







最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
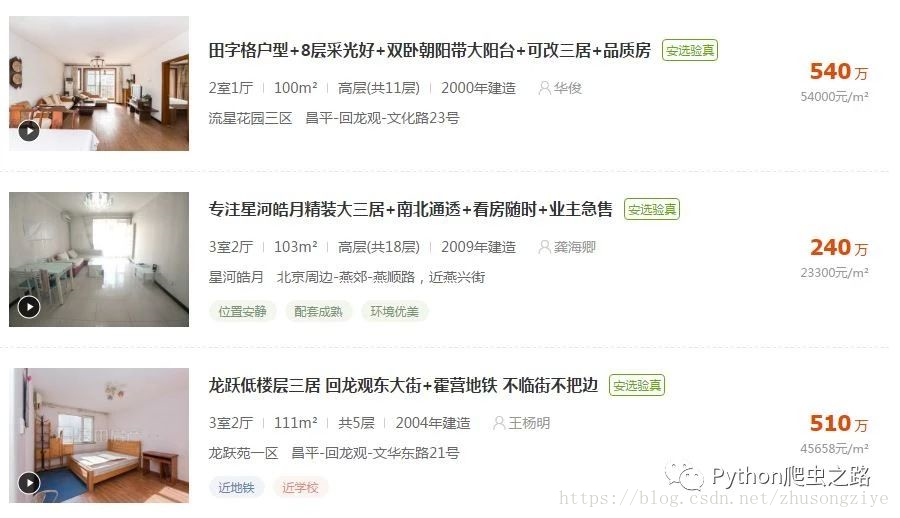
每页的住房信息:
点开链接后的详细信息:

博主并没有采用分区域进行爬取,博主是直接进行全部爬取,然后循环下一页完成的。步骤很简单,如下:
- 先把每一页的所有二手住房详细链接爬取到
- 请求每一个爬取到的详细链接,解析住房信息
- 完成所有解析后,请求下一页的链接
- 返回步骤一循环,直到返回内容为空
Scrapy代码实现
数据结构定义
Scrapy中的元数据field其实是继承了Python中的字典数据类型,使用起来很方便,博主直接定义了几个住房的信息,如下代码所示。当然还有高级的用法,配合itemloader加入processor,这里只使用简单的定义即可。
class AnjukeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
price = scrapy.Field()
mode = scrapy.Field()
area = scrapy.Field()
floor = scrapy.Field()
age = scrapy.Field()
location = scrapy.Field()
district = scrapy.Field()
pass
爬虫解析
- 定义了一个继承
Scrapy自带的爬虫类Spider。 - 然后一个必不可少的东西是
name,它贯穿了整个Scrapy的始终,后面会看到它的作用。 start_urls是初始请求的url的列表,也可以有多个初始url,这里只有一个。- 由于
Scrapy的Spider类中默认使用了Request请求,因此这里选择不覆盖Request,使用默认请求,且请求中调用parse回调函数。 - 解析部分用
Scrapy的高级selector选择器的xpath进行解析。
parse函数请求中有两个yield,代表生成器。
- 第一个
yield返回每一页的下一页链接next_pageurl。 - 第二个
yield返回每一页所有的住房详细链接,并再次Request请求跟进,然后调用下一个回调函数parse_detail。
请求的过程中如果速度过快,会要求输入验证码,这里放慢了请求速度,暂不处理验证部分(后续慢慢介绍)。
class AnjukeSpider(scrapy.Spider):
name = 'anjuke'
# custom\_settings = {
# 'REDIRECT\_ENABLED': False
# }
start_urls = ['https://beijing.anjuke.com/sale/']
def parse(self, response):
# 验证码处理部分
pass
# next page link
next_url = response.xpath(
'//\*[@id="content"]/div[4]/div[7]/a[7]/@href').extract()[0]
print('\*\*\*\*\*\*\*\*\*' + str(next_url) + '\*\*\*\*\*\*\*\*\*\*')
if next\_url:
yield scrapy.Request(url=next_url,
callback=self.parse)
# 爬取每一页的所有房屋链接
num = len(response.xpath(
'//\*[@id="houselist-mod-new"]/li').extract())
for i in range(1, num + 1):
url = response.xpath(
'//\*[@id="houselist-mod-new"]/li[{}]/div[2]/div[1]/a/@href'
.format(i)).extract()[0]
yield scrapy.Request(url, callback=self.parse_detail)
parse_detail回调函数中使用itemloader解析items住房信息,并返回载有信息的item。
def parse\_detail(self, response):
houseinfo = response.xpath('//\*[@class="houseInfo-wrap"]')
if houseinfo:
l = ItemLoader(AnjukeItem(), houseinfo)
l.add_xpath('mode', '//div/div[2]/dl[1]/dd/text()')
l.add_xpath('area', '//div/div[2]/dl[2]/dd/text()')
l.add_xpath('floor', '//div/div[2]/dl[4]/dd/text()')
l.add_xpath('age', '//div/div[1]/dl[3]/dd/text()')
l.add_xpath('price', '//div/div[3]/dl[2]/dd/text()')
l.add_xpath('location', '//div/div[1]/dl[1]/dd/a/text()')
l.add_xpath('district', '//div/div[1]/dl[2]/dd/p/a[1]/text()')
yield l.load_item()
数据清洗
由于爬取后的items数据很乱,有各种\n,\t等符号,因此在pipelines中进行简单的清理工作,使用正则表达式实现,代码如下:
import re
def list2str(value):
new = ''.join(value).strip()
return new
class AnjukePipeline(object):
def process\_item(self, item, spider):
area = item['area']
price = item['price']
loc = item['location']
district = item['district']
mode = item['mode']
age = item['age']
floor = item['floor']
modes = list2str(mode)
item['area'] = int(re.findall(r'\d+', list2str(area))[0])
item['age'] = int(re.findall(r'\d+', list2str(age))[0])
item['floor'] = list2str(floor)
item['location'] = list2str(loc)
item['district'] = list2str(district)
item['price'] = int(re.findall(r'\d+', list2str(price))[0])
item['mode'] = modes.replace('\t', '').replace('\n', '')
### 一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

### 二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

### 三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1052
1052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









