







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
urllib是一个包含几个模块来处理请求的库。分别是:
urllib.request 发送http请求
urllib.error 处理请求过程中,出现的异常。
urllib.parse 解析url
urllib.robotparser 解析robots.txt 文件
urllib.request
urllib当中使用最多的模块,涉及请求,响应,浏览器模拟,代理,cookie等功能。
- 快速请求
urlopen返回对象提供一些基本方法:
read 返回文本数据
info 服务器返回的头信息
getcode 状态码
geturl 请求的url
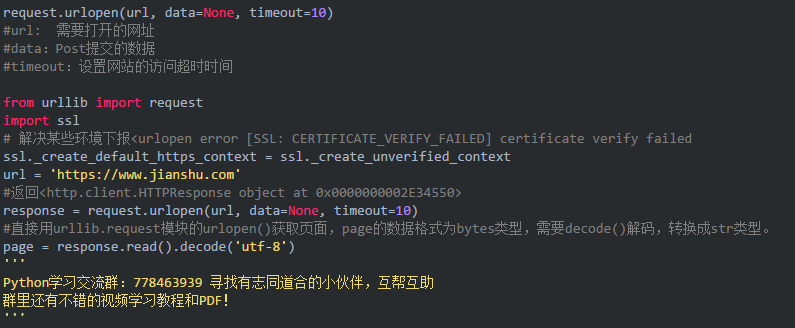
2.模拟PC浏览器和手机浏览器
需要添加headers头信息,urlopen不支持,需要使用Request
PC
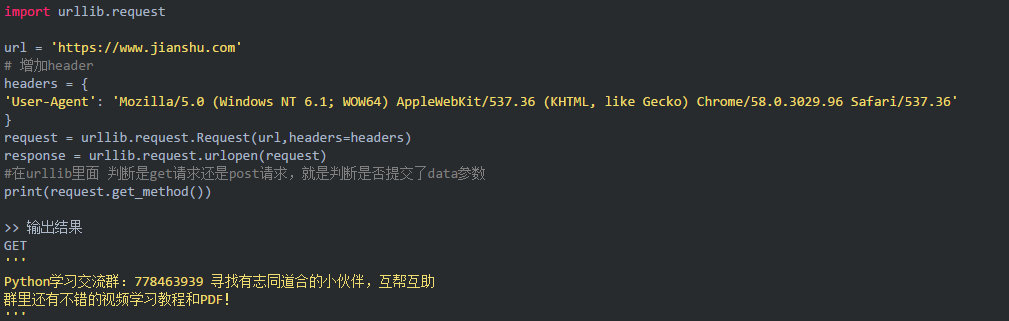
手机

3.Cookie的使用
客户端用于记录用户身份,维持登录信息

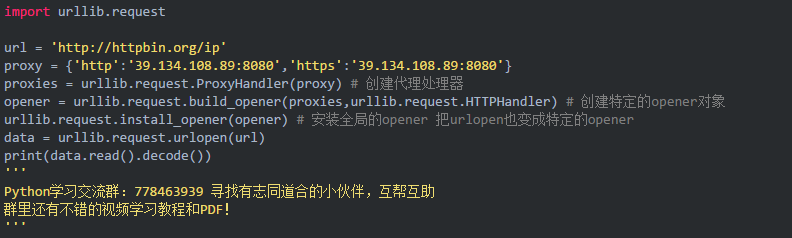
4.设置代理
当需要抓取的网站设置了访问限制,这时就需要用到代理来抓取数据。
urllib.error
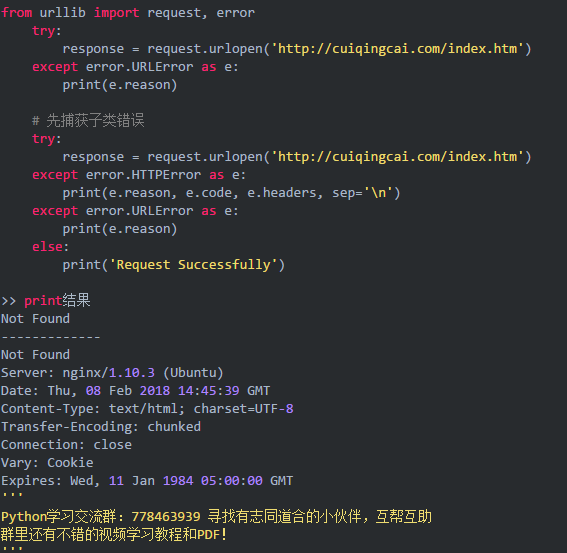
urllib.error可以接收有urllib.request产生的异常。urllib.error中常用的有两个方法,URLError和HTTPError。URLError是OSError的一个子类,
HTTPError是URLError的一个子类,服务器上HTTP的响应会返回一个状态码,根据这个HTTP状态码,我们可以知道我们的访问是否成功。
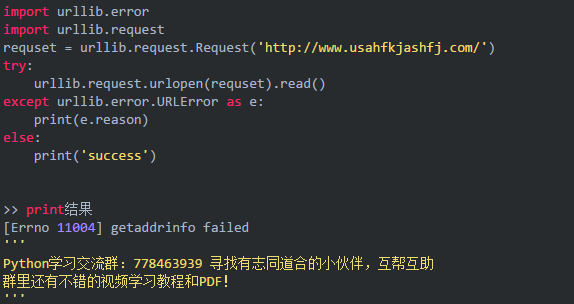
URLError
URLError产生原因一般是:网络无法连接、服务器不存在等。
例如访问一个不存在的url
HTTPError
HTTPError是URLError的子类,在你利用URLopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中他包含一个数字“状态码”,
例如response是一个重定向,需定位到别的地址获取文档,urllib将对此进行处理。其他不能处理的,URLopen会产生一个HTTPError,对应相应的状态码,
HTTP状态码表示HTTP协议所返回的响应的状态。
urllib.parse
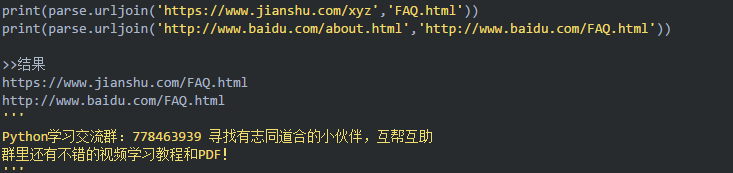
urllib.parse.urljoin 拼接url
基于一个base URL和另一个URL构造一个绝对URL,url必须为一致站点,否则后面参数会覆盖前面的host
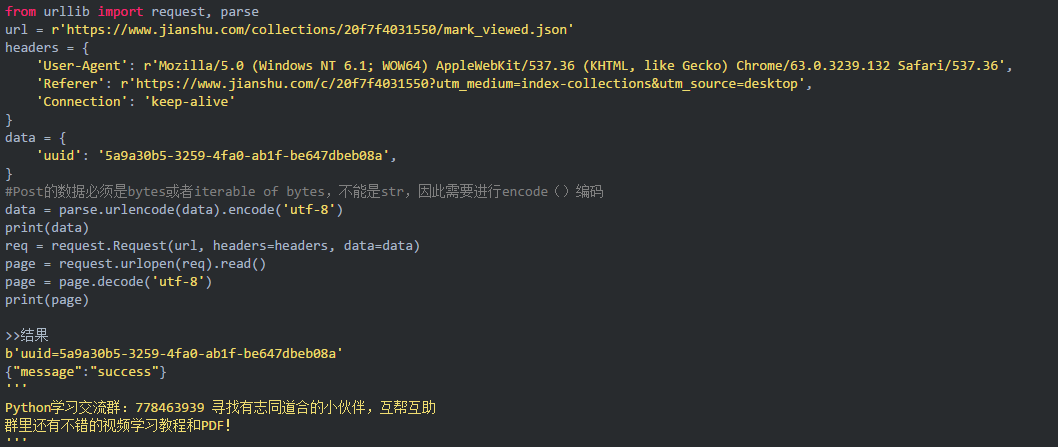
urllib.parse.urlencode 字典转字符串
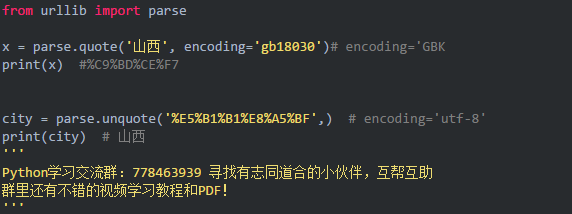
urllib.parse.quote url编码
urllib.parse.unquote url解码
Url的编码格式采用的是ASCII码,而不是Unicode,比如
http://so.biquge.la/cse/search?s=7138806708853866527&q=��������
urllib3包
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库里所没有的重要特性:
1.线程安全
2.连接池
3.客户端SSL/TLS验证
4.文件分部编码上传
5.协助处理重复请求和HTTP重定位
6.支持压缩编码
7.支持HTTP和SOCKS代理
安装:
Urllib3 能通过pip来安装:
$pip install urllib3
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









