







组件版本信息如下:
| 组件 | 版本 |
|---|---|
| Cloudera Manager | 6.3.1 |
| Flume | 1.9.0+cdh6.3.2 |
| Hadoop | 3.0.0+cdh6.3.2 |
| HBase | 2.1.0+cdh6.3.2 |
| Hive | 2.1.1+cdh6.3.2 |
| Hue | 4.2.0+cdh6.3.2 |
| Impala | 3.2.0+cdh6.3.2 |
| Kafka | 2.2.1+cdh6.3.2 |
| Solr | 7.4.0+cdh6.3.2 |
| spark | 2.4.0+cdh6.3.2 |
| Sqoop | 1.4.7+cdh6.3.2 |
| ZooKeeper | 3.4.5+cdh6.3.2 |
一:下载Flink,并制作parcel包
1.相关资源下载
1.1) flink下载地址: https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
1.2) parcel制作工具:https://github.com/pkeropen/flink-parcel.git
1.3) cm验证工具:https://github.com/cloudera/cm_ext.git
说明: 需要用到maven,unzip,确保已安装并配置mvn环境变量,需要提前下载上面的两个工具和flink.到本地,然后上传到服务器。
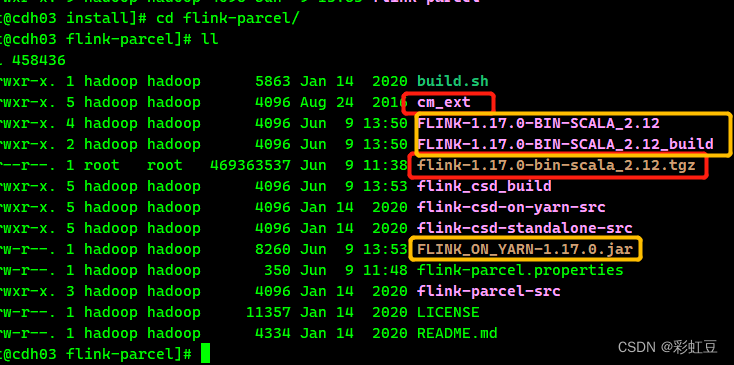
红框里面的是下载下来,重命名,解压放到 flink-parcel目录里面的。黄框里的是后面制作是生成的。下载好的包放入flink-parcel目录里面需要将名字和图片一致。
用到的命令:
mvn -version #验证本地maven安装环境变量配置是否OK.
unzip flink-parcel-master.zip # 解压包到当前目录
mv ./flink-parcel-master/* ./ flink-parcel #重命名
chmod +x ./build.sh #将build.sh 文件赋予可执行
unzip ./cm_ext-master.zip #解压包到当前目录
mv ./cm_ext-master ./cm_ext #重命名
mv ./cm_ext /opt/install/flink-parcel/ #移动到flink-parcel目录下
mv ./flink-1.17.0-bin-scala_2.12.tgz /opt/install/flink-parcel/ #移动到flink-parcel目录下
2. 修改配置
修改flink-parcel.properties为以下内容:
#FLINK 下载地址 此地址写上只是为了脚本取值时有值可取,是否正确无所谓,因为目录里面已经包含了下载好的包,会用下载好的包。此行注释掉,后面脚本运行会报错。
FLINK_URL=https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz#flink版本号
FLINK_VERSION=1.17.0
#扩展版本号
EXTENS_VERSION=BIN-SCALA_2.12
#操作系统版本,以centos为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=5.2
CDH_MAX_FULL=6.3.3
#CDH大版本
CDH_MIN=5
CDH_MAX=6
准备工作一:
执行脚本时会有一个报错,已查阅
/opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh: line 17: rotateLogFilesWithPrefix: command not found
此脚本里面缺少俩个方法,添加上。
参考:flink/config.sh at release-1.11.6 · apache/flink · GitHub
Auxilliary functions for log file rotation
rotateLogFilesWithPrefix() {
dir=$1
prefix=
2
w
h
i
l
e
r
e
a
d
−
r
l
o
g
;
d
o
r
o
t
a
t
e
L
o
g
F
i
l
e
"
2 while read -r log ; do rotateLogFile "
2whileread−rlog;dorotateLogFile"log"
find distinct set of log file names, ignoring the rotation number (trailing dot and digit)
done < <(find "
d
i
r
"
!
−
t
y
p
e
d
−
p
a
t
h
"
dir" ! -type d -path "
dir"!−typed−path"{prefix}" | sed s/.[0-9][0-9]$// | sort | uniq)
}
rotateLogFile() {
log=
1
;
n
u
m
=
1; num=
1;num=MAX_LOG_FILE_NUMBER
if [ -f “
l
o
g
"
−
a
"
log" -a "
log"−a"num” -gt 0 ]; then
while [ $num -gt 1 ]; do
prev=expr $num - 1
[ -f “
l
o
g
.
log.
log.prev” ] && mv “
l
o
g
.
log.
log.prev” “
l
o
g
.
log.
log.num”
num=
p
r
e
v
d
o
n
e
m
v
"
prev done mv "
prevdonemv"log" “
l
o
g
.
log.
log.num”;
fi
}
将上述俩个方法加到/opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh 脚本里面,加到readMasters() 这个方法上面。其实加到哪个方法前应该都可以,看上面官方,这俩个方法是在这个方法上面,所以不乱自操作。加入后,俩个方法和上面官方可以对比下代码,看是否有偏差。
准备工作二:
在安装flink的机器上环境变量加上 vim /etc/profile
export HADOOP_CLASSPATH=hadoop classpath
source /etc/profile #使生效
echo ${HADOOP_CLASSPATH} #验证
3. 开始build
cd /opt/install/flink-parcel
./build.sh parcel
#maven会下载很多依赖,打包完成后会在当前目录生成FLINK-1.17.0-BIN-SCALA_2.11_build文件
里面就包含了三个文件:
FLINK-1.17.0-BIN-SCALA_2.12-el7.parcel
FLINK-1.17.0-BIN-SCALA_2.12-el7.parcel.sha
manifest.json
构建flink-yarn csd包
./build.sh csd_on_yarn
执行完回生成FLINK_ON_YARN-1.17.0.jar文件
好了,制作完成了,下面就是加入到CDH里面。(我是在cdh03上做的,但是/opt/cloudera/parcel-repo 这个目录只在cdh01上有,scp拷贝到01上的)
(1)将FLINK-1.17.0-BIN-SCALA_2.11_build里的文件放到/opt/cloudera/parcel-repo,并修改所属用户和组
(2)将FLINK_ON_YARN-1.17.0.jar 放到 /opt/cloudera/csd/,并修改所属用户和组
cd /opt/cloudera/parcel-repo
mv manifest.json manifest.json.bak #先将已有的备份
cp /opt/install/flink-parcel/FLINK-1.17.0-BIN-SCALA_2.12_build/* ./
chown cloudera-scm. ./*
cp /opt/install/flink-parcel/FLINK_ON_YARN-1.17.0.jar /opt/cloudera/csd/
cd /opt/cloudera/csd/
chown cloudera-scm. FLINK_ON_YARN-1.17.0.jar
二:开始在CDH页面分发激活
点击Parcel,然后右上角点击 检查新Parcel.
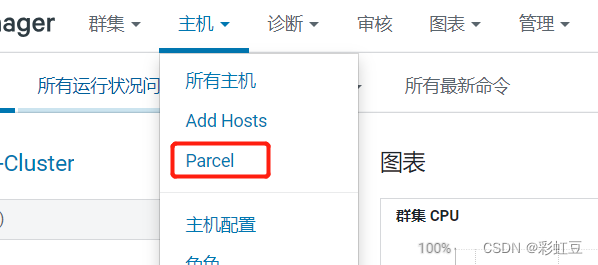

按照提示,会进行分配,然后点击激活就可以

三:CDH添加Flink-yarn 服务
主页点击添加服务。如果这时候点击过去没有看到 flink-yarn 的服务,需要将CDH重启,此时我的就是没有,先是在CDH的主节点重启 systemctl stop cloudera-scm-server。发现停不掉。就直接整个大重启了,因为是新搭建好的,还没有放入数据和任务。所以就直接全部重启了。先在CDH页面上停掉了Cloudera Management Service 服务,然后又把集群所有的服务都停掉了,然后每台机器的cloudera-scm-server、cloudera-scm-agent也都停掉了,重启按照反的顺序重启。然后就可以看到有flink-yarn服务了。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

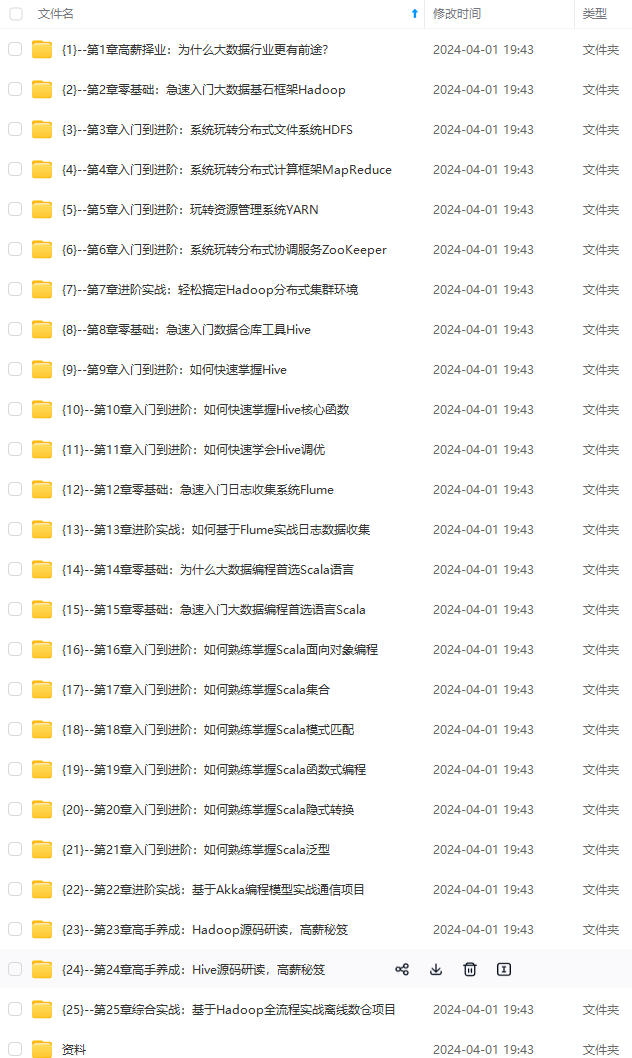
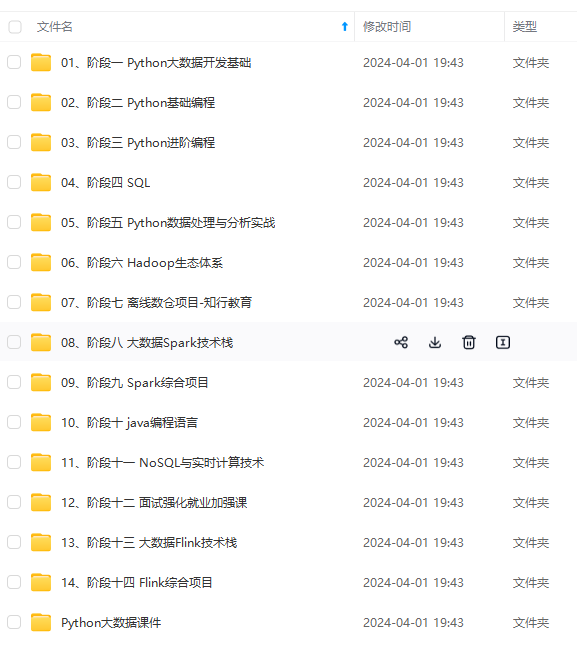
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

rwM-1712513411290)]
[外链图片转存中…(img-Ign7ubmO-1712513411290)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-Aypxrm7o-1712513411291)]














 4779
4779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









