







(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-
- Python的自动化办公库技术点案例示例系列
- 博文目录
-
- 前言
- 一、主要特点和功能介绍
- 二、Series 示例代码
- 三、DataFrame示例代码
- 四、数据导入/导出示例代码
- 五、数据清洗示例代码
- 六、数据选择和过滤示例代码
- 七、数据合并和连接示例代码
- 八、数据分组和聚合示例代码
- 九、数据转换示例代码
- 十、时间序列数据处理示例代码
- 十一、高效处理大型数据集示例代码
- 十二、支持向量化操作示例代码
- 十三、数据分析和可视化示例代码
- 十四、社区支持举例说明
- 十五、归纳总结
- 前言
系列博文目录
Python的自动化办公库技术点案例示例系列
博文目录
前言

 Pandas是一个流行的Python数据处理库,提供了易于使用的数据结构和数据分析工具,使得在Python中进行数据清洗、数据分析和数据处理变得更加简单和高效。
Pandas是一个流行的Python数据处理库,提供了易于使用的数据结构和数据分析工具,使得在Python中进行数据清洗、数据分析和数据处理变得更加简单和高效。
一、主要特点和功能介绍

 以下是Pandas的一些主要特点和功能:
以下是Pandas的一些主要特点和功能:
- 数据结构:
-Series:类似于一维数组,可以存储不同类型的数据,并带有标签(索引)。
-DataFrame:类似于二维表格,由多个Series组成,每列可以是不同的数据类型。 - 数据操作:
-数据导入/导出:Pandas支持从各种数据源中导入数据,如CSV文件、Excel表格、数据库等,并可以将处理后的数据导出。
-数据清洗:处理缺失数据、重复数据、异常值等。
-数据选择和过滤:通过标签或位置选择数据,进行数据筛选和过滤。
-数据合并和连接:合并多个数据集,支持不同类型的连接操作。
-数据分组和聚合:按照指定的条件对数据进行分组,并进行聚合操作,如求和、平均值等。
-数据转换:对数据进行排序、重塑、透视等操作。
-时间序列数据处理:提供了强大的时间序列数据处理功能。 - 性能优势:
-Pandas基于NumPy构建,能够高效处理大型数据集。
-支持向量化操作,避免了使用显式循环,提高了数据处理的效率。 - 灵活性:
-可以与其他Python库(如NumPy、Matplotlib等)结合使用,实现更复杂的数据分析和可视化任务。 - 社区支持:
-Pandas拥有庞大的社区支持和活跃的开发者社区,提供了丰富的文档、教程和示例,便于学习和使用。
总的来说,Pandas是一个功能强大且灵活的数据处理工具,适用于各种数据分析和数据处理任务。如果你需要进行数据清洗、数据分析或数据处理,Pandas通常是一个很好的选择。
二、Series 示例代码

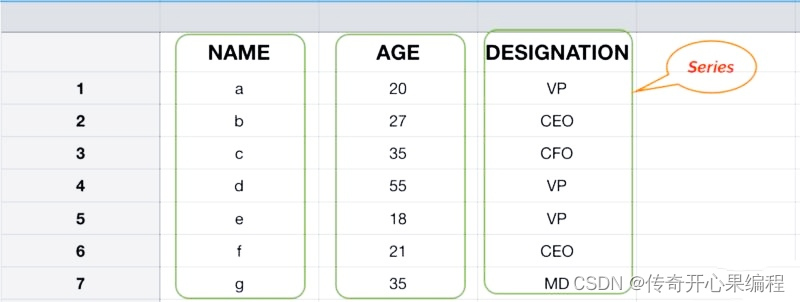 当创建一个Pandas Series 对象时,你可以传入一个包含数据的列表或数组,并可以选择性地指定索引。以下是一个简单的示例代码,演示如何创建一个包含不同类型数据并具有标签索引的 Pandas Series:
当创建一个Pandas Series 对象时,你可以传入一个包含数据的列表或数组,并可以选择性地指定索引。以下是一个简单的示例代码,演示如何创建一个包含不同类型数据并具有标签索引的 Pandas Series:
import pandas as pd
# 创建一个包含不同类型数据的 Pandas Series
data = [10, 'Hello', 3.5, True]
index = ['A', 'B', 'C', 'D']
# 使用数据列表和索引列表创建 Series 对象
series = pd.Series(data, index=index)
# 打印 Series 对象
print(series)
在这个示例中,我们创建了一个包含整数、字符串、浮点数和布尔值的 Pandas Series,每个值都有一个对应的标签索引。运行这段代码后,你将看到类似以下输出:
A 10
B Hello
C 3.5
D True
dtype: object
这个 Series 包含了不同类型的数据,并且每个数据都与一个索引标签相关联。这使得在 Pandas 中处理数据时更加灵活和方便。
三、DataFrame示例代码
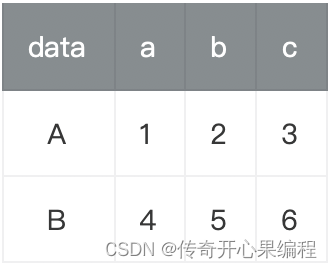 当创建一个 Pandas DataFrame 时,你可以传入一个字典,其中键是列名,值是列数据(可以是列表、数组或 Series)。以下是一个简单的示例代码,演示如何创建一个包含不同数据类型的 Pandas DataFrame,每列可以是不同的数据类型:
当创建一个 Pandas DataFrame 时,你可以传入一个字典,其中键是列名,值是列数据(可以是列表、数组或 Series)。以下是一个简单的示例代码,演示如何创建一个包含不同数据类型的 Pandas DataFrame,每列可以是不同的数据类型:
import pandas as pd
# 创建一个包含不同数据类型的 Pandas DataFrame
data = {
'A': [1, 2, 3, 4],
'B': ['apple', 'banana', 'cherry', 'date'],
'C': [2.5, 3.7, 1.2, 4.9],
'D': [True, False, True, False]
}
# 使用字典创建 DataFrame 对象
df = pd.DataFrame(data)
# 打印 DataFrame 对象
print(df)
在这个示例中,我们创建了一个包含整数、字符串、浮点数和布尔值的 Pandas DataFrame。每列的数据类型可以是不同的,这是 Pandas DataFrame 的一个重要特性。运行这段代码后,你将看到类似以下输出:
A B C D
0 1 apple 2.5 True
1 2 banana 3.7 False
2 3 cherry 1.2 True
3 4 date 4.9 False
这个 DataFrame 包含了四列数据,每列可以是不同的数据类型,类似于一个二维表格。Pandas DataFrame 提供了强大的数据操作功能,使得数据分析和处理变得更加简单和高效。
四、数据导入/导出示例代码

 Pandas 提供了丰富的功能来导入和导出数据,包括从 CSV 文件、Excel 表格、数据库等数据源中导入数据,并将处理后的数据导出到各种格式。以下是一些示例代码,演示如何使用 Pandas 进行数据导入和导出:
Pandas 提供了丰富的功能来导入和导出数据,包括从 CSV 文件、Excel 表格、数据库等数据源中导入数据,并将处理后的数据导出到各种格式。以下是一些示例代码,演示如何使用 Pandas 进行数据导入和导出:
- 从 CSV 文件导入数据并将处理后的数据导出到 CSV 文件:
import pandas as pd
# 从 CSV 文件导入数据
df = pd.read_csv('data.csv')
# 处理数据...
# 将处理后的数据导出到 CSV 文件
df.to_csv('processed\_data.csv', index=False)
- 从 Excel 表格导入数据并将处理后的数据导出到 Excel 文件:
import pandas as pd
# 从 Excel 表格导入数据
df = pd.read_excel('data.xlsx')
# 处理数据...
# 将处理后的数据导出到 Excel 文件
df.to_excel('processed\_data.xlsx', index=False)
- 从数据库导入数据并将处理后的数据导出到数据库表:
import pandas as pd
import sqlite3
# 连接到 SQLite 数据库
conn = sqlite3.connect('database.db')
# 从数据库表导入数据
query = "SELECT \* FROM table"
df = pd.read_sql_query(query, conn)
# 处理数据...
# 将处理后的数据导出到数据库表
df.to_sql('processed\_table', conn, index=False, if_exists='replace')
通过这些示例代码,你可以了解如何使用 Pandas 从不同数据源中导入数据,并在处理后将数据导出到所需的格式中。Pandas 提供了简单而强大的方法来处理各种数据导入和导出任务,使得数据分析工作更加高效和便捷。
五、数据清洗示例代码

 在数据分析中,数据清洗是一个非常重要的步骤,它包括处理缺失数据、重复数据、异常值等问题。Pandas 提供了丰富的功能来进行数据清洗。以下是一些示例代码,演示如何使用 Pandas 进行数据清洗:
在数据分析中,数据清洗是一个非常重要的步骤,它包括处理缺失数据、重复数据、异常值等问题。Pandas 提供了丰富的功能来进行数据清洗。以下是一些示例代码,演示如何使用 Pandas 进行数据清洗:
- 处理缺失数据:
import pandas as pd
# 创建包含缺失数据的示例 DataFrame
data = {
'A': [1, 2, None, 4],
'B': ['apple', 'banana', 'cherry', None],
'C': [2.5, None, 1.2, 4.9]
}
df = pd.DataFrame(data)
# 检查缺失数据
print(df.isnull())
# 填充缺失数据
df.fillna(0, inplace=True)
- 处理重复数据:
import pandas as pd
# 创建包含重复数据的示例 DataFrame
data = {
'A': [1, 2, 2, 4],
'B': ['apple', 'banana', 'banana', 'date']
}
df = pd.DataFrame(data)
# 检查重复数据
print(df.duplicated())
# 删除重复数据
df.drop_duplicates(inplace=True)
- 处理异常值:
import pandas as pd
# 创建包含异常值的示例 DataFrame
data = {
'A': [1, 2, 3, 100],
'B': ['apple', 'banana', 'cherry', 'date']
}
df = pd.DataFrame(data)
# 检查异常值
print(df[df['A'] > 10])
# 替换异常值
df.loc[df['A'] > 10, 'A'] = 10
通过这些示例代码,你可以了解如何使用 Pandas 处理缺失数据、重复数据和异常值。数据清洗是数据分析过程中的关键步骤,有效的数据清洗可以提高数据分析的准确性和可靠性。
六、数据选择和过滤示例代码
 在 Pandas 中,你可以通过标签或位置选择数据,进行数据筛选和过滤。以下是一些示例代码,演示如何使用 Pandas 进行数据选择和过滤:
在 Pandas 中,你可以通过标签或位置选择数据,进行数据筛选和过滤。以下是一些示例代码,演示如何使用 Pandas 进行数据选择和过滤:
- 通过标签选择数据:
import pandas as pd
# 创建示例 DataFrame
data = {
'A': [1, 2, 3, 4, 5],
'B': ['apple', 'banana', 'cherry', 'date', 'elderberry']
}
df = pd.DataFrame(data, index=['X', 'Y', 'Z', 'W', 'V'])
# 通过标签选择单列数据
column_data = df['A']
# 通过标签选择多列数据
multiple_columns_data = df[['A', 'B']]
# 通过标签选择单行数据
row_data = df.loc['Z']
# 通过标签选择多行数据
multiple_rows_data = df.loc[['X', 'Y']]
- 通过位置选择数据:
import pandas as pd
# 创建示例 DataFrame
data = {
'A': [1, 2, 3, 4, 5],
'B': ['apple', 'banana', 'cherry', 'date', 'elderberry']
}
df = pd.DataFrame(data)
# 通过位置选择单列数据
column_data = df.iloc[:, 0]
# 通过位置选择多列数据
multiple_columns_data = df.iloc[:, [0, 1]]
# 通过位置选择单行数据
row_data = df.iloc[2]
# 通过位置选择多行数据
multiple_rows_data = df.iloc[[0, 1]]
通过这些示例代码,你可以了解如何使用 Pandas 通过标签或位置选择数据,进行数据筛选和过滤。Pandas 提供了灵活的方法来选择和操作数据,使得数据分析工作更加高效和便捷。
七、数据合并和连接示例代码
 在 Pandas 中,你可以使用不同类型的连接操作来合并多个数据集。以下是一些示例代码,演示如何使用 Pandas 进行数据合并和连接:
在 Pandas 中,你可以使用不同类型的连接操作来合并多个数据集。以下是一些示例代码,演示如何使用 Pandas 进行数据合并和连接:
- 使用
pd.concat()进行数据合并:
import pandas as pd
# 创建示例 DataFrame
data1 = {
'A': [1, 2, 3],
'B': ['apple', 'banana', 'cherry']
}
data2 = {
'A': [4, 5, 6],
'B': ['date', 'elderberry', 'fig']
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 沿行方向合并两个 DataFrame
result = pd.concat([df1, df2])
- 使用
pd.merge()进行数据连接:
import pandas as pd
# 创建示例 DataFrame
data1 = {
'key': ['K0', 'K1', 'K2'],
'A': [1, 2, 3]
}
data2 = {
'key': ['K0', 'K1', 'K3'],
'B': ['apple', 'banana', 'cherry']
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 内连接
result_inner = pd.merge(df1, df2, on='key', how='inner')
# 左连接
result_left = pd.merge(df1, df2, on='key', how='left')
# 右连接
result_right = pd.merge(df1, df2, on='key', how='right')
# 外连接
result_outer = pd.merge(df1, df2, on='key', how='outer')
通过这些示例代码,你可以了解如何使用 Pandas 进行数据合并和连接。Pandas 提供了丰富的功能来支持不同类型的连接操作,使得合并多个数据集变得简单和灵活。
八、数据分组和聚合示例代码

 在 Pandas 中,你可以使用数据分组和聚合功能来按照指定的条件对数据进行分组,并进行聚合操作,如求和、平均值等。以下是一些示例代码,演示如何使用 Pandas 进行数据分组和聚合:
在 Pandas 中,你可以使用数据分组和聚合功能来按照指定的条件对数据进行分组,并进行聚合操作,如求和、平均值等。以下是一些示例代码,演示如何使用 Pandas 进行数据分组和聚合:
import pandas as pd
# 创建示例 DataFrame
data = {
'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [10, 20, 30, 40, 50, 60]
}
df = pd.DataFrame(data)
# 按照 'Category' 列进行分组,并计算每组的平均值
grouped = df.groupby('Category').mean()
# 按照多列进行分组,并计算每组的总和
grouped_multiple = df.groupby(['Category']).sum()
# 对多列进行分组,并同时计算多个聚合函数
grouped_multiple_functions = df.groupby('Category').agg({'Value': ['sum', 'mean']})
# 对每个分组应用自定义的聚合函数
def custom\_aggregation(x):
return x.max() - x.min()
custom_aggregated = df.groupby('Category').agg({'Value': custom_aggregation})
# 对每个分组应用多个自定义的聚合函数
custom_aggregated_multiple = df.groupby('Category').agg({'Value': [custom_aggregation, 'mean']})
通过这些示例代码,你可以了解如何使用 Pandas 进行数据分组和聚合操作。Pandas 提供了强大的功能来轻松地对数据进行分组和应用各种聚合函数,帮助你更好地理解数据并进行数据分析。
九、数据转换示例代码
 在 Pandas 中,你可以对数据进行各种转换操作,包括排序、重塑、透视等。以下是一些示例代码,演示如何使用 Pandas 进行数据转换:
在 Pandas 中,你可以对数据进行各种转换操作,包括排序、重塑、透视等。以下是一些示例代码,演示如何使用 Pandas 进行数据转换:
- 数据排序:
import pandas as pd
# 创建示例 DataFrame
data = {
'A': [3, 2, 1, 4],
'B': ['apple', 'banana', 'cherry', 'date']
}
df = pd.DataFrame(data)
# 按照 'A' 列进行升序排序
sorted_df = df.sort_values(by='A')
- 数据重塑(Pivot):
import pandas as pd
# 创建示例 DataFrame
data = {
'A': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'],
'B': ['one', 'one', 'two', 'two', 'one', 'one'],
'C': [1, 2, 3, 4, 5, 6]
}
df = pd.DataFrame(data)
# Pivot 操作
pivot_df = df.pivot(index='A', columns='B', values='C')
- 数据透视:
import pandas as pd
# 创建示例 DataFrame
data = {
'A': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'],
'B': ['one', 'one', 'two', 'two', 'one', 'one'],
'C': [1, 2, 3, 4, 5, 6]
### 最后
> **🍅 硬核资料**:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
> **🍅 技术互助**:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
> **🍅 面试题库**:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
> **🍅 知识体系**:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









