







最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
===============================================================
onnx模型转换和推理需要安装Python包,如下:
pip install onnx
pip install onnxruntime-gpu
新建模型转换脚本pytorch2onnx.py。
import torch
from torch.autograd import Variable
import onnx
import netron
print(torch.version)
input_name = [‘input’]
output_name = [‘output’]
input = Variable(torch.randn(1, 3, 224, 224)).cuda()
model = torch.load(‘model.pth’, map_location=“cuda:0”)
torch.onnx.export(model, input, ‘model_onnx.onnx’,opset_version=13, input_names=input_name, output_names=output_name, verbose=True)
模型可视化
netron.start(‘model_onnx.onnx’)
导入需要的包。
打印pytorch版本。
定义input_name和output_name变量。
定义输入格式。
加载pytorch模型。
导出onnx模型,这里注意一下参数opset_version在8.X版本中设置为13,在7.X版本中设置为12。
yolov5中这么写的。
if trt.version[0] == ‘7’: # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
grid = model.model[-1].anchor_grid
model.model[-1].anchor_grid = [a[…, :1, :1, :] for a in grid]
export_onnx(model, im, file, 12, train, False, simplify) # opset 12
model.model[-1].anchor_grid = grid
else: # TensorRT >= 8
check_version(trt.version, ‘8.0.0’, hard=True) # require tensorrt>=8.0.0
export_onnx(model, im, file, 13, train, False, simplify) # opset 13
查看转化后的模型,如下图:
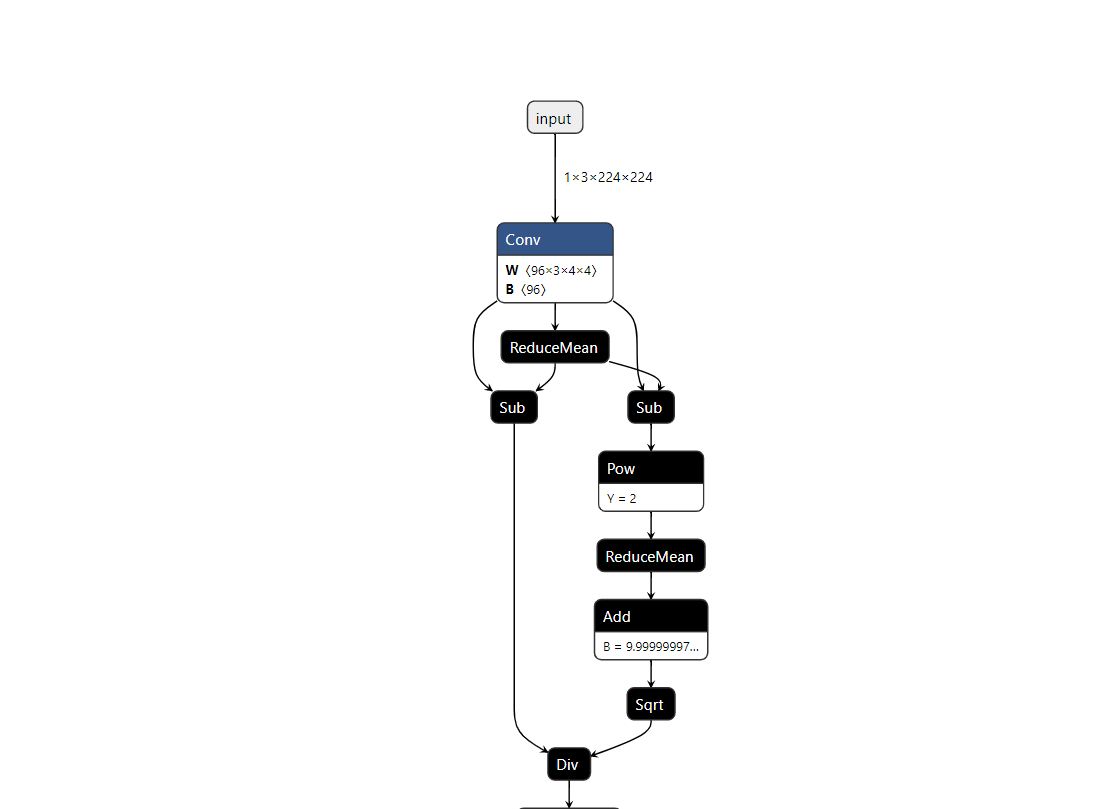
推理的写法有两种,一种直接写,另一种将其封装为通用的推理类。
先看第一种写法,新建test_onnx.py,插入下面的代码:
import os, sys
import time
sys.path.append(os.getcwd())
import onnxruntime
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
导入包
def get_test_transform():
return transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open(‘11.jpg’) # 289
img = get_test_transform()(image)
img = img.unsqueeze_(0) # -> NCHW, 1,3,224,224
print(“input img mean {} and std {}”.format(img.mean(), img.std()))
img = np.array(img)
定义get_test_transform函数,实现图像的归一化和resize。
读取图像。
对图像做resize和归一化。
增加一维batchsize。
将图片转为数组。
onnx_model_path = “model_onnx.onnx”
##onnx测试
session = onnxruntime.InferenceSession(onnx_model_path,providers=[‘TensorrtExecutionProvider’, ‘CUDAExecutionProvider’, ‘CPUExecutionProvider’])
#compute ONNX Runtime output prediction
inputs = {session.get_inputs()[0].name: img}
time3=time.time()
outs = session.run(None, inputs)[0]
y_pred_binary = np.argmax(outs, axis=1)
print(“onnx prediction”, y_pred_binary[0])
time4=time.time()
print(time4-time3)
定义onnx_model_path模型的路径。
加载onnx模型。
定义输入。
执行推理。
获取预测结果。
到这里第一种写法就完成了,是不是很简单,接下来看第二种写法。
新建onnx.py脚本,加入以下代码:
import onnxruntime
class ONNXModel():
def init(self, onnx_path):
“”"
:param onnx_path:
“”"
self.onnx_session = onnxruntime.InferenceSession(onnx_path,providers=[‘TensorrtExecutionProvider’, ‘CUDAExecutionProvider’, ‘CPUExecutionProvider’])
self.input_name = self.get_input_name(self.onnx_session)
self.output_name = self.get_output_name(self.onnx_session)
print(“input_name:{}”.format(self.input_name))
print(“output_name:{}”.format(self.output_name))
def get_output_name(self, onnx_session):
“”"
output_name = onnx_session.get_outputs()[0].name
:param onnx_session:
:return:
“”"
output_name = []
for node in onnx_session.get_outputs():
output_name.append(node.name)
return output_name
def get_input_name(self, onnx_session):
“”"
input_name = onnx_session.get_inputs()[0].name
:param onnx_session:
:return:
“”"
input_name = []
for node in onnx_session.get_inputs():
input_name.append(node.name)
return input_name
def get_input_feed(self, input_name, image_numpy):
“”"
input_feed={self.input_name: image_numpy}
:param input_name:
:param image_numpy:
:return:
“”"
input_feed = {}
for name in input_name:
input_feed[name] = image_numpy
return input_feed
def forward(self, image_numpy):
输入数据的类型必须与模型一致,以下三种写法都是可以的
scores, boxes = self.onnx_session.run(None, {self.input_name: image_numpy})
scores, boxes = self.onnx_session.run(self.output_name, input_feed={self.input_name: iimage_numpy})
input_feed = self.get_input_feed(self.input_name, image_numpy)
scores = self.onnx_session.run(self.output_name, input_feed=input_feed)
return scores
调用onnx.py实现推理,新建test_onnx1.py插入代码:
import os, sys
sys.path.append(os.getcwd())
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
from models.onnx import ONNXModel
def get_test_transform():
return transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open(‘11.jpg’) # 289
img = get_test_transform()(image)
img = img.unsqueeze_(0) # -> NCHW, 1,3,224,224
print(“input img mean {} and std {}”.format(img.mean(), img.std()))
img = np.array(img)
onnx_model_path = “model_onnx.onnx”
model1 = ONNXModel(onnx_model_path)
out = model1.forward(img)
y_pred_binary = np.argmax(out[0], axis=1)
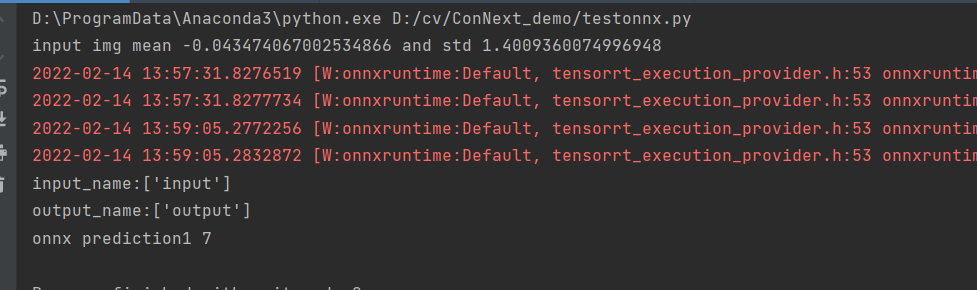
print(“onnx prediction1”, y_pred_binary[0])
输出结果如下:
===================================================================
TensorRT是英伟达推出的一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。
TensorRT的安装可以参考我以前的文章:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/120360288。
本次用的8.X版本的,安装方式一样。
本文实现Python版本的 TensorRT 推理加速,需要安装tensorrt包文件。这个文件不能直接通过pip下载,我在下载的TensorRT安装包里,不过我下载的8.0.3.4版本中并没有,在8.2.1.8的版本中存在这个包文件。
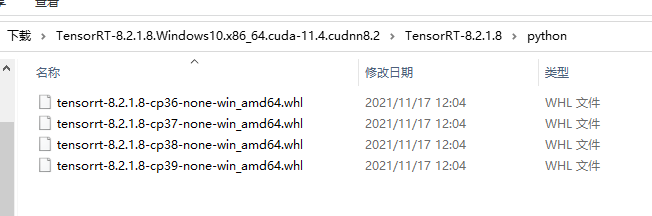
所以我安装了8.2.1.8中的whl文件。
安装方式,进入模型所在的目录,执行:
pip install tensorrt-8.2.1.8-cp39-none-win_amd64.whl
模型推理用到了pycuda,执行安装命令:
pip install pycuda
将onnx模型转为TensorRT 模型,新建onnx2trt.py,插入代码:
import tensorrt as trt
def build_engine(onnx_file_path,engine_file_path,half=False):
“”“Takes an ONNX file and creates a TensorRT engine to run inference with”“”
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = 4 * 1 << 30
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(str(onnx_file_path)):
raise RuntimeError(f’failed to load ONNX file: {onnx_file_path}')
half &= builder.platform_has_fast_fp16
if half:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(engine_file_path, ‘wb’) as t:
t.write(engine.serialize())
return engine_file_path
if name ==“main”:
onnx_path1 = ‘model_onnx.onnx’
engine_path = ‘model_trt.engine’
build_engine(onnx_path1,engine_path,True)
build_engine函数共有三个参数:
onnx_file_path:onnx模型的路径。
engine_file_path:TensorRT模型的路径。
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









