







一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-
Python 3.6
-
Pycharm
import requests
import parsel
import re
import os
import pdfkit
安装Python并添加到环境变量,pip安装需要的相关模块即可。
需要使用到一个软件 wkhtmltopdf 这个软件的作用就是把html文件转成PDF
(软件可以点击上方链接在学习交流群中即可获取)
想要把文档内容保存成PDF, 首先保存成html文件, 然后把html文件转PDF
写爬虫程序,对于数据来源的分析,是比较重要的,因为只有当你知道数据的来源你才能通过代码去实现

网站分类有比较多种, 也可以选择自己要爬取的。
这个网站如果你只是正常直接去复制文章内容的话,会直接弹出需要费的窗口…
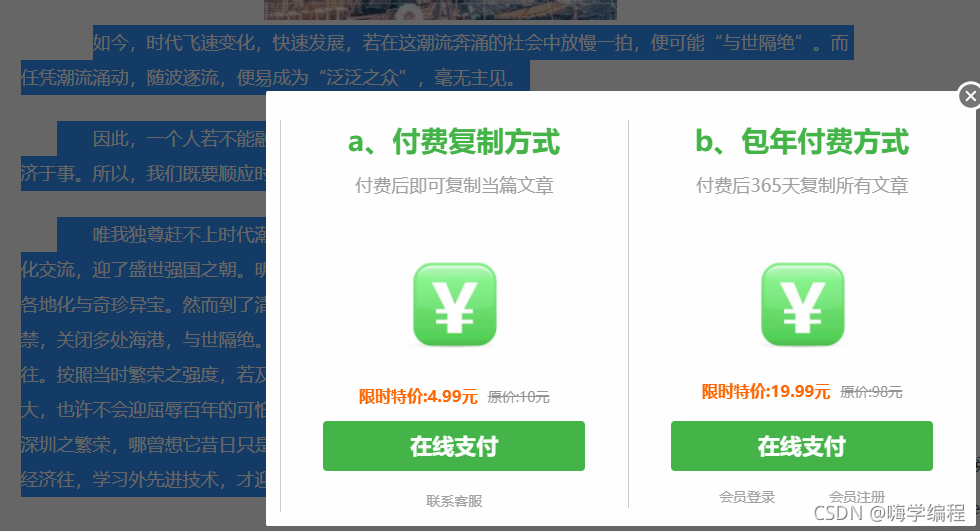
但是这个网站上面的数据内容又非常好找, 因为网站本身仅仅只是静态网页数据,可以直接获取相关的内容。
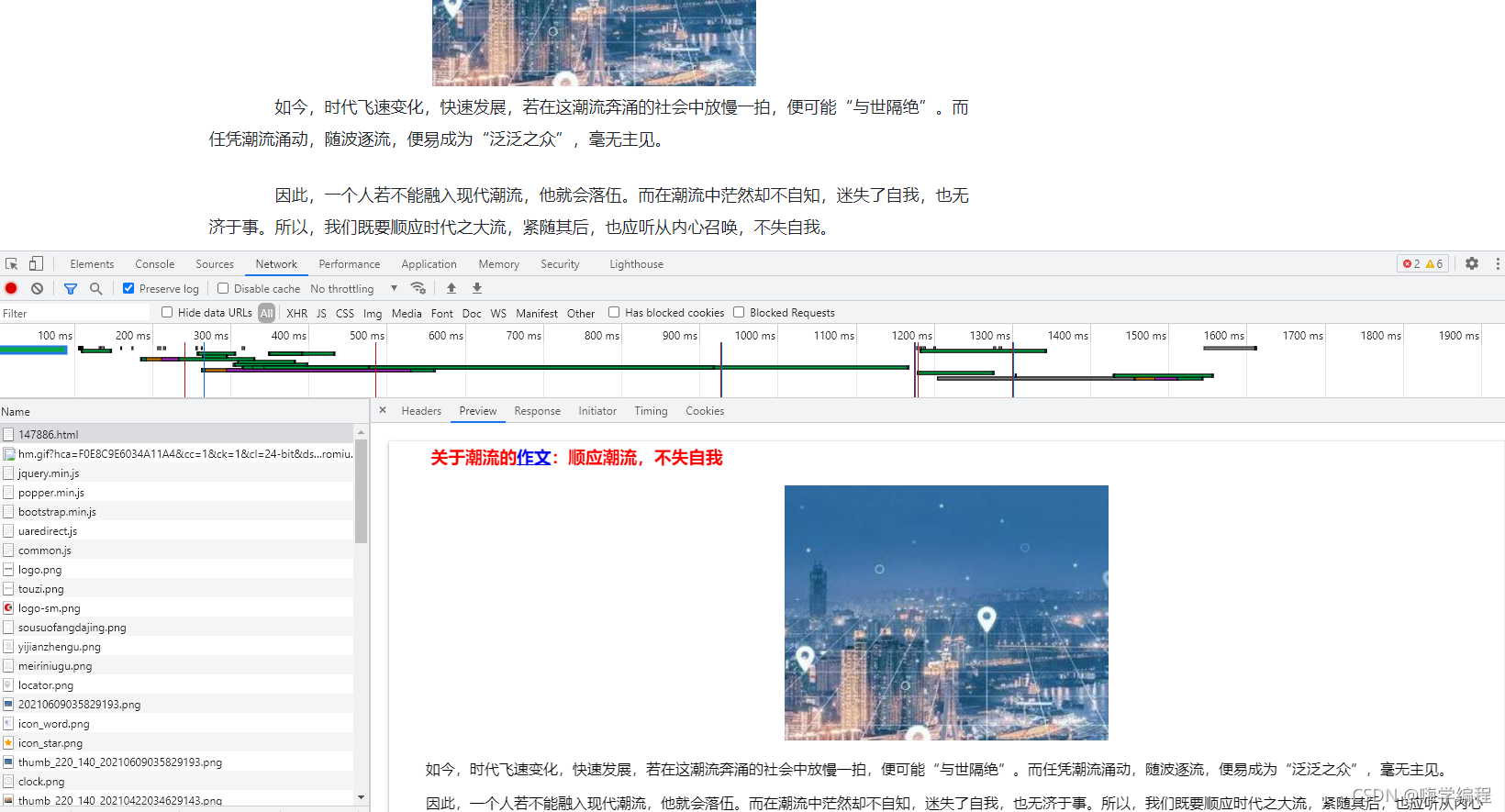
通过上述内容,如果想要批量下载文章内容, 获取每篇文章的url地址即可, 想要获取每篇文章的url地址,这就需要去文章的列表页面找寻相关的数据内容了。
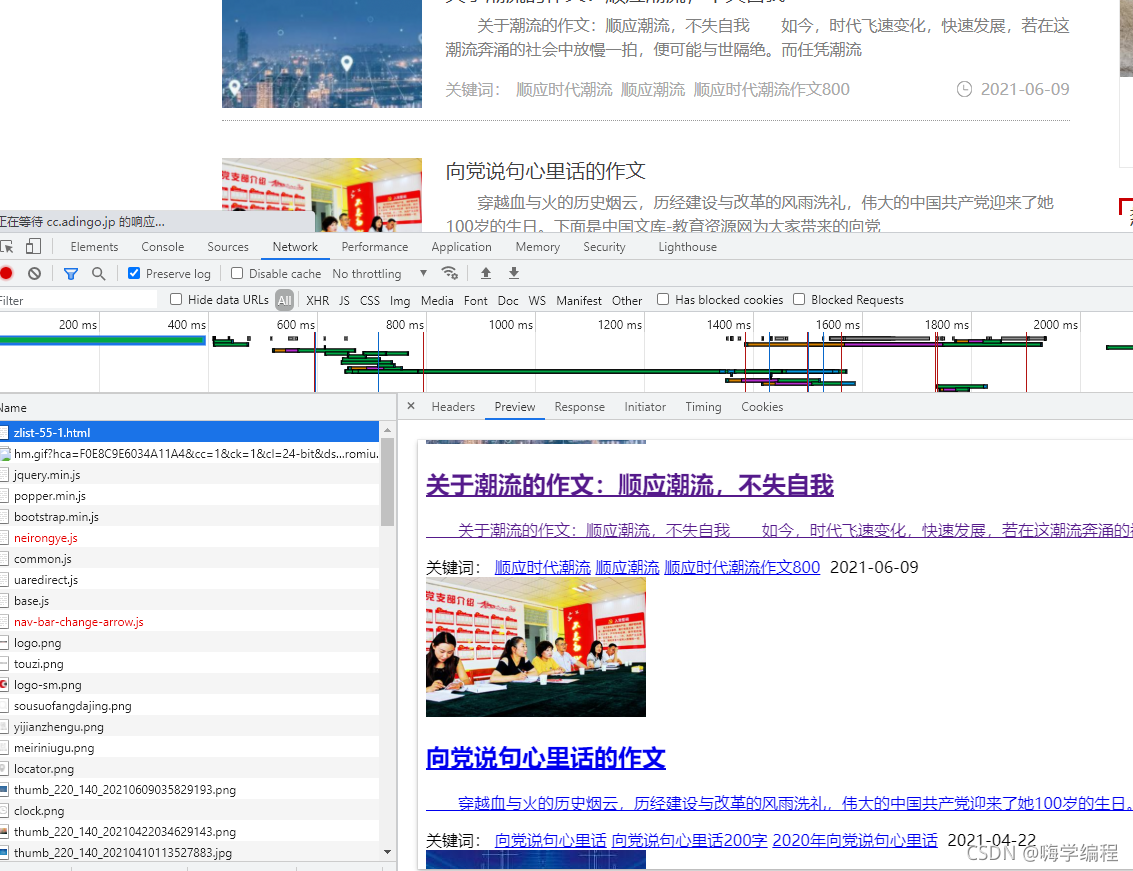
-
发送请求,对于文章列表url地址发送请求
-
获取数据,获取网页源代码数据内容
-
解析数据,提取文章url地址
-
发送请求,对于文章url地址发送请求
-
获取数据,获取网页源代码数据内容
-
解析数据,提取文章标题以及文章内容
-
保存数据,把获取的数据内容保存成PDF
-
转成PDF文件
import requests
import parsel
import re
import os
import pdfkit
html_filename = ‘html\’
if not os.path.exists(html_filename):
os.mkdir(html_filename)
pdf_filename = ‘pdf\’
if not os.path.exists(pdf_filename):
os.mkdir(pdf_filename)
html_str = “”"
<!doctype html>
{article}
“”"
def change_title(name):
pattern = re.compile(r"[/\😗?“<>|]”) # ‘/ \ : * ? " < > |’
new_title = re.sub(pattern, “_”, name) # 替换为下划线
return new_title
for page in range(1, 11):
print(f’正在爬取第{page}页数据内容’)
url = f’https://www.chinawenwang.com/zlist-55-{page}.html’
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36’
}
response = requests.get(url=url, headers=headers)
href = re.findall(‘
’, response.text)
for index in href:
response_1 = requests.get(url=index, headers=headers)
selector = parsel.Selector(response_1.text)
title = selector.css(‘.content-page-header-div h1::text’).get()
title = change_title(title)
content = selector.css(‘.content-page-main-content-div’).get()
article = html_str.format(article=content)
html_path = html_filename + title + ‘.html’
pdf_path = pdf_filename + title + ‘.pdf’
try:
with open(html_path, mode=‘w’, encoding=‘utf-8’) as f:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









