







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
package cn.oldlut.spark.app.mock
/\*\*
\* 用户百度搜索时日志数据封装样例类CaseClass
\* <p>
\*
\* @param sessionId 会话ID
\* @param ip IP地址
\* @param datetime 搜索日期时间
\* @param keyword 搜索关键词
\*/
case class SearchLog(
sessionId: String, //
ip: String, //
datetime: String, //
keyword: String //
) {
override def toString: String = s"$sessionId,$ip,$datetime,$keyword"
}
`` `
模拟产生搜索日志数据类 【 MockSearchLogs 】 具体代码如下 :
`` `
package cn.oldlut.spark.app.mock
import java.util.{Properties, UUID}
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import scala.util.Random
/\*\*
\* 模拟产生用户使用百度搜索引擎时,搜索查询日志数据,包含字段为:
\* uid, ip, search\_datetime, search\_keyword
\*/
object MockSearchLogs {
def main(args: Array[String]): Unit = {
// 搜索关键词,直接到百度热搜榜获取即可
val keywords: Array[String] = Array("罗志祥", "谭卓疑", "当当网", "裸海蝶", "张建国")
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "node1.oldlut.cn:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val random: Random = new Random()
while (true) {
// 随机产生一条搜索查询日志
val searchLog: SearchLog = SearchLog(
getUserId(), //
getRandomIp(), //
getCurrentDateTime(), //
keywords(random.nextInt(keywords.length)) //
)
println(searchLog.toString)
Thread.sleep(10 + random.nextInt(100))
val record = new ProducerRecord[String, String]("search-log-topic", searchLog.toString)
producer.send(record)
}
// 关闭连接
producer.close()
}
/\*\*
\* 随机生成用户SessionId
\*/
def getUserId(): String = {
val uuid: String = UUID.randomUUID().toString
uuid.replaceAll("-", "").substring(16)
}
/\*\*
\* 获取当前日期时间,格式为yyyyMMddHHmmssSSS
\*/
def getCurrentDateTime(): String = {
val format = FastDateFormat.getInstance("yyyyMMddHHmmssSSS")
val nowDateTime: Long = System.currentTimeMillis()
format.format(nowDateTime)
}
/\*\*
\* 获取随机IP地址
\*/
def getRandomIp(): String = {
// ip范围
val range: Array[(Int, Int)] = Array(
(607649792, 608174079), //36.56.0.0-36.63.255.255
(1038614528, 1039007743), //61.232.0.0-61.237.255.255
(1783627776, 1784676351), //106.80.0.0-106.95.255.255
(2035023872, 2035154943), //121.76.0.0-121.77.255.255
(2078801920, 2079064063), //123.232.0.0-123.235.255.255
(-1950089216, -1948778497), //139.196.0.0-139.215.255.255
(-1425539072, -1425014785), //171.8.0.0-171.15.255.255
(-1236271104, -1235419137), //182.80.0.0-182.92.255.255
(-770113536, -768606209), //210.25.0.0-210.47.255.255
(-569376768, -564133889) //222.16.0.0-222.95.255.255
)
// 随机数:IP地址范围下标
val random = new Random()
val index = random.nextInt(10)
val ipNumber: Int = range(index)._1 + random.nextInt(range(index)._2 - range(index)._1)
//println(s"ipNumber = ${ipNumber}")
// 转换Int类型IP地址为IPv4格式
number2IpString(ipNumber)
}
/\*\*
\* 将Int类型IPv4地址转换为字符串类型
\*/
def number2IpString(ip: Int): String = {
val buffer: Array[Int] = new Array[Int](4)
buffer(0) = (ip >> 24) & 0xff
buffer(1) = (ip >> 16) & 0xff
buffer(2) = (ip >> 8) & 0xff
buffer(3) = ip & 0xff
// 返回IPv4地址
buffer.mkString(".")
}
}
运行应用程序,源源不断产生日志数据,发送至Kafka(同时在控制台打印),截图如下: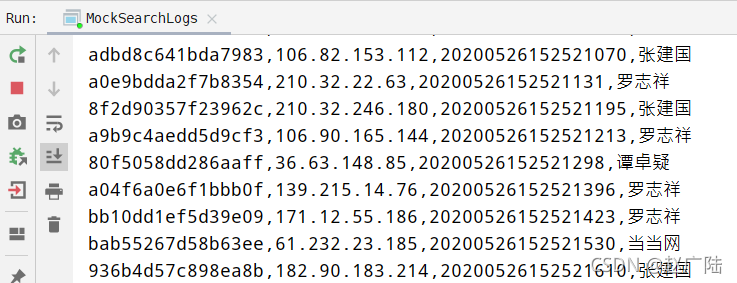
2.3 StreamingContextUtils 工具类
所有SparkStreaming应用都需要构建StreamingContext实例对象,并且从采用New KafkaConsumer API消费Kafka数据,编写工具类【StreamingContextUtils】,提供两个方法:
- 方法一:getStreamingContext,获取StreamingContext实例对象

- 方法二:consumerKafka,消费Kafka Topic中数据

具体代码如下:
package cn.oldlut.spark.app
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/\*\*
\* 工具类提供:构建流式应用上下文StreamingContext实例对象和从Kafka Topic消费数据
\*/
object StreamingContextUtils {
/\*\*
\* 获取StreamingContext实例,传递批处理时间间隔
\*
\* @param batchInterval 批处理时间间隔,单位为秒
\*/
def getStreamingContext(clazz: Class[_], batchInterval: Int): StreamingContext = {
// i. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(clazz.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// 设置Kryo序列化
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[ConsumerRecord[String, String]]))
// ii.创建流式上下文对象, 传递SparkConf对象和时间间隔
val context = new StreamingContext(sparkConf, Seconds(batchInterval))
// iii. 返回
context
}
/\*\*
\* 从指定的Kafka Topic中消费数据,默认从最新偏移量(largest)开始消费
\*
\* @param ssc StreamingContext实例对象
\* @param topicName 消费Kafka中Topic名称
\*/
def consumerKafka(ssc: StreamingContext, topicName: String): DStream[ConsumerRecord[String, String]] = {
// i.位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// ii.读取哪些Topic数据
val topics = Array(topicName)
// iii.消费Kafka 数据配置参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1.oldlut.cn:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group\_id\_streaming\_0001",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// iv.消费数据策略
val consumerStrategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe(
topics, kafkaParams
)
// v.采用新消费者API获取数据,类似于Direct方式
val kafkaDStream: DStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc, locationStrategy, consumerStrategy
)
// vi.返回DStream
kafkaDStream
}
}
3 实时数据ETL存储
实时从Kafka Topic消费数据,提取ip地址字段,调用【ip2Region】库解析为省份和城市,存储到HDFS文件中,设置批处理时间间隔BatchInterval为10秒,完整代码如下:
package cn.oldlut.spark.app.etl
import cn.oldlut.spark.app.StreamingContextUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.lionsoul.ip2region.{DataBlock, DbConfig, DbSearcher}
/\*\*
\* 实时消费Kafka Topic数据,经过ETL(过滤、转换)后,保存至HDFS文件系统中,BatchInterval为:10s
\*/
object StreamingETLHdfs {
def main(args: Array[String]): Unit = {
// 1. 获取StreamingContext实例对象
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 10)
// 2. 从Kafka消费数据,使用Kafka New Consumer API
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils
.consumerKafka(ssc, "search-log-topic")
// 3. 数据ETL:过滤不合格数据及转换IP地址为省份和城市,并存储HDFS上
kafkaDStream.foreachRDD { (rdd, time) =>
// i. message不为null,且分割为4个字段
val kafkaRDD: RDD[ConsumerRecord[String, String]] = rdd.filter { record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// ii. 解析IP地址
val etlRDD: RDD[String] = kafkaRDD.mapPartitions { iter =>
// 创建DbSearcher对象,针对每个分区创建一个,并不是每条数据创建一个
val dbSearcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
iter.map { record =>
val Array(_, ip, _, _) = record.value().split(",")
// 依据IP地址解析
val dataBlock: DataBlock = dbSearcher.btreeSearch(ip)
val region: String = dataBlock.getRegion
val Array(_, _, province, city, _) = region.split("\\|")
// 组合字符串
s"${record.value()},$province,$city"
}
}
// iii. 保存至文件
val savePath = s"datas/streaming/etl/search-log-${time.milliseconds}"
if (!etlRDD.isEmpty()) {
etlRDD.coalesce(1).saveAsTextFile(savePath)
}
}
// 4.启动流式应用,一直运行,直到程序手动关闭或异常终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
运行模拟日志数据程序和ETL应用程序,查看实时数据ETL后保存文件,截图如下:
4 实时状态更新统计
实 时 累 加 统 计 用 户 各 个 搜 索 词 出 现 的 次 数 , 在 SparkStreaming 中 提 供 函 数【updateStateByKey】实现累加统计,Spark 1.6提供【mapWithState】函数状态统计,性能更好,实际应用中也推荐使用。
4.1 updateStateByKey 函数
状态更新函数【updateStateByKey】表示依据Key更新状态,要求DStream中数据类型为【Key/Value】对二元组,函数声明如下:

将每批次数据状态,按照Key与以前状态,使用定义函数【updateFunc】进行更新,示意图如下: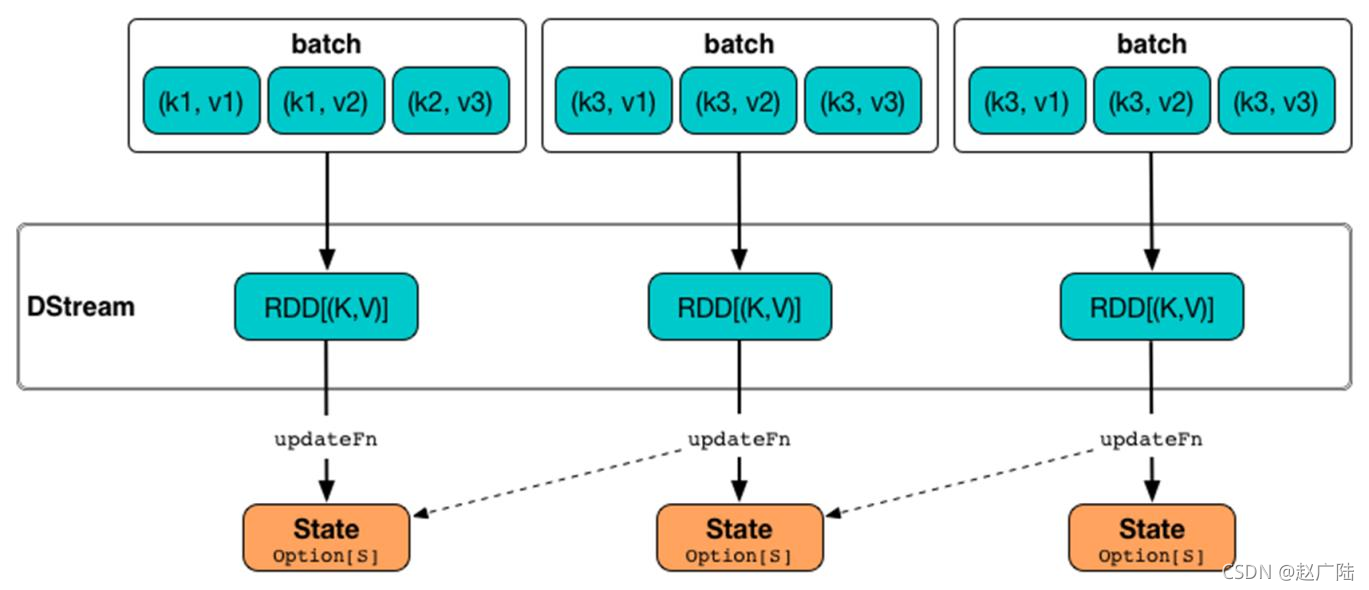
文档: http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#updatestatebykey-operation
针对搜索词词频统计WordCount,状态更新逻辑示意图如下: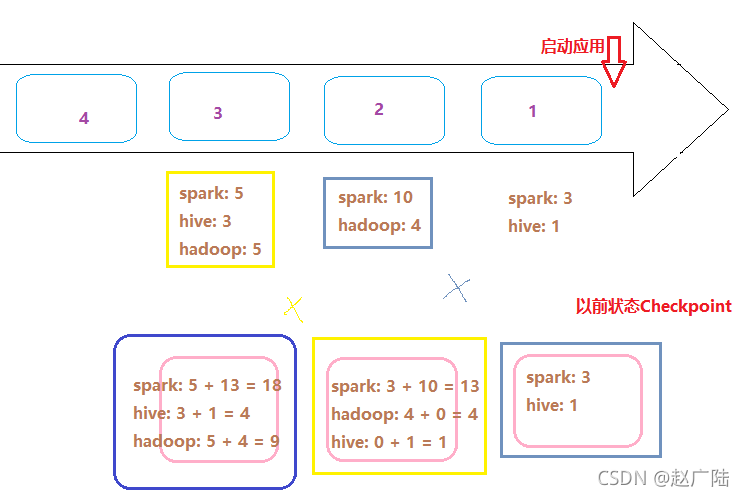
以前的状态数据,保存到Checkpoint检查点目录中,所以在代码中需要设置Checkpoint检查点目录:
完整演示代码如下:
package cn.oldlut.spark.app.state
import cn.oldlut.spark.app.StreamingContextUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
/\*\*
\* 实时消费Kafka Topic数据,累加统计各个搜索词的搜索次数,实现百度搜索风云榜
\*/
object StreamingUpdateState {
def main(args: Array[String]): Unit = {
// 1. 获取StreamingContext实例对象
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 5)
// TODO: 设置检查点目录
ssc.checkpoint(s"datas/streaming/state-${System.nanoTime()}")
// 2. 从Kafka消费数据,使用Kafka New Consumer API
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils
.consumerKafka(ssc, "search-log-topic")
// 3. 对每批次的数据进行搜索词次数统计
val reduceDStream: DStream[(String, Int)] = kafkaDStream.transform { rdd =>
val reduceRDD = rdd
// 过滤不合格的数据
.filter { record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map { record =>
val keyword: String = record.value().trim.split(",").last
keyword -> 1
}
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item) // TODO: 先聚合,再更新,优化
reduceRDD // 返回
}
/\*
def updateStateByKey[S: ClassTag](
// 状态更新函数
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)]
第一个参数:Seq[V]
表示的是相同Key的所有Value值
第二个参数:Option[S]
表示的是Key的以前状态,可能有值Some,可能没值None,使用Option封装
S泛型,具体类型有业务具体,此处是词频:Int类型
\*/
val stateDStream: DStream[(String, Int)] = reduceDStream.updateStateByKey(
(values: Seq[Int], state: Option[Int]) => {
// a. 获取以前状态信息
val previousState = state.getOrElse(0)
// b. 获取当前批次中Key对应状态
val currentState = values.sum
// c. 合并状态
val latestState = previousState + currentState
// d. 返回最新状态
Some(latestState)
}
)
// 5. 将结果数据输出 -> 将每批次的数据处理以后输出
stateDStream.print()
// 6.启动流式应用,一直运行,直到程序手动关闭或异常终止
ssc.start()
ssc.awaitTermination()
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
运行应用程序,通过WEB UI界面可以发现,将以前状态保存到Checkpoint检查点目录中,更新时在读取。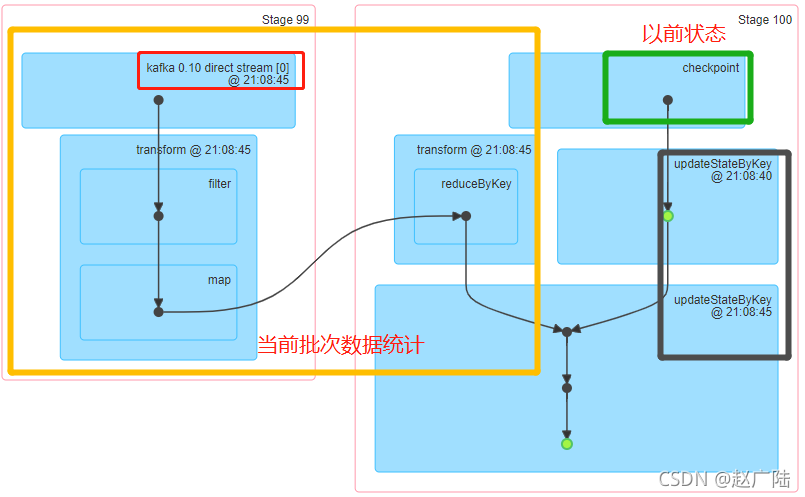
此外,updateStateByKey函数有很多重载方法,依据不同业务需求选择合适的方式使用。
4.2 mapWithState 函数
Spark 1.6提供新的状态更新函数【mapWithState】,mapWithState函数也会统计全局的key的状态,但是如果没有数据输入,便不会返回之前的key的状态,只是关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。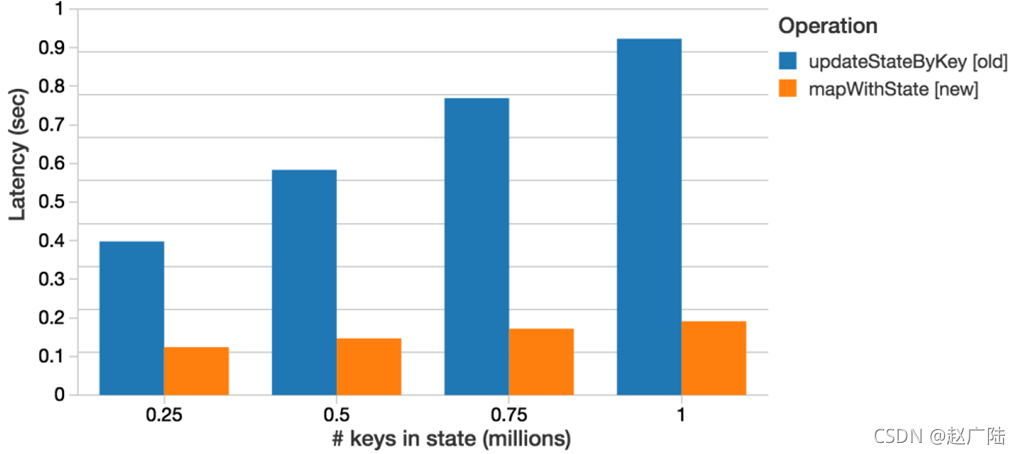
这样的话,即使数据量很大,checkpoint也不会像updateStateByKey那样,占用太多的存储,效率比较高;
需要构建StateSpec对象,对状态State进行封装,可以进行相关操作,类的声明定义如下:
状态函数【mapWithState】参数相关说明:
完整演示代码如下:
package cn.oldlut.spark.app.state
import cn.oldlut.spark.app.StreamingContextUtils
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{State, StateSpec, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
/\*\*
\* 实时消费Kafka Topic数据,累加统计各个搜索词的搜索次数,实现百度搜索风云榜
\*/
object StreamingMapWithState {
def main(args: Array[String]): Unit = {
// 1. 获取StreamingContext实例对象
val ssc: StreamingContext = StreamingContextUtils.getStreamingContext(this.getClass, 5)
// TODO: 设置检查点目录
ssc.checkpoint(s"datas/streaming/state-${System.nanoTime()}")
// 2. 从Kafka消费数据,使用Kafka New Consumer API
val kafkaDStream: DStream[ConsumerRecord[String, String]] = StreamingContextUtils
.consumerKafka(ssc, "search-log-topic")
// 3. 对每批次的数据进行搜索词进行次数统计
val reduceDStream: DStream[(String, Int)] = kafkaDStream.transform { rdd =>
val reduceRDD: RDD[(String, Int)] = rdd
// 过滤不合格的数据
.filter { record =>
val message: String = record.value()
null != message && message.trim.split(",").length == 4
}
// 提取搜索词,转换数据为二元组,表示每个搜索词出现一次
.map { record =>
val keyword: String = record.value().trim.split(",").last
keyword -> 1
}
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item) // TODO: 先聚合,再更新,优化
// 返回
reduceRDD
}
// TODO: 4、实时累加统计搜索词搜索次数,使用mapWithState函数
/\*


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
tem) // TODO: 先聚合,再更新,优化
// 返回
reduceRDD
}
// TODO: 4、实时累加统计搜索词搜索次数,使用mapWithState函数
/\*
[外链图片转存中...(img-YsAfYuVS-1715819468848)]
[外链图片转存中...(img-csyapzee-1715819468849)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









