







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

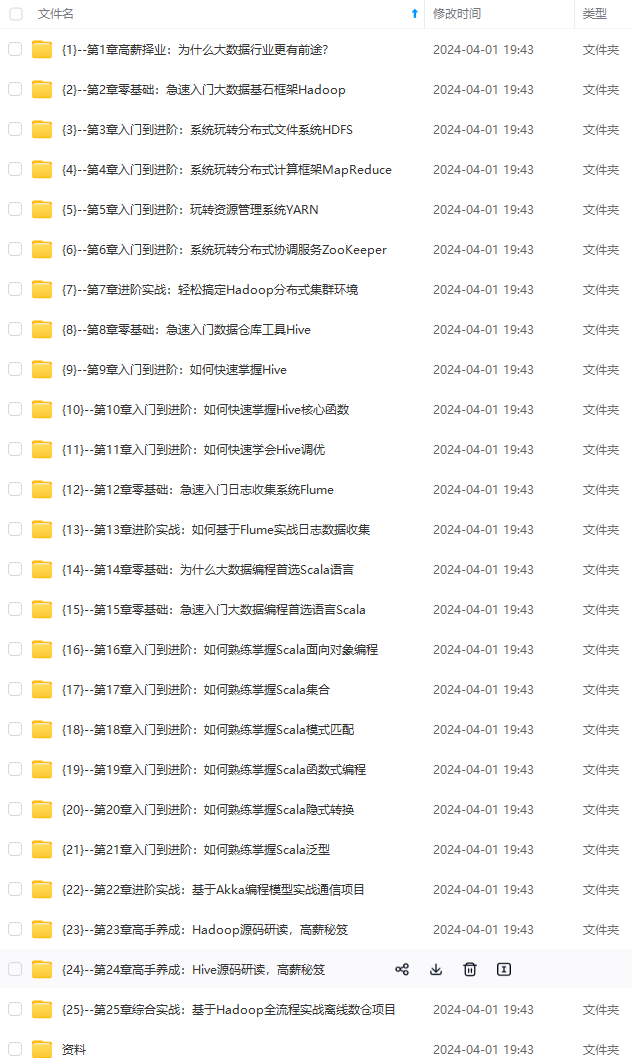
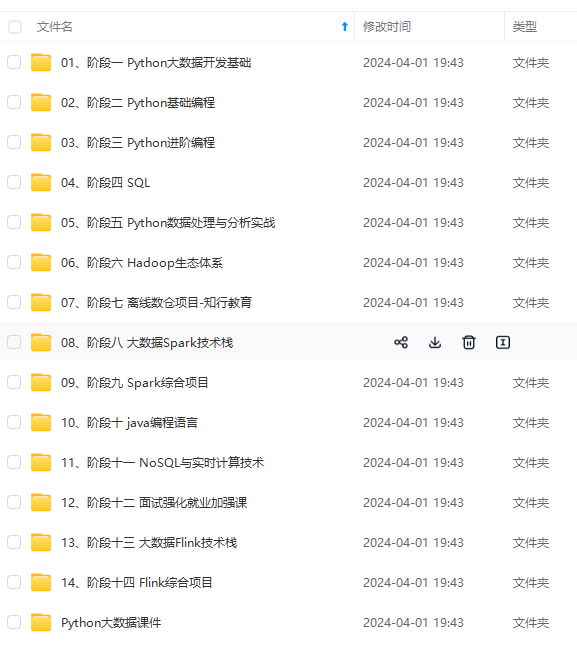
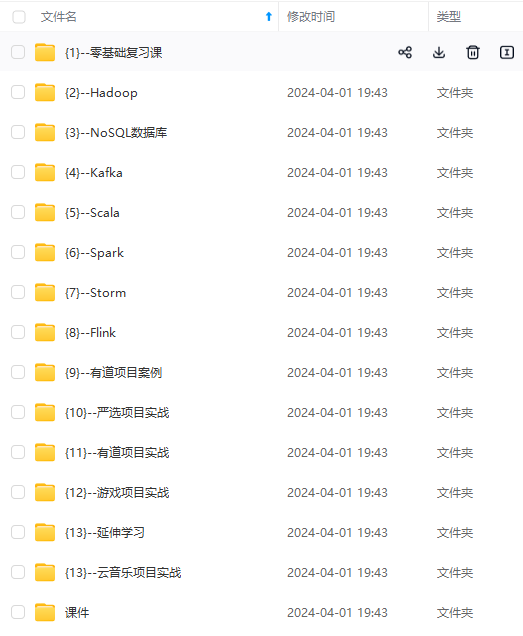
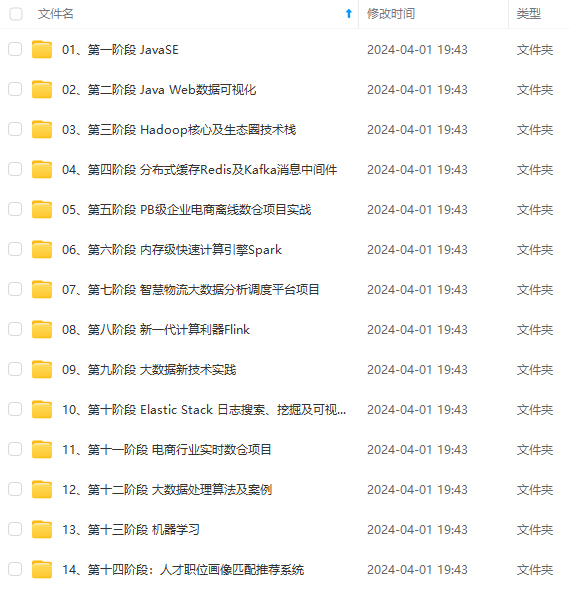
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
内部表的数据是由Hive自身管理的,外部表的数据是由HDFS管理的;
删除内部表会删除元数据和存储的数据;删除外部表只删除元数据不删除存储的数据
34,你知道UDF吗?
UDF就是Hive提供的内置函数无法满足业务处理需要时,可以考虑使用用户自定义函数。
35 一张大表,一张小表,你写join in时,哪个表放左边,哪个表放右边?
小表放前,大表放后,左查询,根据小表为主进行查询。
36 问一下kafka的问题吧,kafka是怎么进行数据备份的?
哇,面试官 你是要把大数据里面的每个组件分别问一下,。。。。深呼一口气,思考了一下 然后巴拉巴拉
备份机制是Kafka0.8版本之后出的,一个备份数量为n的集群允许n-1个节点失败。在所有备份节点中,
有一个节点作为lead节点,这个节点保存了其它备份节点列表,并维持各个备份间的状体同步。
37.消费者是从leader中拿数据,还是从follow中拿数据?
。。。不太会,备份机制这块没咋深入了解过。
kafka是由follower周期性或者尝试去pull(拉)过来(其实这个过程与consumer消费过程非常相似),
写是都往leader上写,但是读并不是任意flower上读都行,读也只在leader上读,flower只是数据的一个备份,
保证leader被挂掉后顶上来,并不往外提供服务。
38.那换个问题吧。说说kafka的ISR机制?
- kafka 为了保证数据的一致性使用了isr 机制,
-
- leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,
- 而且是由leader动态维护
-
- 如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除
-
- 当ISR中所有Replica都向Leader发送ACK时,leader才commit
39.kafka如何保证数据的不重复和不丢失?
答案上面已经回到了,面试官又问一遍。。可能是看我kafka这块了解不是很深入。想再虐虐我。。。
40.kafka里面存的数据格式都是什么样的?
topic主题,然后主题进行分区 topic 分为partition , partition里面包含Message。
41.kafka中存的一个是数据文件,一个是索引文件,说说这个?
。。。。。不太会。。。哇,kafka被虐惨啦
42.kafka 是如何清理过期数据的?
kafka的日志实际上是以日志的方式默认保存在/kafka-logs文件夹中的,默认7天清理机制,
日志的真正清理时间。当删除的条件满足以后,日志将被“删除”,但是这里的删除其实只是将
该日志进行了“delete”标注,文件只是无法被索引到了而已。但是文件本身,仍然是存在的,只有当过了log.segment.delete.delay.ms 这个时间以后,文件才会被真正的从文件系统中删除。
43.一条message中包含哪些信息?
- 包含 header,body。
- 一个Kafka的Message由一个固定长度的header和一个变长的消息体body组成。
- header部分由一个字节的magic(文件格式)和四个字节的CRC32(用于判断body消息体是否正常)构成。
- 当magic的值为1的时候,会在magic和crc32之间多一个字节的数据:attributes(保存一些相关属性,比如是否压缩、
- 压缩格式等等);
- 如果magic的值为0,那么不存在attributes属性body是由N个字节构成的一个消息体,包含了具体的key/value消息
44.嗯,行,你知道mysql的最左原则吗?
终于把kafka过去啦。。心累
最左原则:顾名思义,就是最左优先,比如现在有一张表,里面建了三个字段ABC,对A进行主键,BC建立索引,就相当于
创建了多个索引,A索引,(A,B)组合索引,(A,B,C)组合索引,那查询时,会根据查询最频繁的 放到最左边。
嗯 好,我的问题问完了,让我同事问问你。
已经问了40分钟纯问题啦,,再换个面试官,好的,可以
45,刚才我的同事问的都是大数据相关的,那我们问点java相关的。
终于问java啦,下面的java问题每个都回答出来了,就不写答案啦
46.说说抽象类和接口?
47,集合了解吧,说说集合有几大类,分别介绍一下?
48,hashMap顶层实现了解过吗?具体讲讲
49,说说hashMap在1.8之后优化的环节
50. HashMap 和 hashTable的区别?
51.另一个线程安全的是啥?
52.说说ConcurrentHashMap的底层实现
53.java实现多线程的方式有几种?
54.讲讲 synchronized,Lock,ReetrantLock之间的区别
55.java的线程大概有几种状态?
56.sleep 和 wait方法的区别?
57.说说volatile关键字
58.说说JVM内存区域分为几大块,分别讲一下
59.说说sql的事务隔离级别
60.说说mysql的存储引擎
61 给你出个sql 题
student(sid,sname,sex,class)
course(cid,cname,teacher)
grade(cid,sid,score)
1,sex 改为age,非空,默认值为0
2 统计035号课程分数大于036号课程分数的学生ID
3 统计所有003班学生各门功课的课程名称和平均分
以上是所有的面试题,在写sql的时候,卡了好久,因为好久没写过三表联查,子查询的sql,差不多忘了,
后来下线时,一度以为自己挂了,但是过了一个多小时之后,看了一下状态,面试一轮通过,可能是面试官
看我前面的问题答得还可以让我过吧。只是这问题量着实有点多。希望尽快约下轮面试。
多益网络 面经 时长58分钟 挂
1 自我介绍
2 重大项目管理平台介绍
3 你主要负责的是哪一块内容?
4 项目最难的地方在哪?
5 开发周期多长?
6 说一下排行榜公布的那个具体实现过程
7 团队合作中遇到什么问题?
8 对互联网加班有什么看法?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1439
1439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









