







3.修改配置文件
cp celeborn-env.sh.template celeborn-env.sh
cp log4j2.xml.template log4j2.xml
cp celeborn-defaults.conf.template cp celeborn-defaults.conf
3.1修改celeborn-env.sh
CELEBORN_MASTER_MEMORY=2g
CELEBORN_WORKER_MEMORY=2g
CELEBORN_WORKER_OFFHEAP_MEMORY=4g
3.2 修改celeborn-defaults.conf
# used by client and worker to connect to master
celeborn.master.endpoints 10.67.78.xx:9097
# used by master to bootstrap
celeborn.master.host 10.67.78.xx
celeborn.master.port 9097
celeborn.metrics.enabled true
celeborn.worker.flusher.buffer.size 256k
# If Celeborn workers have local disks and HDFS. Following configs should be added.
# If Celeborn workers have local disks, use following config.
# Disk type is HDD by defaut.
#celeborn.worker.storage.dirs /mnt/disk1:disktype=SSD,/mnt/disk2:disktype=SSD
# If Celeborn workers don't have local disks. You can use HDFS.
# Do not set `celeborn.worker.storage.dirs` and use following configs.
celeborn.storage.activeTypes HDFS
celeborn.worker.sortPartition.threads 64
celeborn.worker.commitFiles.timeout 240s
celeborn.worker.commitFiles.threads 128
celeborn.master.slot.assign.policy roundrobin
celeborn.rpc.askTimeout 240s
celeborn.worker.flusher.hdfs.buffer.size 4m
celeborn.storage.hdfs.dir hdfs://10.67.78.xx:8020/celeborn
celeborn.worker.replicate.fastFail.duration 240s
# If your hosts have disk raid or use lvm, set celeborn.worker.monitor.disk.enabled to false
celeborn.worker.monitor.disk.enabled false
4.复制到其他节点
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx1:/root/
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx2:/root/
因为在配置文件中已经配置了master 所以启动matster和worker即可。
5.启动master和worker
cd $CELEBORN_HOME
./sbin/start-master.sh
./sbin/start-worker.sh celeborn://<Master IP>:<Master Port>
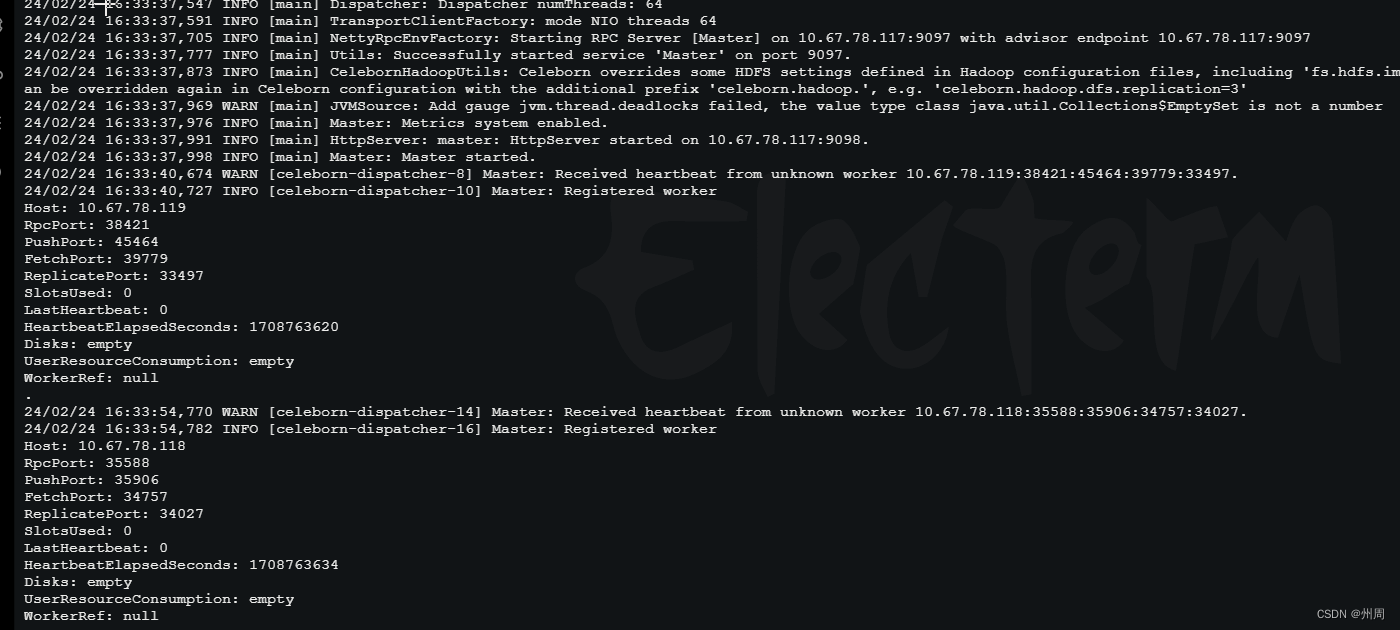
之后在master的日志中看woker是否注册上
6.在 spark客户端使用
复制 KaTeX parse error: Undefined control sequence: \* at position 22: …RN\_HOME/spark/\̲*̲.jar 到 SPARK_HOME/jars/
修改spark-defaults.conf
# Shuffle manager class name changed in 0.3.0:
# before 0.3.0: org.apache.spark.shuffle.celeborn.RssShuffleManager
# since 0.3.0: org.apache.spark.shuffle.celeborn.SparkShuffleManager
spark.shuffle.manager org.apache.spark.shuffle.celeborn.SparkShuffleManager
# must use kryo serializer because java serializer do not support relocation
spark.serializer org.apache.spark.serializer.KryoSerializer
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**





**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**

**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
1qZzmXRV-1712951451368)]
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









