







 本文介绍了Apache Paimon,一种流式数据湖存储技术,适用于高吞吐、低延迟场景。文章通过本地Flink伪集群和IDEA演示了Paimon的Stream读写操作,探讨了多流拼接测试中的问题,如主键冲突,提出了解决方案。
本文介绍了Apache Paimon,一种流式数据湖存储技术,适用于高吞吐、低延迟场景。文章通过本地Flink伪集群和IDEA演示了Paimon的Stream读写操作,探讨了多流拼接测试中的问题,如主键冲突,提出了解决方案。
目录
前言
1. 什么是 Apache Paimon
Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。
Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。

Paimon 以湖存储的方式基于分布式文件系统管理元数据,并采用开放的 ORC、Parquet、Avro 文件格式,支持各大主流计算引擎,包括 Flink、Spark、Hive、Trino、Presto。未来会对接更多引擎,包括 Doris 和 Starrocks。
Github:https://github.com/apache/incubator-paimon
以下为快速入门上手Paimon的example:
一、本地环境快速上手
基于paimon 0.4-SNAPSHOT (Flink 1.14.4),Flink版本太低是不支持的,paimon基于最低版本1.14.6,经尝试在Flink1.14.0是不可以的!
paimon-flink-1.14-0.4-20230504.002229-50.jar
1、本地Flink伪集群
-
需要先下载jar包,并添加至flink的lib中;
-
根据官网demo,启动flinksql-client,创建catalog,创建表,创建数据源(视图),insert数据到表中。
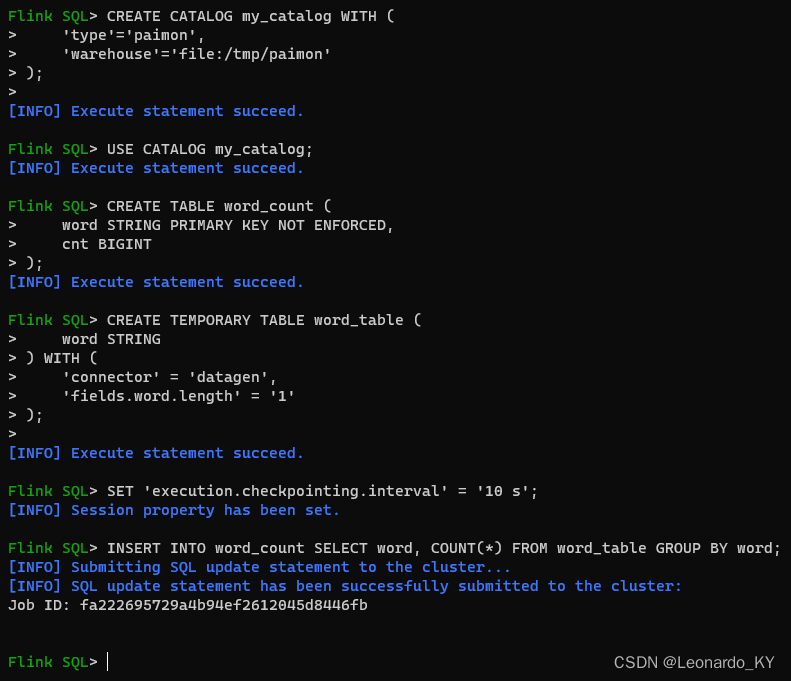
- 通过 localhost:8081 查看 Flink UI

- 查看filesystem数据、元数据文件

2、IDEA中跑Paimon Demo
pom依赖:
<dependency>
<groupId>org.apache.paimon</groupId>
<artifactId>paimon-flink-1.14</artifactId>
<version>0.4-SNAPSHOT</version& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









