







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

2. 计算标准化样本查的协方差矩阵:
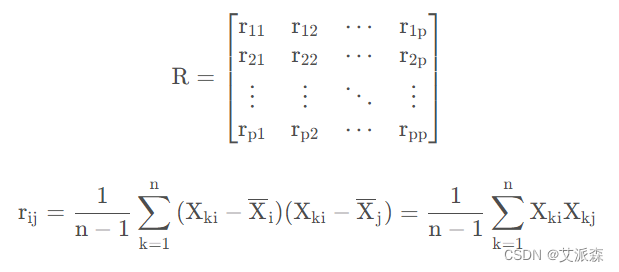
1、2步骤可以合成一步:

4. 计算主成分共享率以及累计贡献率:

5. 写出主成分:

6. 根据系数分析主成分代表的意义:
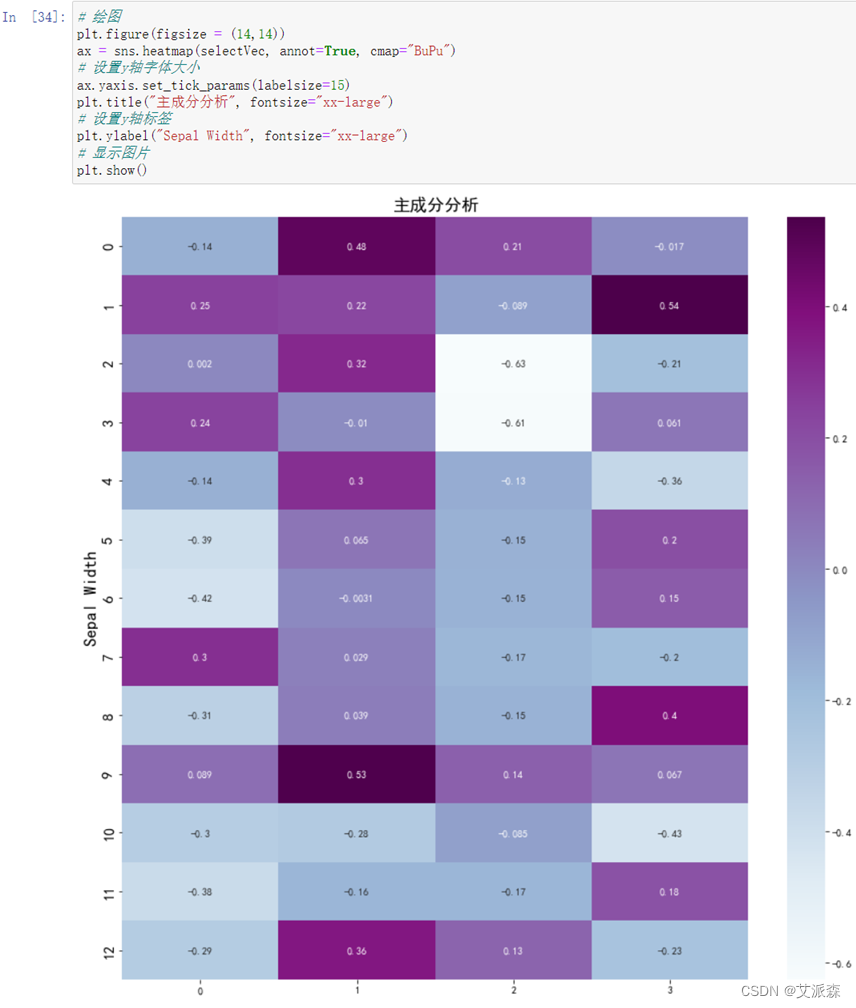
对于某个主成分而言,指标前面的系数越大,代表该指标对于该主成分的影响越大。
部分说明
一组数据是否可以用主成分分析,必须做适合性检验。可以用球形检验和KMO统计量检验。
1)球形检验(Bartlett)
球形检验的假设:
H0:相关系数矩阵为单位阵(即变量不相关)
H1:相关系数矩阵不是单位阵(即变量间有相关关系)
2)KMO(Kaiser-Meyer-Olkin)统计量
KMO统计量比较样本相关系数与样本偏相关系数,它用于检验样本是否适于作主成分分析。
KMO的值在0,1之间,该值越大,则样本数据越适合作主成分分析和因子分析。一般要求该值大于0.5,方可作主成分分析或者相关分析。
Kaiser在1974年给出了经验原则:
0.9以上 适合性很好
0.8~0.9 适合性良好
0.7~0.8 适合性中等
0.6~0.7 适合性一般
0.5~0.6 适合性不好
0.5以下 不能接受的
4.实验过程
4.1数据探索
加载葡萄酒数据集
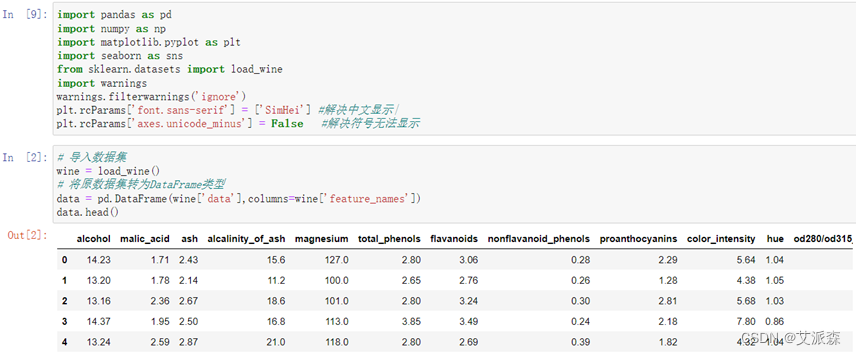
使用shape属性查看数据共有多少行多少列
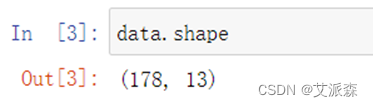
原数据有178行,13列
使用info()查看基本信息
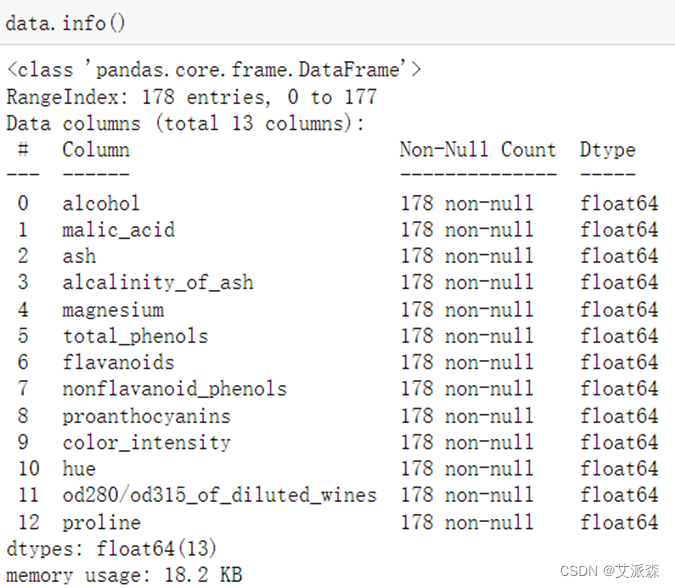
从结果中可以看出数据集没有缺失值且都为浮点数类型。
4.2 PCA主成分分析
**1.**巴特利球形检验
检验总体变量的相关矩阵是否是单位阵(相关系数矩阵对角线的所有元素均为1,所有非对角线上的元素均为零);即检验各个变量是否各自独立。
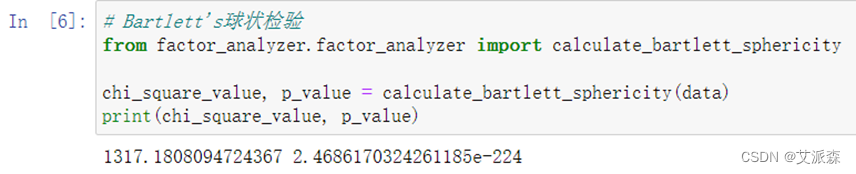
从结果中看出P值远小于0.05,拒绝原假设,说明变量之间有相关关系,可以做主成分分析。
**2.**求相关矩阵
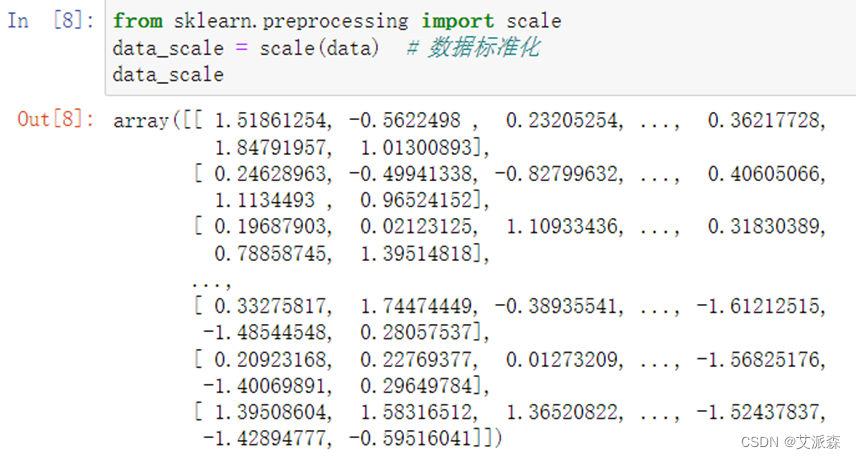
①标准化
②求相关系数矩阵
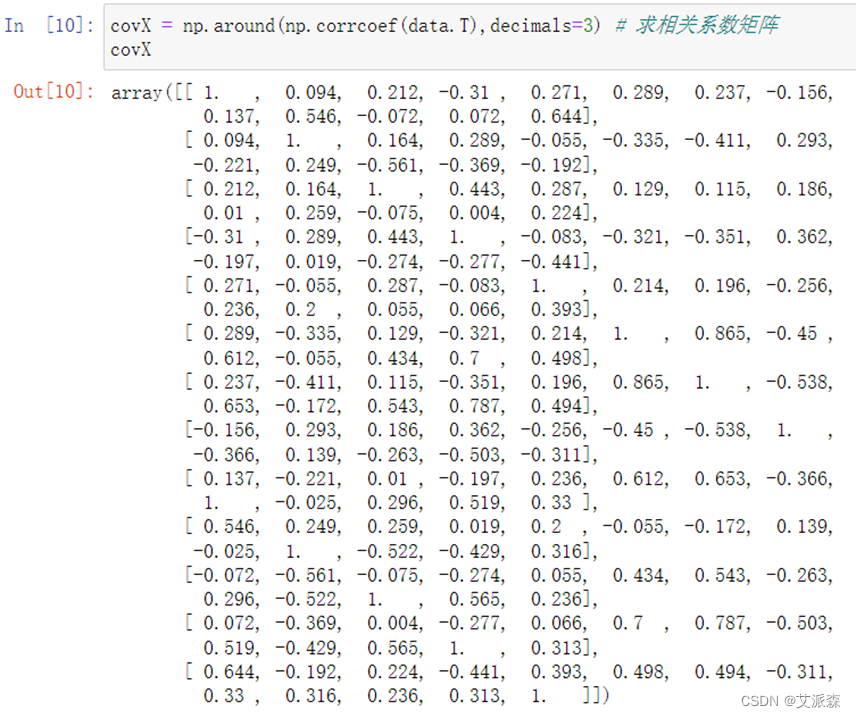
③求特征值和特征向量

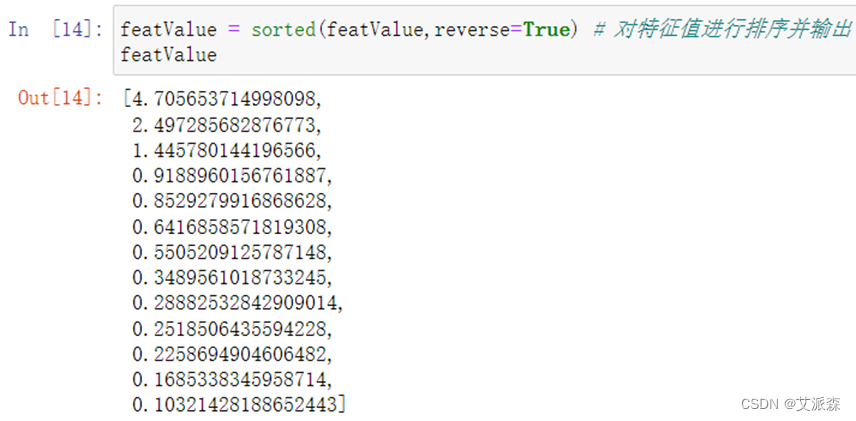
**3.**对特征值进行排序并输出
**4.**绘制散点图和折线图
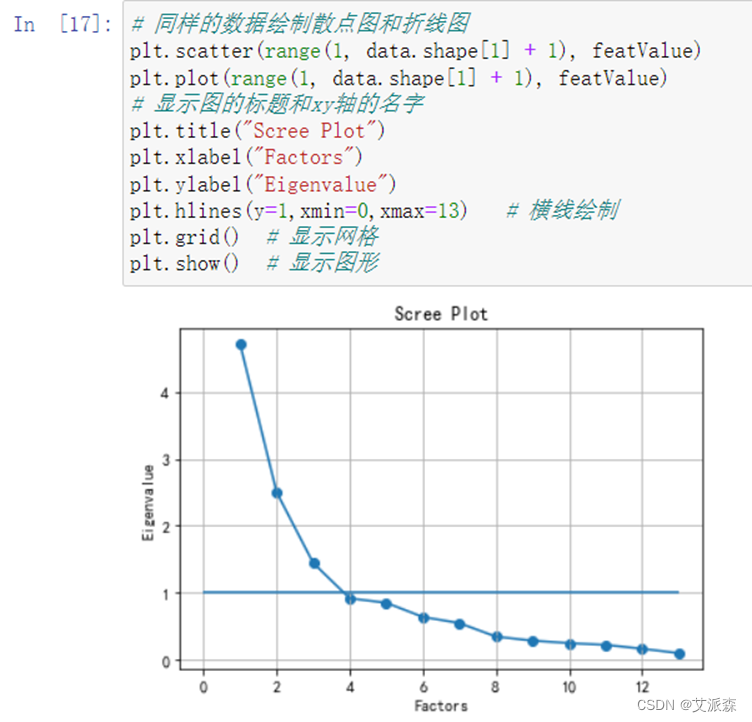
从图中得出主成分分析的K值应为4比较好。
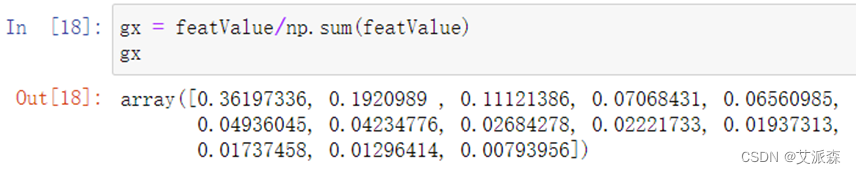
**5.**求特征值的贡献度
**6.**求特征值的累计贡献度
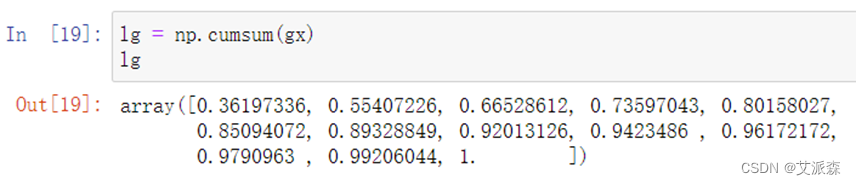
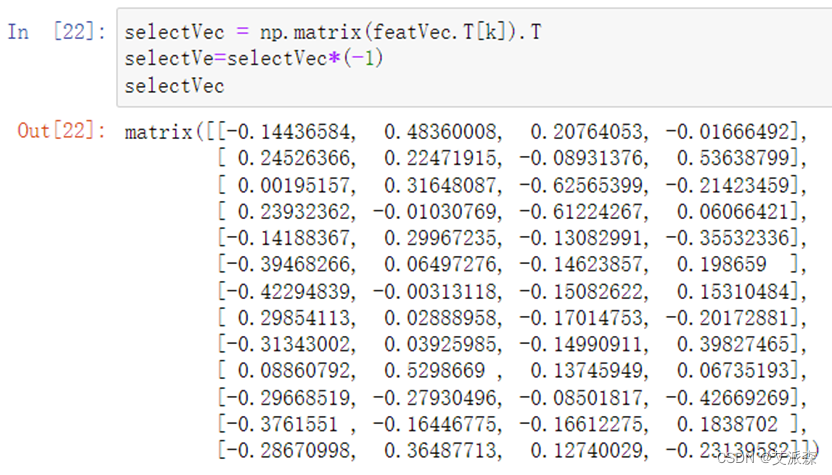
**7.**选出主成分

**8.**选出主成分对应的特征向量矩阵
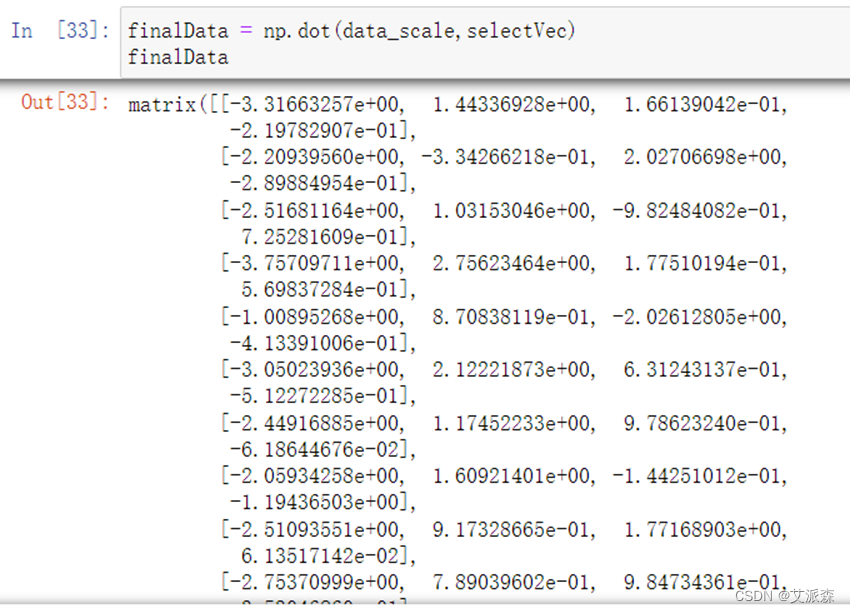
**9.**求主成分得分
**10.**绘制热力图
4.3 构建模型
在构建模型之前,先进行特征选择,选出建模需要的数据(这里先使用经过主成分分析后的数据),再拆分数据集为训练集和测试集。

构建随机森林模型
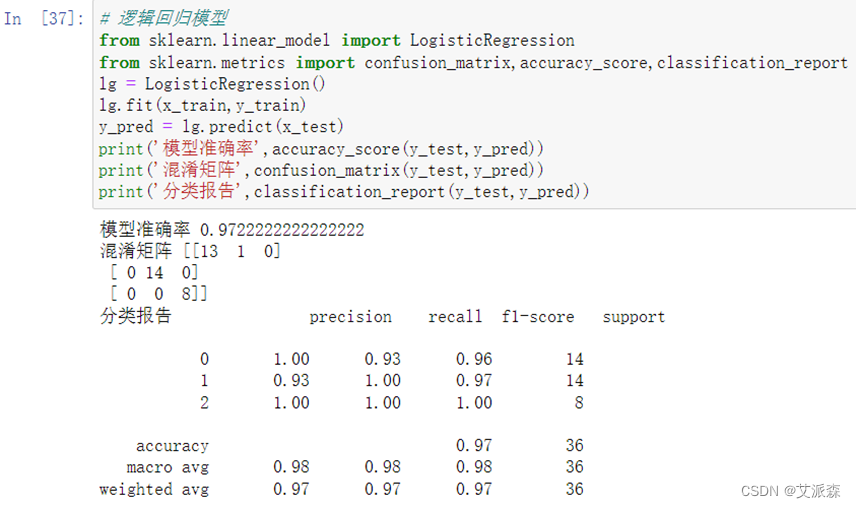
可以看出经过主成分分析后的模型准确率为0.972。
接着我们使用原始数据,也就是没有经过主成分分析处理的数据来构建模型看看效果。
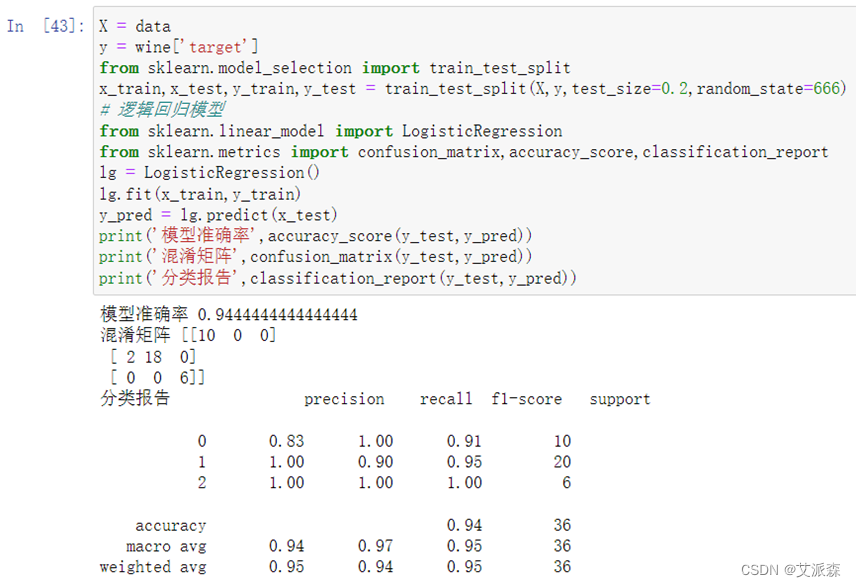
从结果看出没有经过主成分分析处理的数据最后构建的模型准确率为0.944,明显看出经过主成分分析处理的模型准确率提高了不少。
5.总结
本次实验对葡萄酒数据进行了主成分分析,将13维的数据降到了4维,最后通过构建逻辑回归分类模型得出的模型准确率为0.97,相比于没有经过主成分分析处理的数据构建的模型而言,经过处理后的数据构建的模型准确率提高了3%,说明本次主成分分析是有效果的,最后构建的模型效果也很不错。
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_wine
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示|
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
# 导入数据集
wine = load_wine()
# 将原数据集转为DataFrame类型
data = pd.DataFrame(wine['data'],columns=wine['feature_names'])
data.head()
data.shape
data.info()
# Bartlett's球状检验
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(data)
print(chi_square_value, p_value)
# KMO检验
# 检查变量间的相关性和偏相关性,取值在0-1之间;KOM统计量越接近1,变量间的相关性越强,偏相关性越弱,因子分析的效果越好。
# 通常取值从0.6开始进行因子分析
from factor_analyzer.factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(data)
print(kmo_all)
from sklearn.preprocessing import scale
data_scale = scale(data) # 数据标准化
data_scale
covX = np.around(np.corrcoef(data.T),decimals=3) # 求相关系数矩阵
covX
featValue, featVec= np.linalg.eig(covX.T) #求解系数相关矩阵的特征值和特征向量
featValue, featVec
featValue = sorted(featValue,reverse=True) # 对特征值进行排序并输出
featValue
# 同样的数据绘制散点图和折线图
plt.scatter(range(1, data.shape[1] + 1), featValue)
plt.plot(range(1, data.shape[1] + 1), featValue)
# 显示图的标题和xy轴的名字
plt.title("Scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.hlines(y=1,xmin=0,xmax=13) # 横线绘制
plt.grid() # 显示网格
plt.show() # 显示图形
gx = featValue/np.sum(featValue)
gx
lg = np.cumsum(gx)
lg
#选出主成分
k=[i for i in range(len(lg)) if lg[i]<0.80]
k = list(k)
print(k)
selectVec = np.matrix(featVec.T[k]).T
selectVe=selectVec*(-1)
selectVec
finalData = np.dot(data_scale,selectVec)
finalData
# 绘图
plt.figure(figsize = (14,14))



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
[外链图片转存中...(img-jhdnRdik-1715463400929)]
[外链图片转存中...(img-XMEouqUR-1715463400930)]
[外链图片转存中...(img-ZOVAKhce-1715463400930)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**















 1527
1527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









