






目录
背景
CSDN联合华为昇思举办 昇思25天学习打卡营,从0基础开始,免费提供算力支持,对昇思MindSpore感兴趣的开发者积极报名参与!
点击学习打卡指南链接即可报名参与:昇思25天打卡指南
知识干货
今天的干活是快速入门,顾名思义就是只要知道是什么就行 。
昇思MindSpore介绍
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
昇思MindSpore总体架构如下图所示:
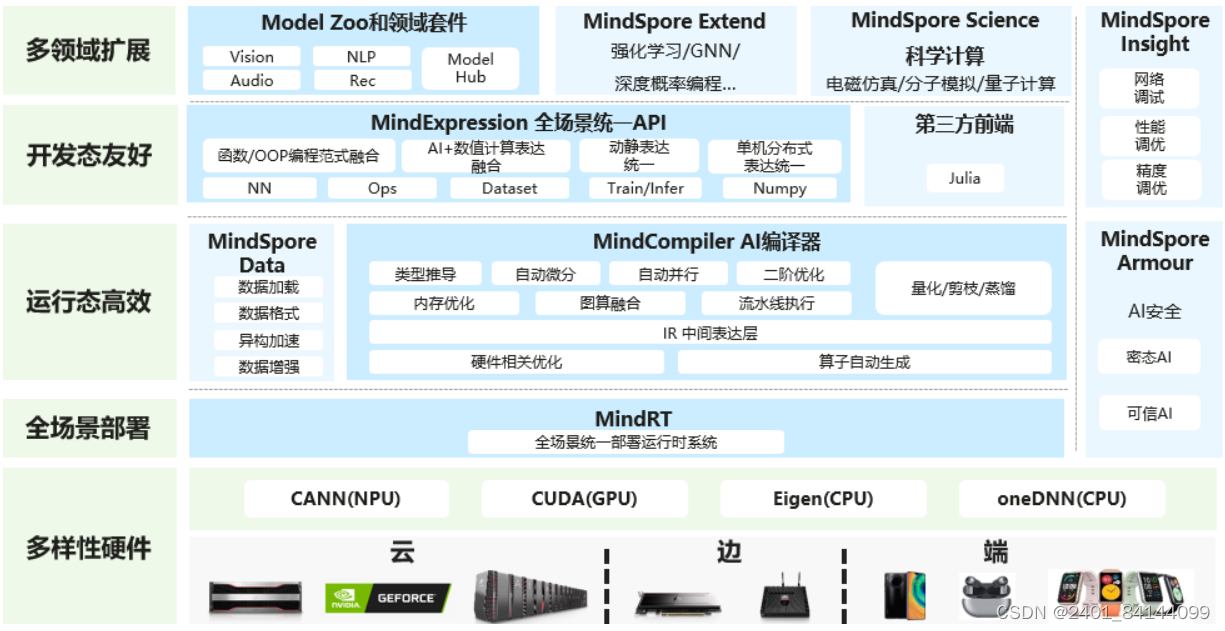
华为昇腾AI全栈介绍
昇腾计算,是基于昇腾系列处理器构建的全栈AI计算基础设施及应用,包括昇腾Ascend系列芯片、Atlas系列硬件、CANN芯片使能、MindSpore AI框架、ModelArts、MindX应用使能等。
华为Atlas人工智能计算解决方案,是基于昇腾系列AI处理器,通过模块、板卡、小站、服务器、集群等丰富的产品形态,打造面向“端、边、云”的全场景AI基础设施方案,涵盖数据中心解决方案、智能边缘解决方案,覆盖深度学习领域推理和训练全流程。
昇腾AI全栈如下图所示:

- 昇腾应用使能:华为各大产品线基于MindSpore提供的AI平台或服务能力
- MindSpore:支持端、边、云独立的和协同的统一训练和推理框架
- CANN:昇腾芯片使能、驱动层(了解更多)。
- 计算资源:昇腾系列化IP、芯片和服务器
入门案例
通过MindSpore的API来快速实现一个简单的深度学习模型,具体操作流程如下:
下载数据集 模型组网 模型训练 保存模型
实验环境准备:

处理数据集
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理。
本章节中的示例代码依赖
download,可使用命令pip install download安装。如本文档以Notebook运行时,完成安装后需要重启kernel才能执行后续代码
示例代码: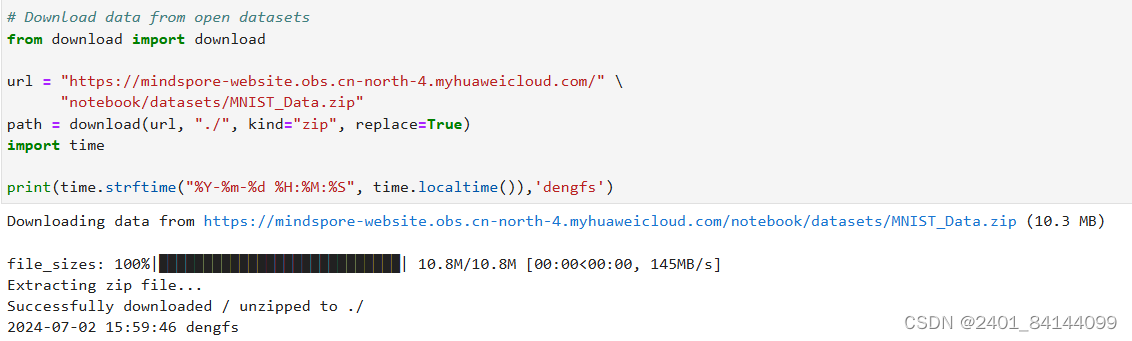
MNIST数据集目录结构如下:
MNIST_Data
└── train
├── train-images-idx3-ubyte (60000个训练图片)
├── train-labels-idx1-ubyte (60000个训练标签)
└── test
├── t10k-images-idx3-ubyte (10000个测试图片)
├── t10k-labels-idx1-ubyte (10000个测试标签)
数据下载完成后,获得数据集对象。
 示例代码:
示例代码:
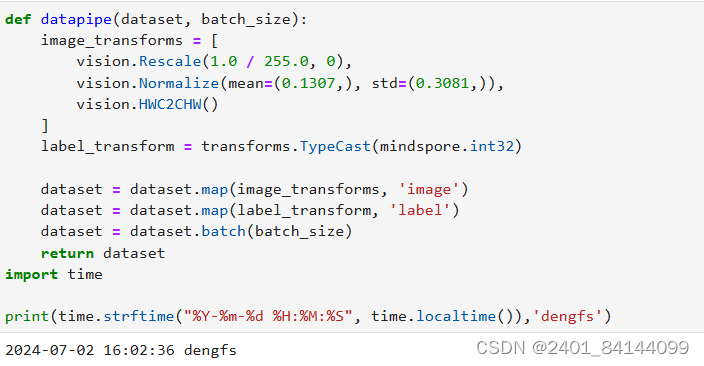 # Map vision transforms and batch dataset(数据类型转换)
# Map vision transforms and batch dataset(数据类型转换)
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
可使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问,查看数据和标签的shape和datatype。
create_tuple_iterator

create_dict_iterator
 这两种的区别只是写法格式不一样,效果是一样的
这两种的区别只是写法格式不一样,效果是一样的
网络构建
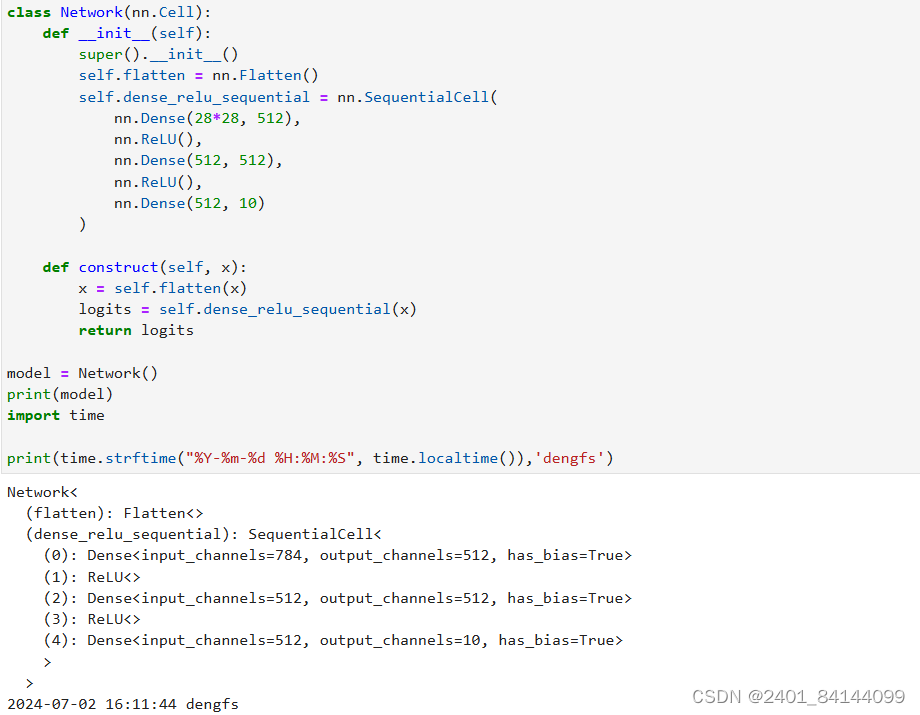
mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。__init__包含所有网络层的定义,construct中包含数据(Tensor)的变换过程。
定义网络模型
模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
- 定义正向计算函数。
- 使用value_and_grad通过函数变换获得梯度计算函数。
- 定义训练函数,使用set_train设置为训练模式,执行正向计算、反向传播和参数优化。
实例化损失函数和优化器
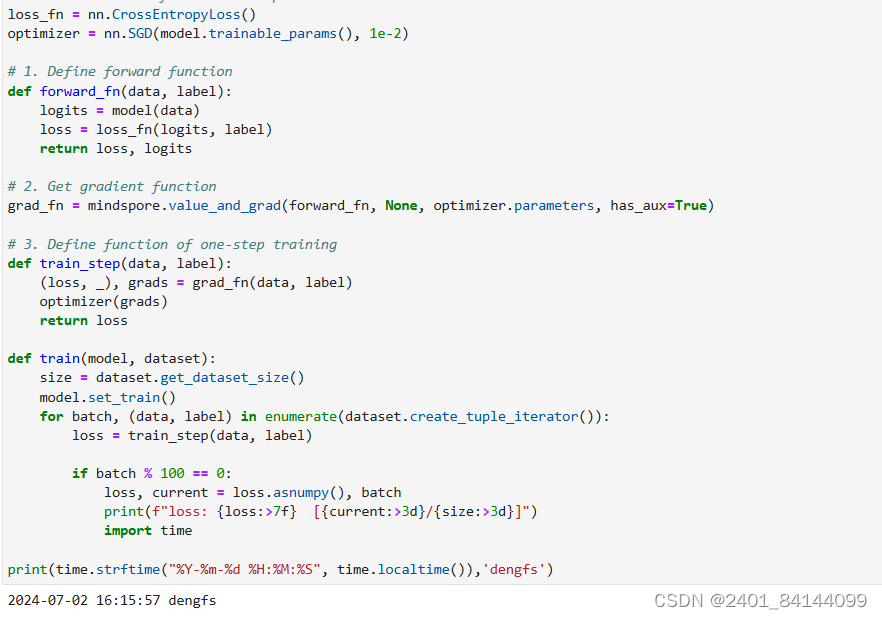 定义测试函数评估模型的性能
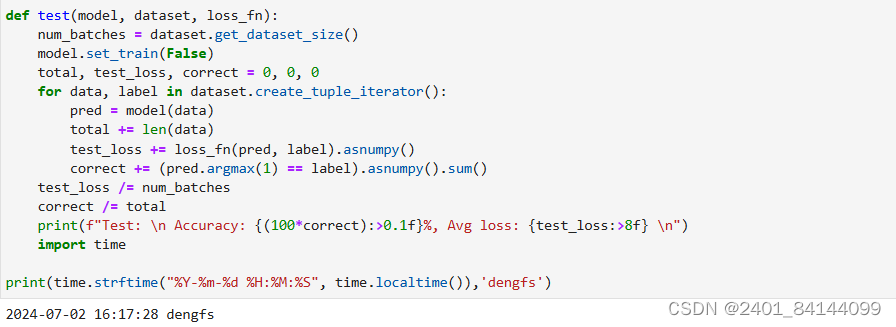
定义测试函数评估模型的性能
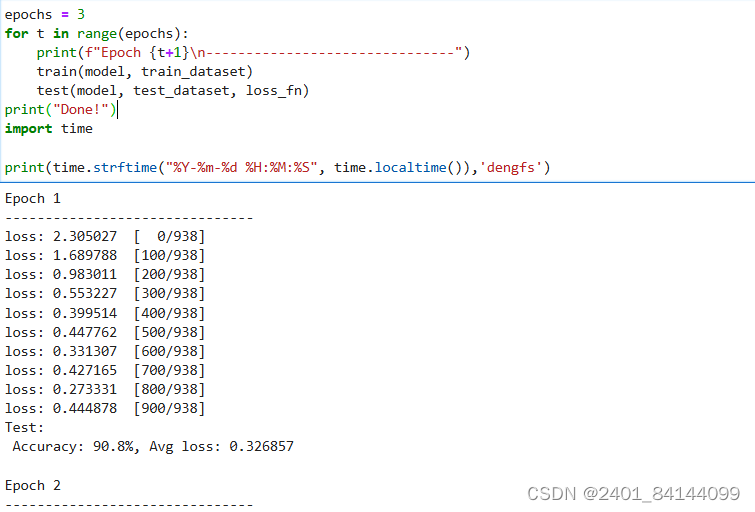
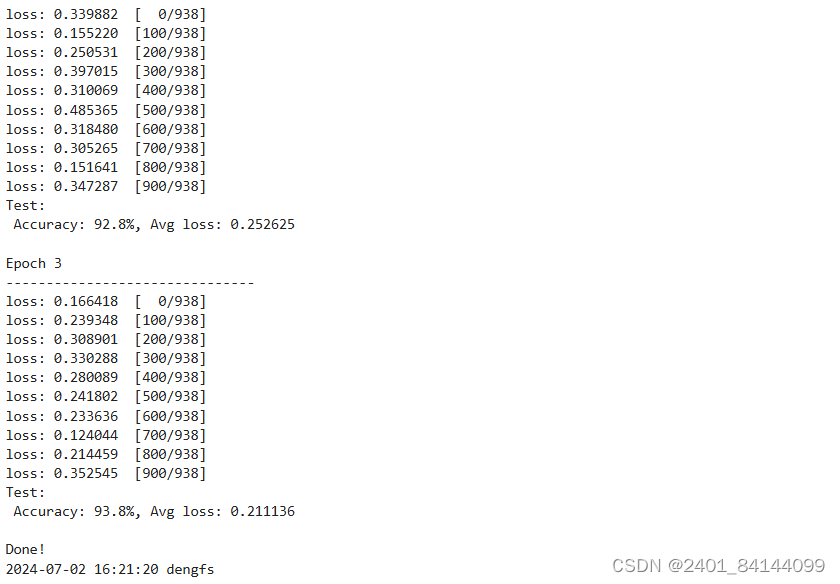
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
保存模型
模型训练完成后,需要将其参数进行保存。
加载模型
加载保存的权重分为两步:
- 重新实例化模型对象,构造模型。
- 加载模型参数,并将其加载至模型上。
实例化一个随机初始化的模型

param_not_load是未被加载的参数列表,为空时代表所有参数均加载成功。
预测推理
 今天的干活分享大家一定收获满满,更进一步加深了深度学习框架的印象,明天我们继续共同进步!
今天的干活分享大家一定收获满满,更进一步加深了深度学习框架的印象,明天我们继续共同进步!















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









