







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-
网络性能测试
-
服务器应用程序性能
-
服务器硬件性能
-
数据库的性能
二、linux性能监控–CPU
CPU相关的指标
-
CPU使用率:sys% user%(系统的cpu使用率和用户的cpu使用率)
-
队列长度
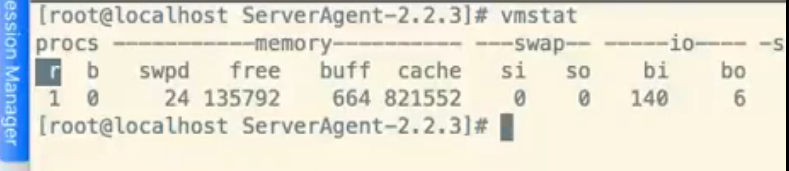
1. 查看CPU使用率
使用vmstat 或top 查看CPU使用情况 us 和sy
标准: cpu使用率: us+sy不能超过75%,偶尔可以100%
vmstat 5:每5秒采集一次

vmstat 主要参数说明
- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我 本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M (这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断。
- cs 每秒上下文切换次数,上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间。
2.查看队列长度
使用vmstat -5 执行,查看 r列的数据
标准:队列长度不能超过2,有队列的产生,或者CPU处理不过来
r值<=2
r值在[3,5]
r值在(5,10]
r值在 >10
3.查看CPU使用较大的进程
ps -aux查看进程的CPU使用情况
目的:找出高CPU的进程
ps auxw|head -1;ps auxw|sort -rn -k3|head -1 (查看CPU使用较大的前10个进程)

三、linux性能监控–内存
核心指标
-
可用物理内存的比例
-
是否使用了虚拟内存
3.是否存在内存泄漏
1. 查看物理内存的使用情况
free命令查看使用情况

标准:linux的可用物理内存可为0,全部用完,只要不使用虚拟内存
2.查看是否使用了虚拟内存
方法1: vmstat 查看si so列
标准: si 和so大于0,表示物理内存不够用或者内存泄露了

方法2: sar –W 10 3 (10和3代表了每个10秒监控一次,总共监控3次)
标准:值大于0,就说明内存已经饱和了

pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量
3. 找出高内存使用的进程
3.1内存消耗最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k4|head -10
3.2 虚拟内存使用最多的前10个进程
ps auxw|head -1;ps auxw|sort -rn -k5|head
%MEM 进程的内存占用率
VSZ 进程所使用的虚存的大小
RSS 进程使用的驻留集大小或者是实际内存的大小
四、linux性能监控–硬盘IO的监控
核心指标
1.硬盘的使用率
2.物理硬盘驱动器忙于读或写入的时间
工具:iostat、iotop、pt-ioprofile
1. 查看硬盘的使用率: df -lh

2. 查看具体的那个硬盘的IO较高:
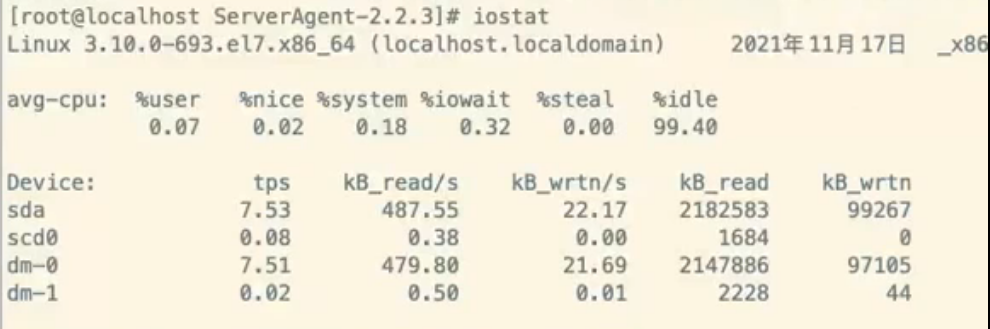
使用iostat 工具来查
ostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该 命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所 需的统计信息
安装iostat 安装命令: yum install sysstat
语法: iostat [ -c ] [ -d ] [ -h ] [ -N ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -z ] [ device
[…] | ALL ] [ -p [ device [,…] | ALL ] ] [ interval [ count ] ]
-c 显示CPU使用情况
-d 显示磁盘使用情况
-k 以K为单位显示
-m 以M为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS使用情况
-p 可以报告出每块磁盘的每个分区的使用情况
-t 显示终端和CPU的信息 -x 显示详细信息
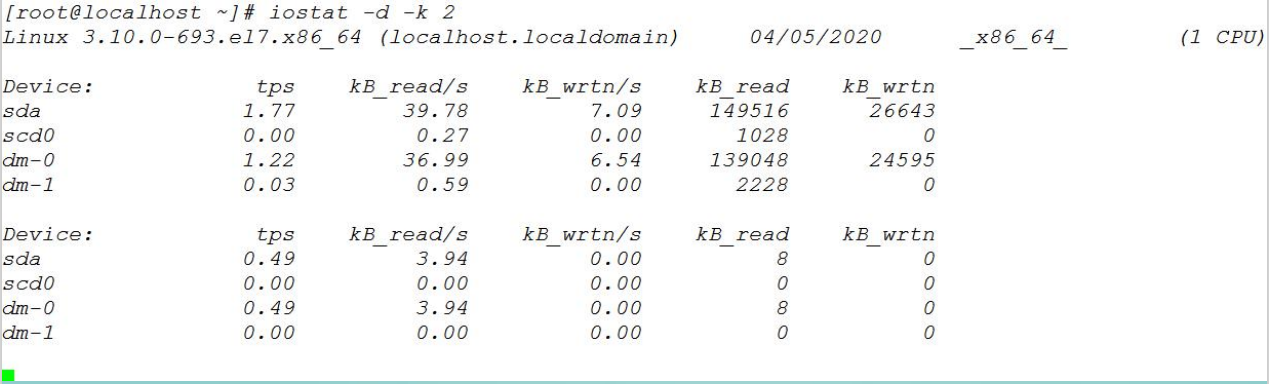
iostat -d -k 2
参数 -d 表示,显示设备(磁盘)使用状态;-k 某些使用 block为单位的列强制使用Kilobytes为单位;2表示,数据显示每隔2秒刷新一次。
iostat -x 5 查看:%util
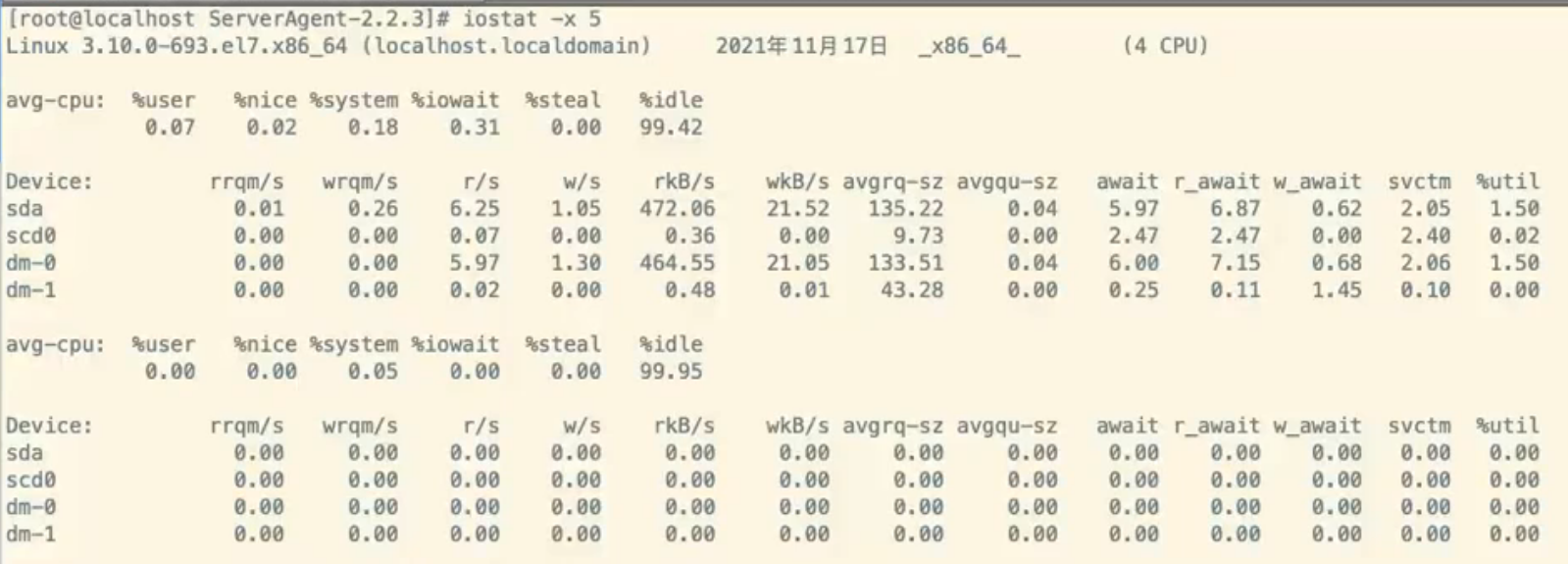
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒);
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
**标准:**物理硬盘驱动器忙于读或写入的时间 40% 60% 80%
3. 查看哪个进程耗IO比较高
使用iotop 命令: 查询出较大的IO 的进程
iotop是一个用来监视磁盘I/O使用状况的 top 类工具,可监测到哪一个程序使用的磁盘IO的信息
**安装:**yum install iotop
**查看:**iotop 按 o 只显示有磁盘 IO 活动的进程

语法:iotop [OPTIONS]
- –version #显示版本号
- -h, --help #显示帮助信息
- -o, --only #显示进程或者线程实际上正在做的I/O,而不是全部的,可以随时切换按o
- -b, --batch #运行在非交互式的模式
- -n NUM, --iter=NUM #在非交互式模式下,设置显示的次数,
- -d SEC, --delay=SEC #设置显示的间隔秒数,支持非整数值
- -p PID, --pid=PID #只显示指定PID的信息
- -u USER, --user=USER #显示指定的用户的进程的信息
- -P, --processes #只显示进程,一般为显示所有的线程
- -a, --accumulated #显示从iotop启动后每个线程完成了的IO总数
- -k, --kilobytes #以千字节显示
- -t, --time #在每一行前添加一个当前的时间
4. 定位来源文件
pt-ioprofile定位负载来源文件,通过iotop或ps找出负载较高的进程
安装: 下载地址https://www.percona.com/downloads/percona-toolkit/LATEST/
CentOS 7下安装:
yum -y install https://www.percona.com/downloads/perconatoolkit/3.0.1/binary/redhat/7/x86_64/percona-toolkit-3.0.1-1.el7.x86_64.rpm
使用:
**命令格式:**pt-ioprofile --profile-pid=xxx
pt-ioprofile --profile-pid=xxx --cell=size
pt-ioprofile --profile-pid=需要监控的PID --cell=size
pt-ioprofile的原理是对某个pid附加一个strace进程进行IO分析。
**步骤1:**iotop 查询出高io的pid
**步骤2:**pt-ioprofile --profile-pid=需要监控的PID --cell=size
对于定位问题更有用的是通过IO的吞吐量来进行定位。
使用参数 --cell=sizes,该参数将结果已 B/s 的方式展示出来
pt-ioprofile --profile-pid=需要监控的PID --cell=sizes
五、linux性能监控–网络监控
网络的监测是所有 Linux 子系统里面最复杂的,有太多的 因素在里面,比如:延迟、阻塞、冲突、丢包等,更糟的是与 Linux 主机相连的路由器、交换机、无线信号都会影响到整体 网络并且很难判断是因为 Linux 网络子系统的问题还是别的设 备的问题,增加了监测和判断的复杂度。
核心指标
- 网络带宽是否够用
- 丢包率、错误重传
- 网络延迟/堵塞
- 网络错误
监控网络操作步骤
1.查每秒接受和发送的数据量,检查当前带宽是否够用
使用nicstat 工具查看网卡的利用率
nicstat可以提供更加全面的网卡信息。
- 显示TCP流量统计
- 显示UDP流量统计
- 报告进出网卡的字节数
- 报告进出网卡的数据数
- 报告网卡利用率
- 报告NIC饱和度和其他信息
nicstat下载
cd /usr/local/src
wget http://nchc.dl.sourceforge.net/project/nicstat/nicstat-1.92.tar.gz
nicstat安装
tar -xzf nicstat-1.92.tar.gz
cd nicstat-1.92
cp Makefile.Linux Makefile
make
nicstat使用

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
at-1.92.tar.gz
cd nicstat-1.92
cp Makefile.Linux Makefile
make
nicstat使用
[外链图片转存中…(img-57DFzTHU-1715797443892)]
[外链图片转存中…(img-9wTsF8s3-1715797443893)]
[外链图片转存中…(img-4npoogY5-1715797443893)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









