







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
- 关于文件合并的一些数据,我会放在我的
gitee里面,是关于新冠疫情的数据整理,需要的可以自行获取:covid19数据整理
=======================================================================
首先,要查询目录底下的文件要导入OS。并且我们要将.csv文件以pandas的dataframe底下,因此要导入PANDAS,另外由于我们要遍历目录,因此导入 GLOB:
import os
import pandas as pd
import glob
注:
import os的作用:在python环境下对文件,文件夹执行操作的一个模块。
os.name返回当前系统
os.getcwd()返回当前的路径
os.remove(路径)删除路径下的文件
import glob的作用: glob是python自带的一个操作文件的相关模块,由于模块功能比较少,所以很容易掌握。用它可以查找符合特定规则的文件路径名。使用该模块查找文件,只需要用到: “*”, “?”, “[]”这三个匹配符;
”*”匹配0个或多个字符;
”?”匹配单个字符;
”[]”匹配指定范围内的字符,如:[0-9]匹配数字。
f1=open(‘…/input/covid19temp/2020/12-30-2020.csv’).read()
f2=open(‘…/input/covid19temp/2020/12-31-2020.csv’).read()
with open(‘f1112.csv’,‘a+’) as f:
f.write(‘\n’+f1)
f.write(‘\n’+f2)
合并完成之后就会多出一个f1112.csv文件:
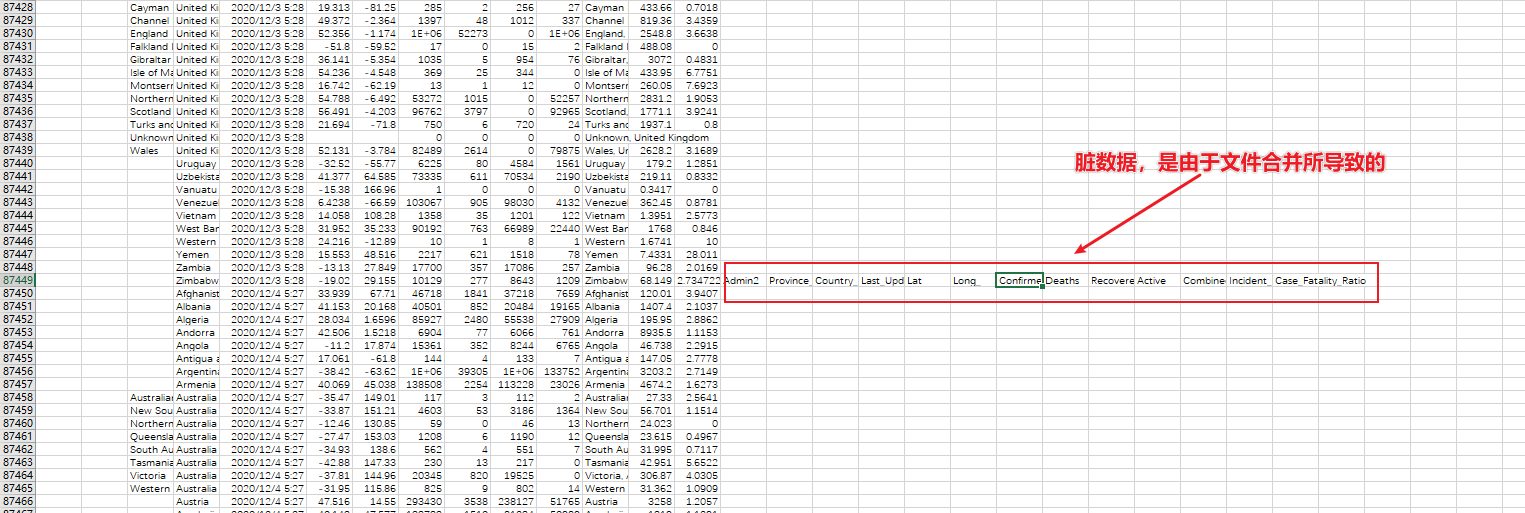
然而打开f1112.csv后发现合并后的文件有一些脏数据没有整理:
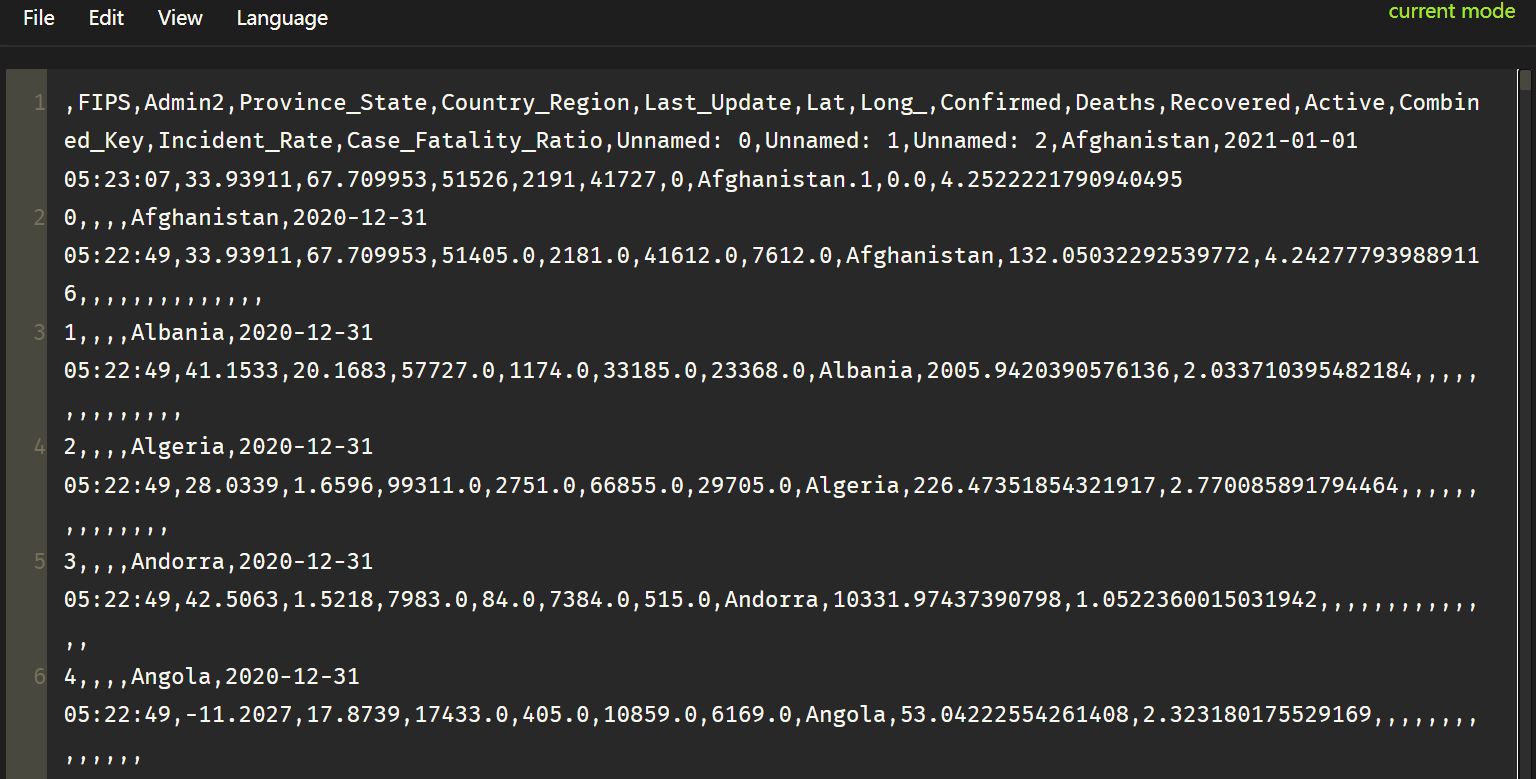
这时候我们试试skiprows:
在读取文件的时候设置skiprows参数的值,设置为1,会跳过一行,这里是要将第二个文件的索引属性给去掉,因为已经和第一个文件合并了,而第一个文件有索引属性了。
f1=pd.read_csv(‘…/input/covid19temp/2020/12-30-2020.csv’)
f2=pd.read_csv(‘…/input/covid19temp/2020/12-31-2020.csv’,skiprows=1)
f1112=f1.append(f2)
f1112.to_csv(‘f1112.csv’) # 导出该文件
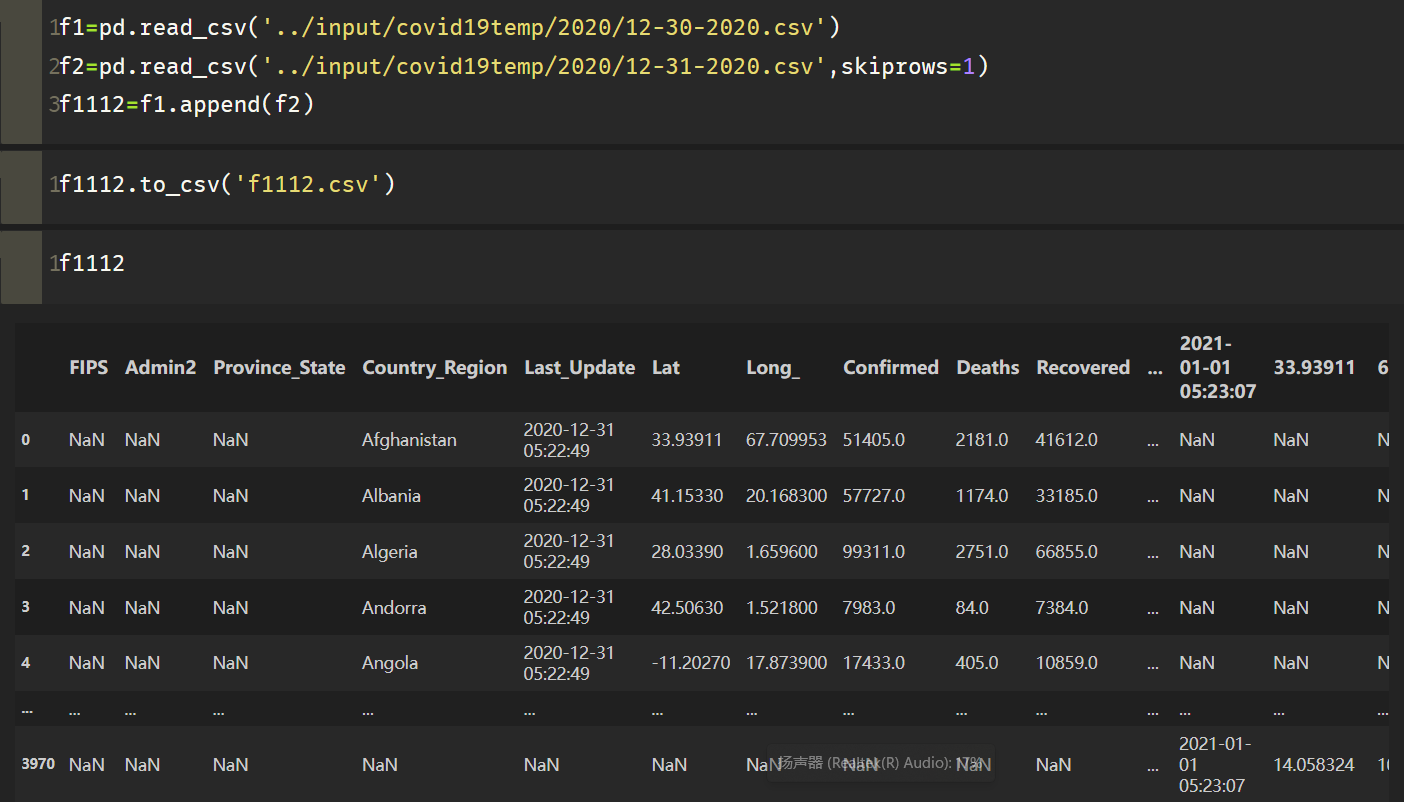
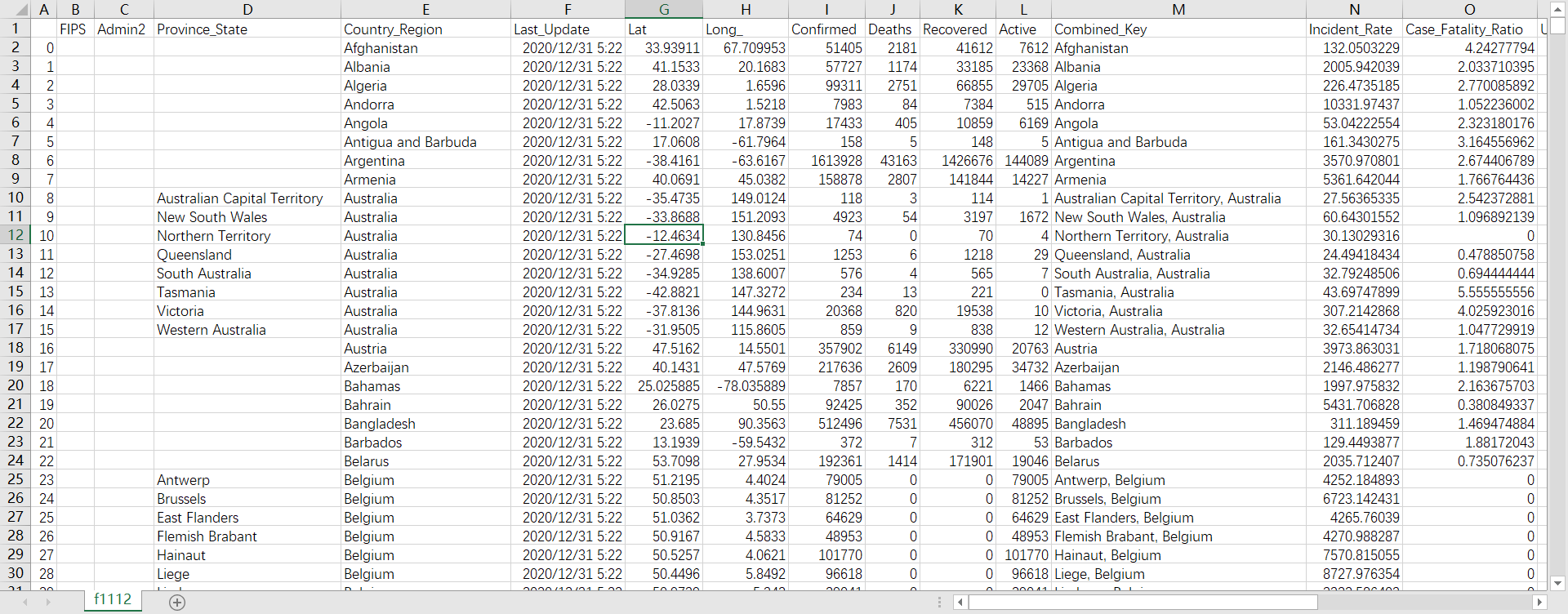
在本地目录中打开该文件:

=============================================================================
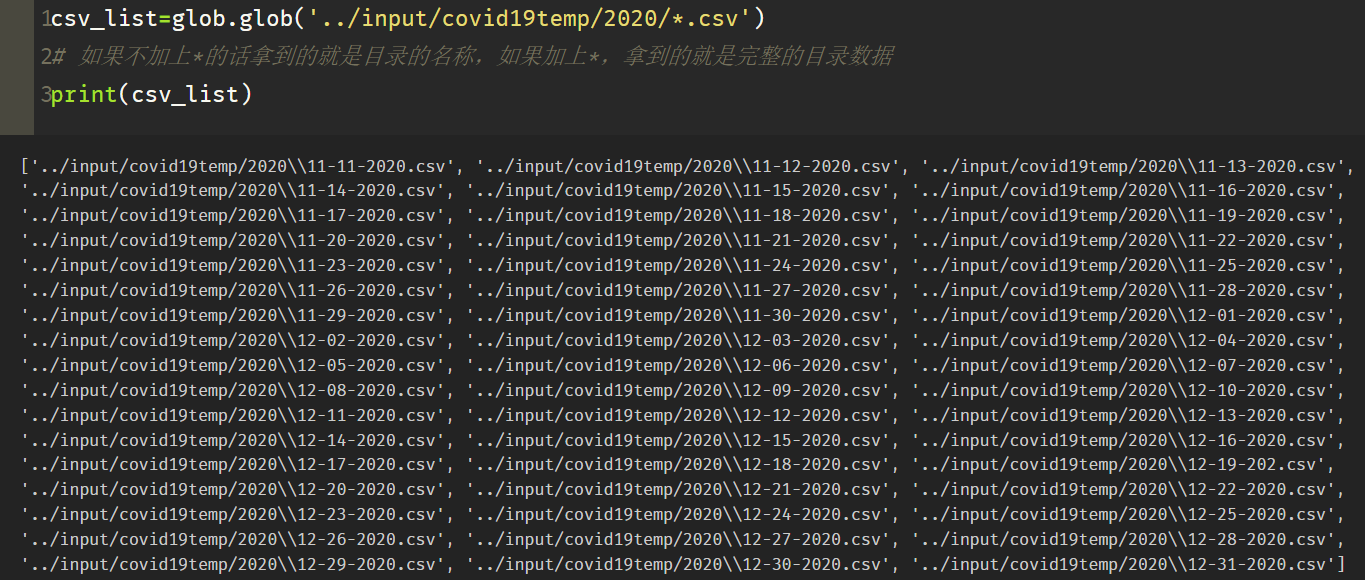
csv_list=glob.glob(‘…/input/covid19temp/2020/*.csv’)
如果不加上的话拿到的就是目录的名称,如果加上,拿到的就是完整的目录数据
print(csv_list)
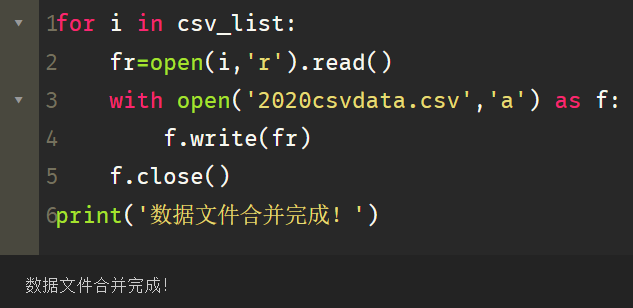
for i in csv_list:
fr=open(i,‘r’).read()
with open(‘2020csvdata.csv’,‘a’) as f:
f.write(fr)
f.close()
print(‘数据文件合并完成!’)
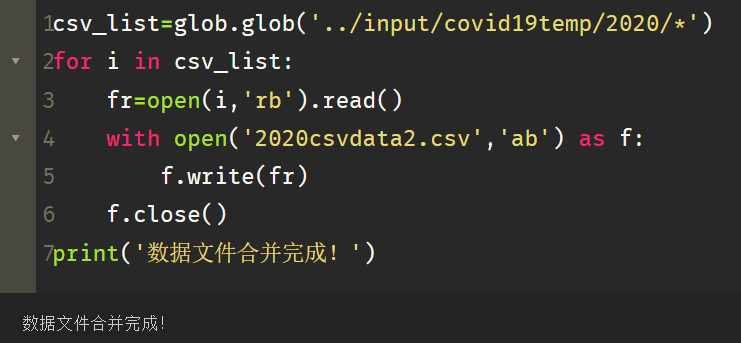
csv_list=glob.glob(‘…/input/covid19temp/2020/*’)
for i in csv_list:
fr=open(i,‘rb’).read()
with open(‘2020csvdata2.csv’,‘ab’) as f:
f.write(fr)
f.close()
print(‘数据文件合并完成!’)
csv_list=glob.glob(‘…/input/covid19temp/2020/*’)
csvdatadf=pd.DataFrame()
for i in csv_list:
csvdata=pd.read_csv(i)
csvdatadf=csvdatadf.append(csvdata)
print(‘数据文件合并完成!’)
合并之后使用pd.read_csv读取文件数据,一共有20W+的疫情数据记录:
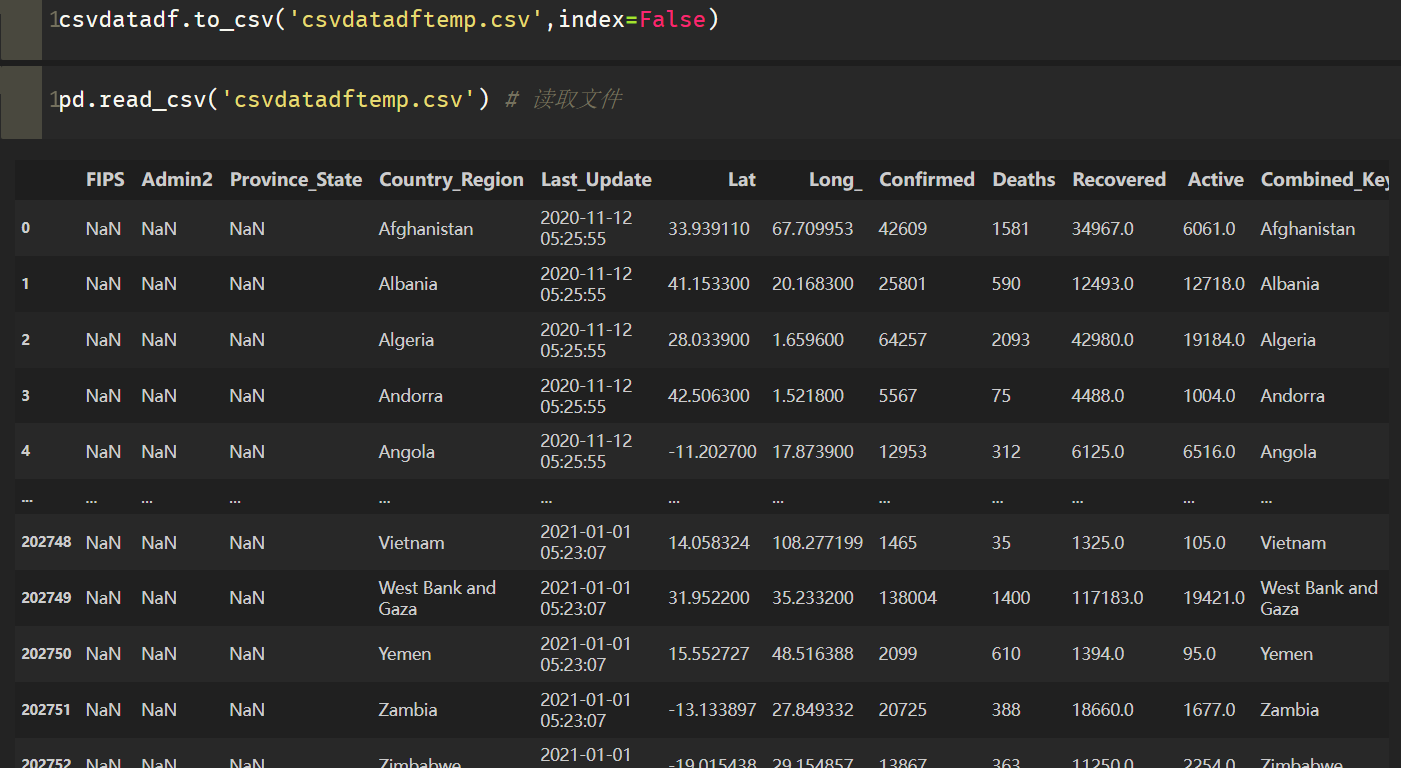
=============================================================================
import os
import pandas as pd
import glob
import openpyxl
import numpy as np
path=‘…/input/covid19temp’ # 写的路径
csv_lists=[] # 该列表的作用
是否更新目录判断:
if os.path.isdir(path): #使用os.path.isdir判断path是否是路径
if not path.endswith(“/”):# 如果该路径的最后没有加上’/'的话,会帮忙加一个/
path+=“/”
print(path)
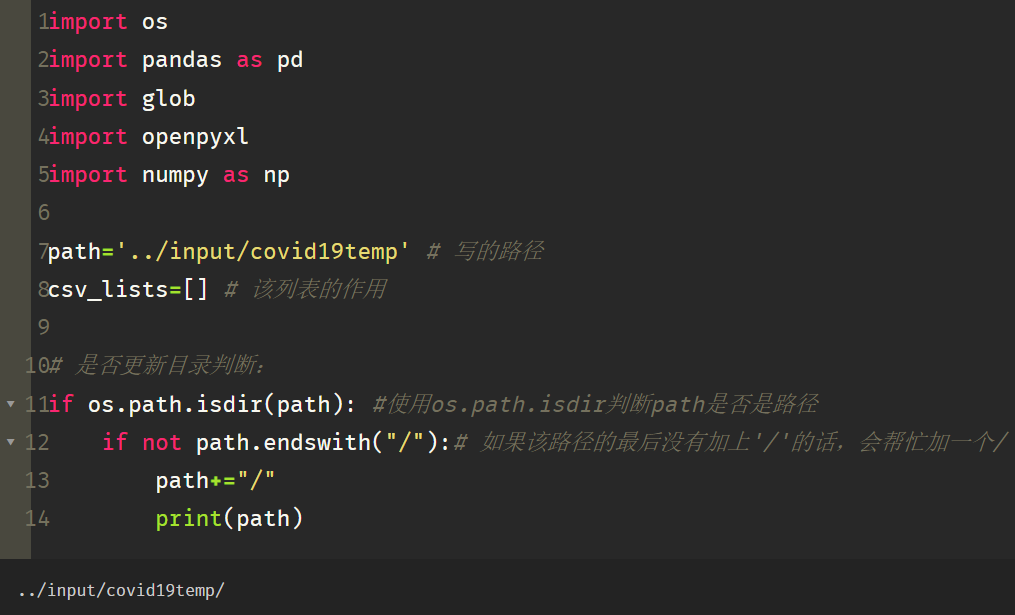
如上图所示,路径后面多了一个 ‘/’,否则路径会找不到
文件操作:
-
os.listdir():列出路径下所有的文件 -
os.path.join():连接文件的作用 -
os.path.isdir():判断是否是文件夹
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
img-blog.csdnimg.cn/5db8141418d544d3a8e9da4805b1a3f9.png)
👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-tUGiGEEY-1713365226719)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2476
2476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









