








此时再打开刚才的网址

是不是清晰了很多呢?
如果用python来获取里面的数据怎么做的?
先利用 json.loads() 来将 Json 转成字典,再用 get() 函数直到得到我们想要的list 对象,那么对于 list 里面的数据我们用个 for 循环就行啦~
额,有点绕。

还是文章一开始的例子,我们想获取其中所有狗狗的名字:
{
“animals”: {
“dog”: [
{
“name”: “Rufus”,
“age”:15
},
{
“name”: “Marty”,
“age”: null
}
]
}
}
我们可以这样做:
load_data = json.loads(dump_data)
data = load_data.get(“animals”).get(“dog”)
result1 = []
for i in data:
result1.append(i.get(“name”))
print(result1)
运行结果:
[‘Rufus’, ‘Marty’]
这样确实可以获得我们想要的结果。
PS:类似的在线解析网站也有很多
不知道大家还记不记得,在一开始介绍Json时,我提到了它相对于XML来说,更加的轻量级,更方便解析。
既然 XML 人家都有 XPATH ,那么Json有没有类似的工具呢?

JsonPath 是一种信息抽取类库,是从Json文档中抽取指定信息的工具。
JsonPath 对于 Json 来说,相当于 XPATH 对于 XML。
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表是JsonPath的用法。


没错,还是这个例子,我们这次尝试用JsonPath获取其中所有狗狗的名字:
{
“animals”: {
“dog”: [
{
“name”: “Rufus”,
“age”:15
},
{
“name”: “Marty”,
“age”: null
}
]
}
}
我们可以这样做:
load_data = json.loads(dump_data)
jobs=load_data[‘animals’][‘dog’]
result2 = []
for i in data:
从根节点开始,匹配name节点
result2.append(jsonpath.jsonpath(i,‘$…name’)[0])
print(result2)
其中 $…name 代表从根节点开始,匹配name节点
运行结果:
[‘Rufus’, ‘Marty’]
利用 JsonPath 同样可以获得我们想要的结果。
我们在后续实例演练中将继续采用 JsonPath 来抽取数据。
示例:我们利用网易云音乐评论API来生成Json数据,并从中获取热评数据。
http://music.163.com/api/v1/resource/comments/R_SO_4_483671599?limit=10&offset=0
在浏览器(已安装Json解析插件)中打开:
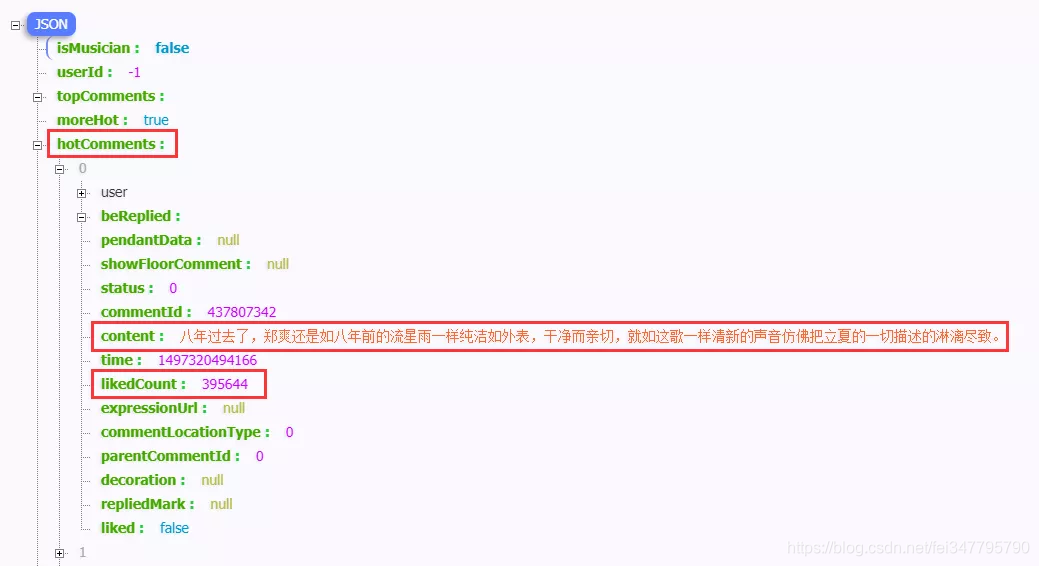

标红区域的数据是我们本次想要获取的。

import requests
import jsonpath
import pandas as pd
import time
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36’}
def get_json(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
json_text=response.json()
return json_text
except Exception:
print(‘此页有问题!’)
return None
def stampToTime(stamp): #时间转换
datatime = time.strftime(“%Y-%m-%d %H:%M:%S”,time.localtime(float(str(stamp)[0:10])))
datatime = datatime+‘.’+str(stamp)[10:]
return datatime
def get_comments(url):
data = []
doc = get_json(url)
jobs=doc[‘hotComments’]
for job in jobs:
dic = {}
#从根节点开始,匹配content节点
dic[‘content’]=jsonpath.jsonpath(job,‘$…content’)[0] #评论
dic[‘time’]= stampToTime(jsonpath.jsonpath(job,‘$…time’)[0]) #时间
dic[‘userId’]=jsonpath.jsonpath(job[‘user’],‘$…userId’)[0] #用户ID
dic[‘nickname’]=jsonpath.jsonpath(job[‘user’],‘$…nickname’)[0]#用户名
dic[‘likedCount’]=jsonpath.jsonpath(job,‘$…likedCount’)[0] #赞数
data.append(dic)
return pd.DataFrame(data)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









