对象
opener = urllib.request.build_opener(handler)
response = opener.open(url) # 发送网络请求
print(response.read().decode(‘utf-8’)) # 打印登录后页面的html代码
==============================================================================
import urllib.request # 导入urllib.request模块
url= ‘xxxxxxxxxxxxxxx’
创建代理IP
proxy_handler = urllib.request.ProxyHandler({
‘https’: ‘xxxxxxxxxxxxxxxxx’ # 写入代理IP
})
创建opener对象
opener = urllib.request.build_opener(proxy_handler)
response = opener.open(url,timeout=2)
print(response.read().decode(‘utf-8’))
=============================================================================
urllib模块中的urllib.error子模块包含了URLError与HTTPError两个比较重要的异常类。
URLError类提供了一个reason属性,可以通过这个属性了解错误的原因。示例如下:
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
向不存在的网络地址发送请求
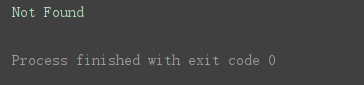
response = urllib.request.urlopen(‘https://www.python.org/1111111111.html’)
except urllib.error.URLError as error: # 捕获异常信息
print(error.reason) # 打印异常原因
程序运行结果:
HTTPError类是URLError的子类,主要用于处理HTTP请求所出现的一次。此类有以下三个属性。
-
code :返回HTTP状态码
-
reason 返回错误原因
-
headers 返回请求头
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
向不存在的网络地址发送请求
response = urllib.request.urlopen(‘https://www.python.org/1111111111.html’)
print(response.status)
except urllib.error.HTTPError as error: # 捕获异常信息
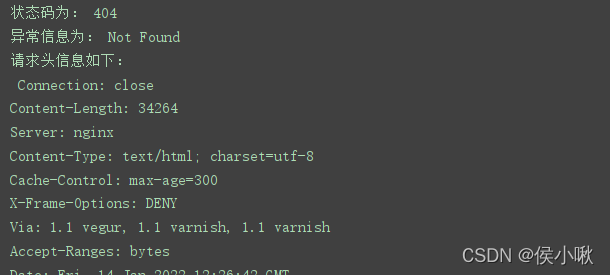
print(‘状态码为:’,error.code) # 打印状态码
print(‘异常信息为:’,error.reason) # 打印异常原因
print(‘请求头信息如下:\n’,error.headers) # 打印请求头
结果如下(部分):
因为URLError是HTTPError的父类,所以在捕获异常的时候可以先找子类是否异常,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常。
URLError产生的原因主要是
-
- 网络没有连接,
-
- 服务器连接失
-
- 找不到指定的服务器。
当使用urlopen或 opener.open 不能处理的,服务器上都对应一个响应对象,其中包含一个数字(状态码),如果urlopen不能处理,urlopen会产生一个相应的HTTPError对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态码。
import urllib.request # 导入urllib.request模块
import urllib.error # 导入urllib.error模块
try:
response = urllib.request.urlopen(‘https://www.python.org/’,timeout=0.1)
except urllib.error.HTTPError as error: # HTTPError捕获异常信息
print(‘状态码为:’,error.code) # 打印状态码
print(‘HTTPError异常信息为:’,error.reason) # 打印异常原因
print(‘请求头信息如下:\n’,error.headers) # 打印请求头
except urllib.error.URLError as error: # URLError捕获异常信息
print(‘URLError异常信息为:’,error.reason)
这里访问了一个真实存在的URL,输出结果为:

==============================================================================
urllin模块提供了parse子模块用来解析URL。
urlparse()方法
parse子模块提供了urlparse()方法,实现将URL分解成不同部分,语法格式如下:
urllib.parse.urlparse(urlstring,scheme=’’,allow_fragment=True)
-
urlstring:需要拆分的URL,必选参数。
-
scheme:可选参数,需要设置的默认协议,默认为空字符串,如果要拆分的URL中没有协议,可通过该参数设置一个默认协议。
-
allow_fragment:可选参数,如果该参数设置为False,则表示忽略fragment这部分内容,默认为True。
示例:
import urllib.parse #导入urllib.parse模块
parse_result = urllib.parse.urlparse(‘https://docs.python.org/3/library/urllib.parse.html’)
print(type(parse_result)) # 打印类型
print(parse_result) # 打印拆分后的结果
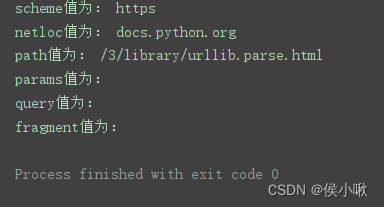
程序运行结果:

用此方法,除了返回ParseResult对象以外,还可以直接获取ParseResult对象中的每个属性值:
print(‘scheme值为:’, parse_result.scheme)
print(‘netloc值为:’, parse_result.netloc)
print(‘path值为:’, parse_result.path)
print(‘params值为:’, parse_result.params)
print(‘query值为:’, parse_result.query)
print(‘fragment值为:’, parse_result.fragment)
urlsplit()方法
urlsplit()方法与urlparse()方法类似,都可以实现URL的拆分。只是urlsplit()方法不再单独拆分params这部分内容,而是将params合并到path中,所以返回结果只有5部分内容。且返回的数据类型为SplitResult。
import urllib.parse #导入urllib.parse模块
需要拆分的URL
url = ‘https://docs.python.org/3/library/urllib.parse.html’
print(urllib.parse.urlsplit(url)) # 使用urlsplit()方法拆分URL
print(urllib.parse.urlparse(url)) # 使用urlparse()方法拆分URL
程序运行结果:

urlunparse()方法
urlunparse()方法实现URL的组合
语法:urlunparse(parts)
parts表示用于组合url的可迭代对象
import urllib.parse #导入urllib.parse模块
list_url = [‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’, ‘’]
tuple_url = (‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’, ‘’)
dict_url = {‘scheme’: ‘https’, ‘netloc’: ‘docs.python.org’, ‘path’: ‘/3/library/urllib.parse.html’, ‘params’: ‘’, ‘query’:‘’, ‘fragment’: ‘’}
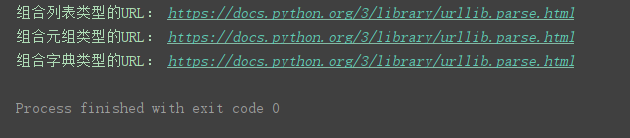
print(‘组合列表类型的URL:’, urllib.parse.urlunparse(list_url))
print(‘组合元组类型的URL:’, urllib.parse.urlunparse(tuple_url))
print(‘组合字典类型的URL:’, urllib.parse.urlunparse(dict_url.values()))
程序运行结果:
urlunsplit()方法
同样用于URL组合,只是参数中的元素必须是5个。
import urllib.parse #导入urllib.parse模块
list_url = [‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’]
tuple_url = (‘https’, ‘docs.python.org’, ‘/3/library/urllib.parse.html’, ‘’, ‘’)
dict_url = {‘scheme’: ‘https’, ‘netloc’: ‘docs.python.org’, ‘path’: ‘/3/library/urllib.parse.html’, ‘query’: ‘’, ‘fragment’: ‘’}
print(‘组合列表类型的URL:’, urllib.parse.urlunsplit(list_url))
print(‘组合元组类型的URL:’, urllib.parse.urlunsplit(tuple_url))
print(‘组合字典类型的URL:’, urllib.parse.urlunsplit(dict_url.values()))

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1054
1054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









