







✨前言
2022年全国大学生数学建模比赛已经落下帷幕,每一位坚持到比赛结束的数模人都值得我们去敬佩!
数学建模专栏:数学建模从0到1
👉🏻历史回顾👈🏻
| 数学建模入门篇 | 零基础如何入门数学建模?_小羊不会飞的博客 |
| 长三角实战篇 | 长三角数学建模------赛后总结_小羊不会飞的博客 |
| 数学建模(一):插值 | 数学建模(一):插值_小羊不会飞的博客-CSDN博客 |
| 数学建模(二):优化 | 数学建模(二):优化_小羊不会飞的博客-CSDN博客 |
| 数学建模(三):预测 | 数学建模(三):预测_小羊不会飞的博客-CSDN博客 |
| 数学建模(四):分类 | 数学建模(四):分类_小羊不会飞的博客-CSDN博客 |
| … | 后续内容,尽情期待专栏更新! |
🔍1、竞赛章程
📑1.1承诺书

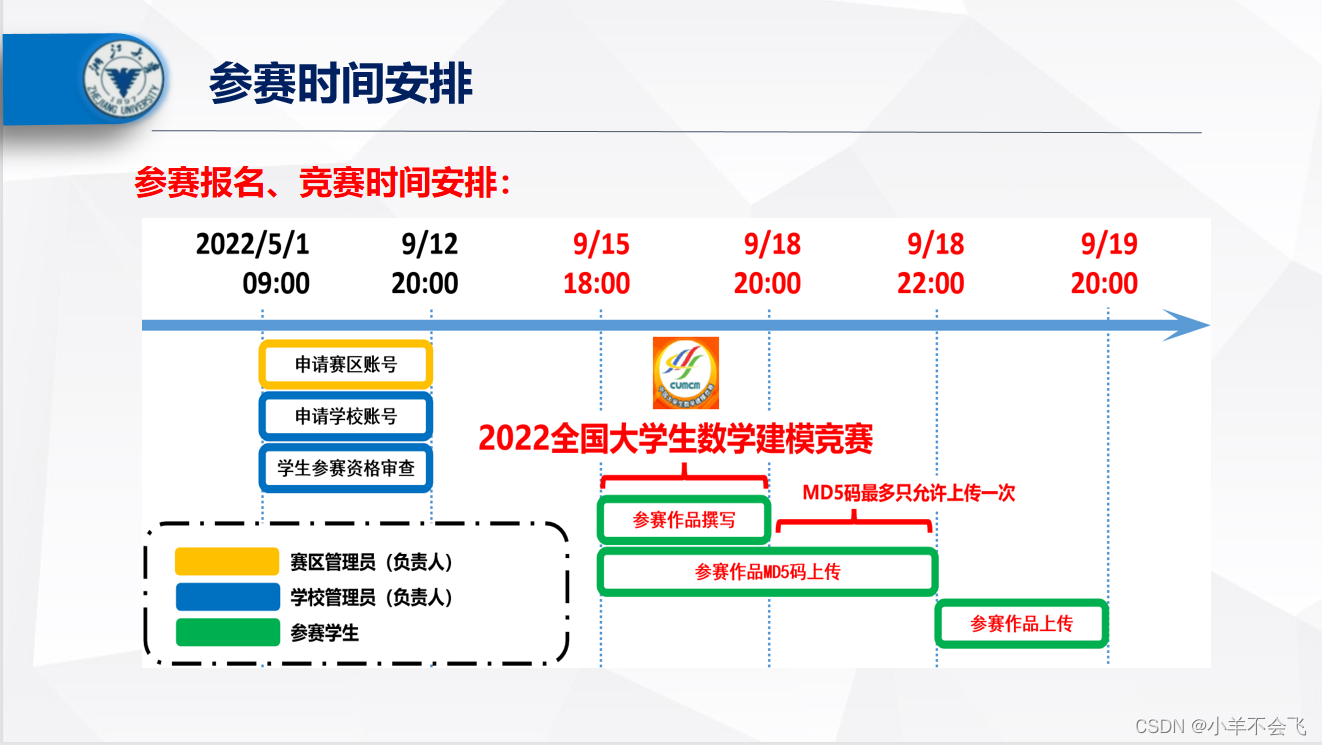
📑1.2时间安排
📖2、竞赛选题
2.1题目发放
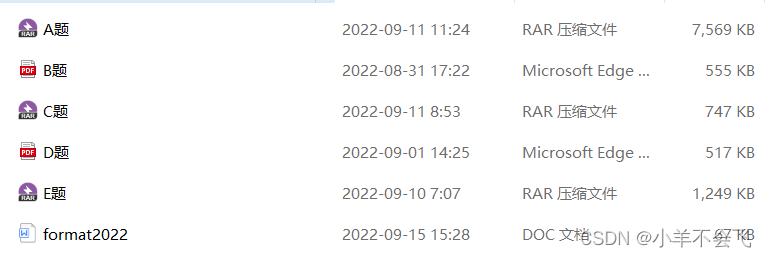
本科组:
- A题
- B题
- C题
专科组:
- D题
- E题
题目可在官网下载:
全国大学生数学建模竞赛
http://www.mcm.edu.cn/html_cn/block/8579f5fce999cdc896f78bca5d4f8237.html
2.2关于选题
A题
- A题不出所料是一道物理题,大致浏览了一下题目,直接pass,对非物理or数学专业的选手不太友好
B题
- B题是一道规划大题,队友小鱼表示有思路,但是最后我们一起探讨了一下还是决定选C题
C题
- C题是一道统计回归+分类聚类的问题,题目难度不大,但想要出彩很难,不过这次博主的运气比较好,暑假集训的时候有对分类和聚类模型进行学习总结,并以博客的形式输出,所以最后综合考虑还是选择了C题。
- 随机森林和SVM分类算法



 https://blog.csdn.net/m0_55858611/article/details/126455731
https://blog.csdn.net/m0_55858611/article/details/1264557312.3比赛声明
在关于选题中博主有提到自己写过一篇分类的文章,刚好这次C题的第三问就是分类问题,于是在国赛开始的半小时后,这篇文章的浏览量突然蹭蹭上升,粉丝数半小时内增加99+,也有后台粉丝私信和加我vx,备注都是**“交流数模”,不过最后我都没有回复,咱先说一声抱歉,这里也做一个小小的声明:**
- 1、博主也正在参赛,比赛时间非常紧迫,几乎没有空闲的时间与其他人进行交流
- 2、对于竞赛,遵守比赛规则是我们每个参赛选手的底线,我如果给粉丝提供代码or思路都属于违规行为
🗝️3、 问题解决
- C题的题目是《古代玻璃制品的成分分析与鉴别》,excel中给的是不同类型的出土文物中各元素含量百分比的数据,以及文物的一些类型信息。
- 相比去年C的题目,今年的excel数据量小了很多。
- 这次C题主要还是分为四个小问,1,4问主要是分析数据之间的统计学规律和描述性统计,2,3问主要是聚类、分类问题以及结果的敏感性和合理性分析问题。
🎈第一问
1.1对玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行分析
- 对表面风化、玻璃类型、纹饰、颜色四个分类变量进行卡方检验,计算其相关系数
1.2分析文物样品表面有无风化化学成分含量的统计规律
- 描述性统计分析,对数据进行相关性和差异性分析,对属于正态分布的数据计算其pearson相关系数,对于偏态数据计算其spearman相关系数
1.3预测风化前文物化学成分
- 建立最小二乘回归模型,分析各化学成分分别与表面风化、玻璃类型、纹饰、颜色之间的关系,得到回归方程,将风化类型的文物按颜色、类型、纹饰一共分为七类,将这七类数据带入回归方程得到文物未风化前的化学成分含量
🎈第二问
2.1分析不同分类数据之间的分类规律
- 建立决策树模型找到区分高钾玻璃和铅钡玻璃的化学成分为PbO,通过逐步回归分析得到具有代表性的四个化学成分作为进一步亚分类的指标
2.2对每个类别进行亚分类
- 通过K-means算法利用这四个指标分别对高钾玻璃和铅钡玻璃进行下一步的亚分类
2.3分析结果的合理性和敏感性
- 利用平均轮廓法求得聚类中K的值,通过“肘部法则”去检验其结果的合理性,对数据增加扰动项分析其结果的敏感性

🎈第三问

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
]
[外链图片转存中…(img-LIpnnzBl-1714394626252)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









