







大家应该都清楚,大家上线app,需要上线各种平台,比如:小米,华为,百度等等等等,我们多数称之为渠道,如果发的渠道多,可能有上百个渠道。
针对每个渠道,我们希望可以获取各个渠道的一些独立的统计信息,比如:下载量等。
那么,如何区分各个渠道呢?
我们需要一个特性的标识符与该渠道对应,这个标识符肯定是要包含在apk中的。那么,我们就要针对每个渠道包去设置一个特定的标识符,然后打一个特定的apk。
这个过程可以手动去完成,每次修改一个字符串,然后手动打包。大家都清楚打包是一个相当耗时的过程,要是打几百个渠道包,这种枯燥重复的任务,当然不是我们所能容忍的。
当然,我们会想到,这样的需求,官方肯定有解决方案。没错,Gradle Plugin为我们提供了一个自动化的方案,我们可以利用占位符,然后在build.gradle中去配置多个渠道信息,这样就可以将枯燥重复的任务自动化了。
这样的方式最大的问题,就是效率问题,每个渠道包,都要执行一遍构建流程。
自动化了,时间依然过长,还是不能忍。
接下来就是寻找高效率的方案了。
因为本文是源码解析,就不饶弯子了~~
目前针对 V1(Android N开始推出了V2),快速的方案,主要有:
主要利用修改apk的目录META-INF中添加空文件,由于不需要重新签名,操作非常快。
- 利用zip文件中的comment的字段,例如VasDolly
后面在解析源码时,会详细说明方式2。
自Android N之后,Google建议使用V2来做签名,因为这样更加安全(对整个apk文件进行hash校验,无法修改apk信息),安装速度也更加高效(无需解析校验单个文件,v1需要单个文件校验hash)。
美团对此动作非常快,立马推出了:
其原理是利用v2的方式在做签名时,在apk中插入了一个签名块(安装时校验apk的hash不包含此块),该快中允许插入一些key-value对,于是将签名插在该区域。
当然,腾讯的VasDolly采取的也是相同的方案。
本文,为VasDolly的源码解析,即会详细分析:
-
针对v1签名方式,利用zip的comment区域
-
针对v2签名方式,利用apk中的签名块中插入key-value
本文不涉及v1,v2具体的签名方式,以及安装时的校验流程,这些内容在:
一文中,说的非常详细。
本文重点是源码的解析。
二、接入VasDolly
其实,接入非常简单,而且readme写的非常详细。
但是为了文章的完整性,简单陈述一下。
根目录build.gradle
buildscript {
dependencies {
classpath ‘com.leon.channel:plugin:1.1.7’
}
}
app的build.gradle
apply plugin: ‘channel’
android {
signingConfigs {
release {
storeFile file(RELEASE_STORE_FILE)
storePassword RELEASE_STORE_PASSWORD
keyAlias RELEASE_KEY_ALIAS
keyPassword RELEASE_KEY_PASSWORD
v1SigningEnabled true
v2SigningEnabled false
}
}
buildTypes {
release {
signingConfig signingConfigs.release
minifyEnabled false
proguardFiles getDefaultProguardFile(‘proguard-android.txt’), ‘proguard-rules.pro’
}
}
channel{
//指定渠道文件
channelFile = file(“/Users/zhanghongyang01/git-repo/learn/VasDollyTest/channel.txt”)
//多渠道包的输出目录,默认为new File(project.buildDir,“channel”)
baseOutputDir = new File(project.buildDir,“channel”)
//多渠道包的命名规则,默认为: a p p N a m e − {appName}- appName−{versionName}- v e r s i o n C o d e − {versionCode}- versionCode−{flavorName}-${buildType}
apkNameFormat =‘ a p p N a m e − {appName}- appName−{versionName}- v e r s i o n C o d e − {versionCode}- versionCode−{flavorName}-${buildType}’
//快速模式:生成渠道包时不进行校验(速度可以提升10倍以上)
isFastMode = true
}
}
dependencies {
api ‘com.leon.channel:helper:1.1.7’
}
首先要apply plugin,然后在android的闭包下写入channel相关信息。
channel中需要制定一个channel.txt文件,其中每行代码一个渠道:
c1
c2
c3
dependencies中的依赖主要是为了获取渠道号的辅助类,毕竟你写入渠道信息的地方这么奇怪,肯定要提供API进行读取渠道号。
注意:我们在signingConfigs的release中配置的是:v1SigningEnabled=true和v2SigningEnabled=false,先看V1方式的快速渠道包。
在Terminal面板执行./gradlew channelRelease执行完成后,即可在app/build/channel/release下看到:
release
├── app-1.0-1-c1-release.apk
├── app-1.0-1-c2-release.apk
└── app-1.0-1-c3-release.apk
注意:本文主要用于讲解源码,如果只需接入,尽可能查看github文档。
三、V1的渠道读取与写入
首先我们需要知道对于V1的签名,渠道信息写在哪?
这里直接白话说明一下,我们的apk实际上就是普通的zip,在一个zip文件的最后允许写入N个字符的注释,我们关注的zip末尾两个部分:
2字节的的注释长度+N个字节的注释。
那么,我们只要把签名内容作为注释写入,再修改2字节的注释长度即可。
现在需要考虑的是我们怎么知道一个apk有没有写入这个渠道信息呢,需要有一个判断的标准:
这时候,魔数这个概念产生了,我们可以在文件文件末尾写入一个特殊的字符串,当我们读取文件末尾为这个特殊的字符串,即可认为该apk写入了渠道信息。
很多文件类型起始部分都包含特性的魔数用于区分文件类型。
最终的渠道信息为:
渠道字符串+渠道字符串长度+魔数
3.1 读取
有了上面的分析,读取就简单了:
-
拿到本地的apk文件
-
读取固定字节与预定义魔数做比对
-
然后再往前读取两个字节为渠道信息长度
-
再根据这个长度往前读取对应字节,即可取出渠道信息。
在看源码之前,我们也可以使用二进制编辑器打开打包好的Apk,看末尾的几个字节,如图:
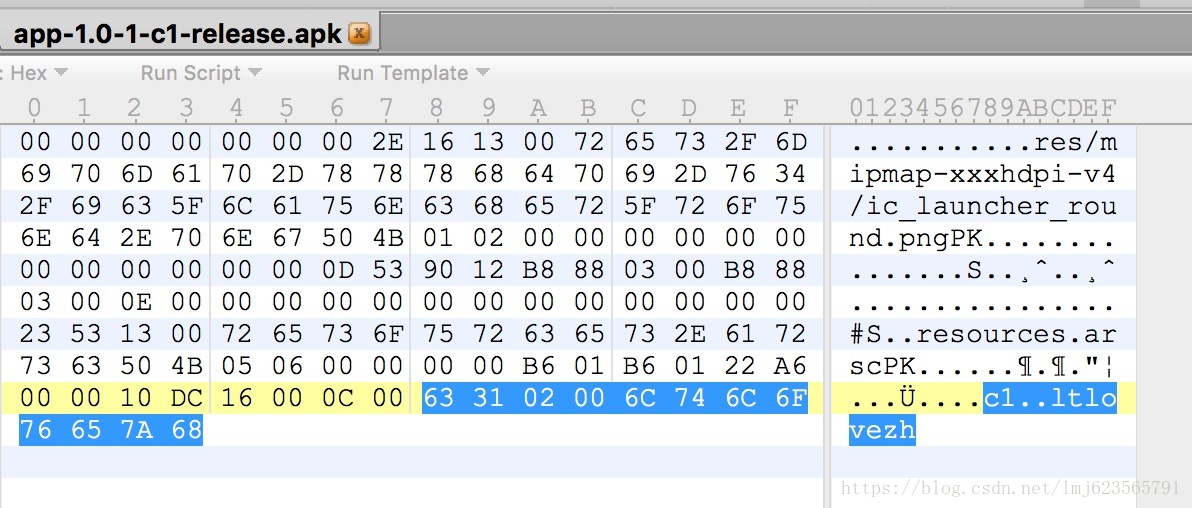
咱们逆着看:
-
首先读取8个字节,对应一个特殊字符串“ltlovezh”
-
往前两个字节为02 00,对应渠道信息长度,实际值为2.
-
再往前读取2个字节为63 31,对照ASCII表,即可知为c1
这样我们就读取除了渠道信息为:c1。
这么看代码也不复杂,最后看一眼代码吧:
代码中通过ChannelReaderUtil.getChannel获取渠道信息:
public static String getChannel(Context context) {
if (mChannelCache == null) {
String channel = getChannelByV2(context);
if (channel == null) {
channel = getChannelByV1(context);
}
mChannelCache = channel;
}
return mChannelCache;
}
我们只看v1,根据调用流程,最终会到:
V1SchemeUtil.readChannel方法:
public static String readChannel(File file) throws Exception {
RandomAccessFile raf = null;
try {
raf = new RandomAccessFile(file, “r”);
long index = raf.length();
byte[] buffer = new byte[ChannelConstants.V1_MAGIC.length];
index -= ChannelConstants.V1_MAGIC.length;
raf.seek(index);
raf.readFully(buffer);
// whether magic bytes matched
if (isV1MagicMatch(buffer)) {
index -= ChannelConstants.SHORT_LENGTH;
raf.seek(index);
// read channel length field
int length = readShort(raf);
if (length > 0) {
index -= length;
raf.seek(index);
// read channel bytes
byte[] bytesComment = new byte[length];
raf.readFully(bytesComment);
return new String(bytesComment, ChannelConstants.CONTENT_CHARSET);
} else {
throw new Exception(“zip channel info not found”);
}
} else {
throw new Exception(“zip v1 magic not found”);
}
} finally {
if (raf != null) {
raf.close();
}
}
}
使用了RandomAccessFile,可以很方便的使用seek指定到具体的字节处。注意第一次seek的目标是length - magic.length,即对应我们的读取魔数,读取到比对是否相同。
如果相同,再往前读取SHORT_LENGTH = 2个字节,读取为short类型,即为渠道信息所占据的字节数。
再往前对去对应的长度,转化为String,即为渠道信息,与我们前面的分析一模一样。
ok,读取始终是简单的。
后面还要看如何写入以及如何自动化。
3.2 写入v1渠道信息
写入渠道信息,先思考下,有个apk,需要写入渠道信息,需要几步:
-
找到合适的写入位置
-
写入渠道信息、写入长度、写入魔数
好像唯一的难点就是找到合适的位置。
但是找到这个合适的位置,又涉及到zip文件的格式内容了。
大致讲解下:
zip的末尾有一个数据库,这个数据块我们叫做EOCD块,分为4个部分:
-
4字节,固定值0x06054b50
-
16个字节,不在乎其细节
-
2个字节,注释长度
-
N个字节,注释内容
知道这个规律后,我们就可以通过匹配1中固定值来确定对应区域,然后seek到注释处。
可能99.99%的apk默认是不包含注释内容的,所以直接往前seek 22个字节,读取4个字节做下匹配即可。
但是如果已经包含了注释内容,就比较难办了。很多时候,我们会正向从头开始按协议读取zip文件格式,直至到达目标区域。
不过VasDolly的做法是,从文件末尾seek 22 ~ 文件size - 22,逐一匹配。
我们简单看下代码:
public static void writeChannel(File file, String channel) throws Exception {
byte[] comment = channel.getBytes(ChannelConstants.CONTENT_CHARSET);
Pair<ByteBuffer, Long> eocdAndOffsetInFile = getEocd(file);
if (eocdAndOffsetInFile.getFirst().remaining() == ZipUtils.ZIP_EOCD_REC_MIN_SIZE) {
System.out.println(“file : " + file.getAbsolutePath() + " , has no comment”);
RandomAccessFile raf = new RandomAccessFile(file, “rw”);
//1.locate comment length field
raf.seek(file.length() - ChannelConstants.SHORT_LENGTH);
//2.write zip comment length (content field length + length field length + magic field length)
writeShort(comment.length + ChannelConstants.SHORT_LENGTH + ChannelConstants.V1_MAGIC.length, raf);
//3.write content
raf.write(comment);
//4.write content length
writeShort(comment.length, raf);
//5. write magic bytes
raf.write(ChannelConstants.V1_MAGIC);
raf.close();
} else {
System.out.println(“file : " + file.getAbsolutePath() + " , has comment”);
if (containV1Magic(file)) {
try {
String existChannel = readChannel(file);
if (existChannel != null){
file.delete();
throw new ChannelExistException("file : " + file.getAbsolutePath() + " has a channel : " + existChannel + “, only ignore”);
}
}catch (Exception e){
e.printStackTrace();
}
}
int existCommentLength = ZipUtils.getUnsignedInt16(eocdAndOffsetInFile.getFirst(), ZipUtils.ZIP_EOCD_REC_MIN_SIZE - ChannelConstants.SHORT_LENGTH);
int newCommentLength = existCommentLength + comment.length + ChannelConstants.SHORT_LENGTH + ChannelConstants.V1_MAGIC.length;
RandomAccessFile raf = new RandomAccessFile(file, “rw”);
//1.locate comment length field
raf.seek(eocdAndOffsetInFile.getSecond() + ZipUtils.ZIP_EOCD_REC_MIN_SIZE - ChannelConstants.SHORT_LENGTH);
//2.write zip comment length (existCommentLength + content field length + length field length + magic field length)
writeShort(newCommentLength, raf);
//3.locate where channel should begin
raf.seek(eocdAndOffsetInFile.getSecond() + ZipUtils.ZIP_EOCD_REC_MIN_SIZE + existCommentLength);
//4.write content
raf.write(comment);
//5.write content length
writeShort(comment.length, raf);
//6.write magic bytes
raf.write(ChannelConstants.V1_MAGIC);
raf.close();
}
}
getEocd(file)的的返回值是Pair<ByteBuffer, Long>,多数情况下first为EOCD块起始位置到结束后的内容;second为EOCD块起始位置。
if为apk本身无comment的情况,这种方式属于大多数情况,从文件末尾,移动2字节,该2字节为注释长度,然后组装注释内容,重新计算注释长度,重新写入注释长度,再写入注释内容,最后写入MAGIC魔数。
else即为本身存在comment的情况,首先读取原有注释长度,然后根据渠道等信息计算出先的注释长度,写入。
3.3 gradle自动化
最后我们看下,是如何做到输入./gradle channelRelease就实现所有渠道包的生成呢。
这里主要就是解析gradle plugin了,如果你还没有自定义过plugin,非常值得参考。
代码主要在VasDolly/plugin这个module.
入口代码为ApkChannelPackagePlugin的apply方法。
主要代码:
project.afterEvaluate {
project.android.applicationVariants.all { variant ->
def variantOutput = variant.outputs.first();
def dirName = variant.dirName;
def variantName = variant.name.capitalize();
Task channelTask = project.task(“channel${variantName}”, type: ApkChannelPackageTask) {
mVariant = variant;
mChannelExtension = mChannelConfigurationExtension;
mOutputDir = new File(mChannelConfigurationExtension.baseOutputDir, dirName)
mChannelList = mChanneInfolList
dependsOn variant.assemble
}
}
}
为每个variantName添加了一个task,并且依赖于variant.assemble。
也就是说,当我们执行./gradlew channelRelease时,会先执行assemble,然后对产物apk做后续操作。
重点看这个Task,ApkChannelPackageTask。
执行代码为:
@TaskAction
public void channel() {
//1.check all params
checkParameter();
//2.check signingConfig , determine channel package mode
checkSigningConfig()
//3.generate channel apk
generateChannelApk();
}
注释也比较清晰,首先channelFile、baseOutputDir等相关参数。接下来校验signingConfig中v2SigningEnabled与v1SigningEnabled,确定使用V1还是V2 mode,我们上文中将v2SigningEnabled设置为了false,所以这里为V1_MODE。
最后就是生成渠道apk了:
void generateV1ChannelApk() {
// 省略了一些代码
mChannelList.each { channel ->
String apkChannelName = getChannelApkName(channel)
println “generateV1ChannelApk , channel = ${channel} , apkChannelName = ${apkChannelName}”
File destFile = new File(mOutputDir, apkChannelName)
copyTo(mBaseApk, destFile)
V1SchemeUtil.writeChannel(destFile, channel)
if (!mChannelExtension.isFastMode){
//1. verify channel info
if (V1SchemeUtil.verifyChannel(destFile, channel)) {
println(“generateV1ChannelApk , ${destFile} add channel success”)
} else {
throw new GradleException(“generateV1ChannelApk , ${destFile} add channel failure”)
}
//2. verify v1 signature
if (VerifyApk.verifyV1Signature(destFile)) {
println “generateV1ChannelApk , after add channel , apk ${destFile} v1 verify success”
} else {
throw new GradleException(“generateV1ChannelApk , after add channel , apk ${destFile} v1 verify failure”)
}
}
}
println(“------ p r o j e c t . n a m e : {project.name}: project.name:{name} generate v1 channel apk , end ------”)
}
很简单,遍历channelList,然后调用V1SchemeUtil.writeChannel,该方法即我们上文解析过的方法。
如果fastMode设置为false,还会读取出渠道再做一次强校验;以及会通过apksig做对签名进行校验。
ok,到这里我们就完全剖析了基于V1的快速签名的全过程。
接下来我们看基于v2的快速签名方案。
四、基于V2的快速签名方案
关于V2签名的产生原因,原理以及安装时的校验过程可以参考 VasDolly实现原理。
我这里就抛开细节,尽可能让大家能明白整个过程,v2签名的原理可以简单理解为:
-
我们的apk其实是个zip,我们可以理解为3块:块1+块2+块3
-
签名让我们的apk变成了4部分:块1+签名块+块2+块3
在这个签名块的某个区域,允许我们写一些key-value对,我们就将渠道信息写在这个地方。
这里有一个问题,v2不是说是对整个apk进行校验吗?为什么还能够让我们在apk中插入这样的信息呢?
因为在校验过程中,对于签名块是不校验的(细节上由于我们插入了签名块,某些偏移量会变化,但是在校验前,Android系统会先重置偏移量),而我们的渠道信息刚好写在这个签名块中。
好了,细节一会看代码。
4.1 读取渠道信息
写入渠道信息,根据我们上述的分析,流程应该大致如下:
-
找到签名块
-
找到签名块中的key-value的地方
-
读取出所有的key-value,找到我们特定的key对应的渠道信息
这里我们不按照整个代码流程走了,太长了,一会看几段关键代码。
4.1.1 如何找到签名块
我们的apk现在格式是这样的:
块1+签名块+块2+块3
其中块3称之为EOCD,现在必须要展示下其内部的数据结构了:

图片来自:参考
在V1的相关代码中,我们已经可以定位到EOCD的位置了,然后往下16个字节即可拿到Offset of start of central directory即为块2开始的位置,也为签名块末尾的位置。
块2 再往前,就可以获取到我们的 签名块了。
我们先看一段代码,定位到 块2 的开始位置。
V2SchemeUtil
public static ByteBuffer getApkSigningBlock(File channelFile) throws ApkSignatureSchemeV2Verifier.SignatureNotFoundException, IOException {
RandomAccessFile apk = new RandomAccessFile(channelFile, “r”);
//1.find the EOCD
Pair<ByteBuffer, Long> eocdAndOffsetInFile = ApkSignatureSchemeV2Verifier.getEocd(apk);
ByteBuffer eocd = eocdAndOffsetInFile.getFirst();
long eocdOffset = eocdAndOffsetInFile.getSecond();
if (ZipUtils.isZip64EndOfCentralDirectoryLocatorPresent(apk, eocdOffset)) {
throw new ApkSignatureSchemeV2Verifier.SignatureNotFoundException(“ZIP64 APK not supported”);
}
//2.find the APK Signing Block. The block immediately precedes the Central Directory.
long centralDirOffset = ApkSignatureSchemeV2Verifier.getCentralDirOffset(eocd, eocdOffset);//通过eocd找到中央目录的偏移量
//3. find the apk V2 signature block
Pair<ByteBuffer, Long> apkSignatureBlock =
ApkSignatureSchemeV2Verifier.findApkSigningBlock(apk, centralDirOffset);//找到V2签名块的内容和偏移量
return apkSignatureBlock.getFirst();
}
首先发现EOCD块,这个前面我们已经分析了。
然后寻找到签名块的位置,上面我们已经分析了只要往下移动16字节即可到达签名块末尾 ,那么看下ApkSignatureSchemeV2Verifier.getCentralDirOffset代码,最终调用:
public static long getZipEocdCentralDirectoryOffset(ByteBuffer zipEndOfCentralDirectory) {
assertByteOrderLittleEndian(zipEndOfCentralDirectory);
return getUnsignedInt32(
zipEndOfCentralDirectory,
zipEndOfCentralDirectory.position() + 16);
}
到这里我们已经可以到达签名块末尾了。
我们继续看findApkSigningBlock找到V2签名块的内容和偏移量:
public static Pair<ByteBuffer, Long> findApkSigningBlock(
RandomAccessFile apk, long centralDirOffset)
throws IOException, SignatureNotFoundException {
ByteBuffer footer = ByteBuffer.allocate(24);
footer.order(ByteOrder.LITTLE_ENDIAN);
apk.seek(centralDirOffset - footer.capacity());
apk.readFully(footer.array(), footer.arrayOffset(), footer.capacity());
if ((footer.getLong(8) != APK_SIG_BLOCK_MAGIC_LO)
|| (footer.getLong(16) != APK_SIG_BLOCK_MAGIC_HI)) {
throw new SignatureNotFoundException(
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则近万的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Android)

学习福利
【Android 详细知识点思维脑图(技能树)】

其实Android开发的知识点就那么多,面试问来问去还是那么点东西。所以面试没有其他的诀窍,只看你对这些知识点准备的充分程度。so,出去面试时先看看自己复习到了哪个阶段就好。
虽然 Android 没有前几年火热了,已经过去了会四大组件就能找到高薪职位的时代了。这只能说明 Android 中级以下的岗位饱和了,现在高级工程师还是比较缺少的,很多高级职位给的薪资真的特别高(钱多也不一定能找到合适的),所以努力让自己成为高级工程师才是最重要的。
这里附上上述的面试题相关的几十套字节跳动,京东,小米,腾讯、头条、阿里、美团等公司19年的面试题。把技术点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节。
由于篇幅有限,这里以图片的形式给大家展示一小部分。

网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。希望这份系统化的技术体系对大家有一个方向参考。
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
3)]
[外链图片转存中…(img-j9RyoJpM-1713601270154)]
[外链图片转存中…(img-FAZM09NB-1713601270155)]
[外链图片转存中…(img-Yjs4VVQL-1713601270157)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Android)
学习福利
【Android 详细知识点思维脑图(技能树)】
[外链图片转存中…(img-yuZdLOM7-1713601270158)]
其实Android开发的知识点就那么多,面试问来问去还是那么点东西。所以面试没有其他的诀窍,只看你对这些知识点准备的充分程度。so,出去面试时先看看自己复习到了哪个阶段就好。
虽然 Android 没有前几年火热了,已经过去了会四大组件就能找到高薪职位的时代了。这只能说明 Android 中级以下的岗位饱和了,现在高级工程师还是比较缺少的,很多高级职位给的薪资真的特别高(钱多也不一定能找到合适的),所以努力让自己成为高级工程师才是最重要的。
这里附上上述的面试题相关的几十套字节跳动,京东,小米,腾讯、头条、阿里、美团等公司19年的面试题。把技术点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节。
由于篇幅有限,这里以图片的形式给大家展示一小部分。
[外链图片转存中…(img-BpIfEpN0-1713601270159)]
网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。希望这份系统化的技术体系对大家有一个方向参考。
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 4192
4192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









