







2.2 API扩展插件
- API扩展插件通过添加新的、与搜索有关的 API 或功能,实现对es新功能的添加。
- es社区人员陆陆续续贡献了不少API扩展插件编辑器,汇总如下:
| 插件名称 | 作用 |
|---|---|
| Carrot2 Plugin | 用于结果聚类。可访问 GitHub 官网搜索 elasticsearch-carrot2,查看配套代码。 |
| Elasticsearch Trigram Accelerated Regular Expression Filter | 该插件包括查询、过滤器、原生脚本、评分函数,以及用户最终创建的任意其他内容,通过该插件可以让搜索变得更好。可访问 GitHub 官网搜索 search-extra 获取插件。 |
| Elasticsearch Experimental Highlighter | Java 编写,用于文本高亮显示。可访问 GitHub 官网,搜索 search-highlighter 获取插件。 |
| Entity Resolution Plugin | 该插件使用 Duke (Duke 是一个用 Java 编写的、快速灵活的、删除重复数据的引擎)进行重复检测。读者可访问 GitHub 官网,搜索 elasticsearch-entity-resolution 获取插件 |
| Entity Resolution Plugin(zentity) | 用于实时解析es中存储的实体信息。可访问 GitHub 官网,搜索zentity 获取插件。 |
| POL language Plugin | 该插件允许用户使用简单的管道查询语法对es进行查询。可访问 GitHub官网,搜索 elasticsearch-pql 获取插件。 |
| Elasticsearch Taste Plugin | 该插件基于 Mahout Taste 的协同过滤算法实现。可访问 GitHub 官网,搜索elasticsearch-taste 获取插件。 |
| WebSocket Change Feed Plugin | 该插件允许客户端创建到es节点的 WebSocket 连接,并从数据库接收更改的提要。可访问 GitHub 官网,搜索 es-change-feed-plugin 获取插件 |
三、Head 插件
- es-head插件在0.x-2.x版本时,是集成在elasticsearch内的。由elasticsearch的bin/elasticsearch-plugin来管理插件,从2.x版本跳到了5.x版本后,head就作用了一个独立的服务来运行了。
- Elasticsearch 5之后则需要将elasticsearch-head服务单独运行,并且支持Chrome的插件方式或者Docker容器运行方式。
- 这个插件我们前面已经安装过,这里就介绍下具体怎么玩它。
插件简介:
- Head 插件,全称为 elasticsearch-head,是一个界面化的集群操作和管理工具,可以对集群进行“傻瓜式”操作。
- 既可以把 Head 插件集成到 Elasticsearch 中,也可以把 Head 插件当成-个独立服务。
主要功能:
- 显示es集群的拓扑结构,能够执行索引和节点级别的操作。
- 在搜索接口能够查询es集群中原始JSON 或表格格式的数据。
- 能够快速访问并显示es集群的状态。
3.1 安装
1.安装node.js环境,注意版本不要太高,不然会跟linux本身的依赖库包版本冲突报错。
[root@localhost bck]# tar zxf node-v16.9.0-linux-x64.tar.gz
[root@localhost bck]# mv node-v16.9.0-linux-x64 /usr/local/node
[root@localhost bck]# tail -2 /etc/profile
export node_home=/usr/local/node
export PATH=$node_home/bin:$PATH
[root@localhost bck]# source /etc/profile
[root@localhost bck]# node -v
v16.9.0
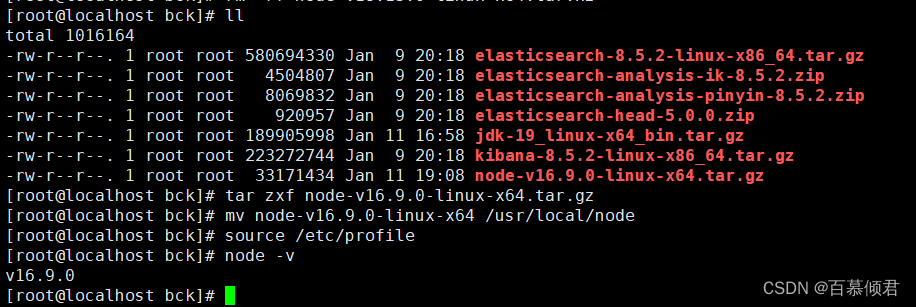
2.解压es-head安装包,安装依赖。注意这里需要进入解压出来的目录里执行命令。下载地址
#安装cnpm
[root@localhost elasticsearch-head-5.0.0]# npm install -g cnpm --registry=https://registry.npm.taobao.org
#安装依赖
[root@localhost elasticsearch-head-5.0.0]# cnpm install

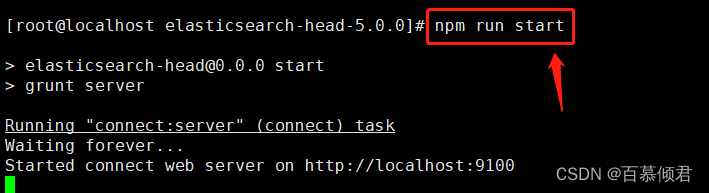
3.启动es-head
[root@localhost elasticsearch-head-5.0.0]# npm run start
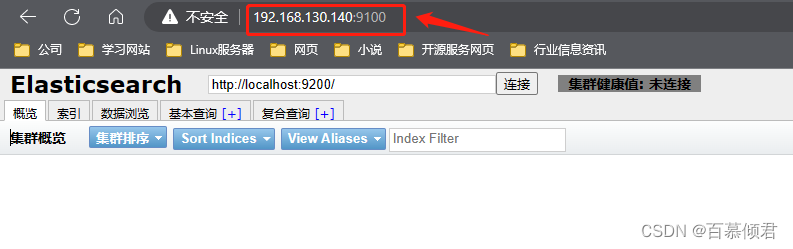
4.访问页面。
5.修改es配置文件,添加如下两行,解决跨域问题。
[root@localhost elasticsearch-8.5.2]# vi config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
6.重启es,es-head就可以连接es了。
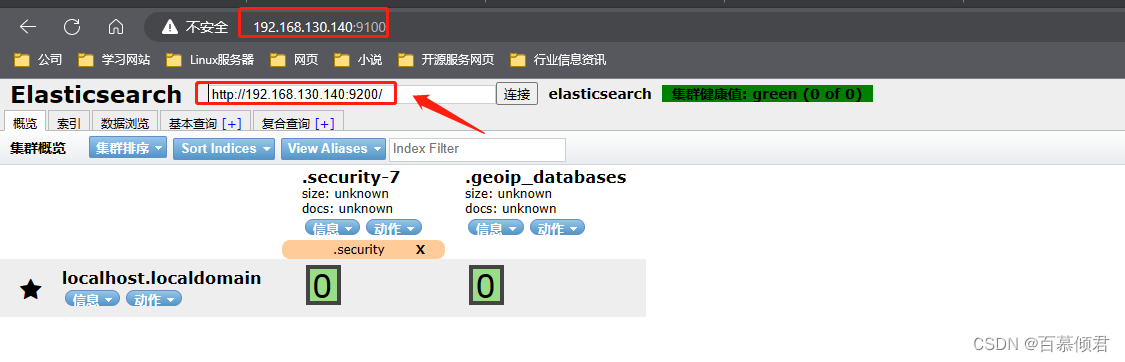
3.2 web页面使用
Head 插件首页由 4 部分组成:节点地址输入区域、信息刷新区域、导航条、概览中的集群信息汇总。
3.2.1 概览页
- 第一部分:节点地址输入区域。这里输入es集群任意一个节点IP就可以查看集群所有状态和数据。
- 第二部分:信息刷新区域。
- 刷新区域可以查看es相关的信息和刷新插件的信息。
2. 信息区域可以看到es相关的信息,包括集群节点信息、节点状态、集群状态集群信息、集群健康值等内容。单击对应的按钮,即可查看对应的信息。
- 第三部分:导航条。看到概览、索引、数据浏览、基本查询和复合查询五个 Tab 导航,默认为概览。
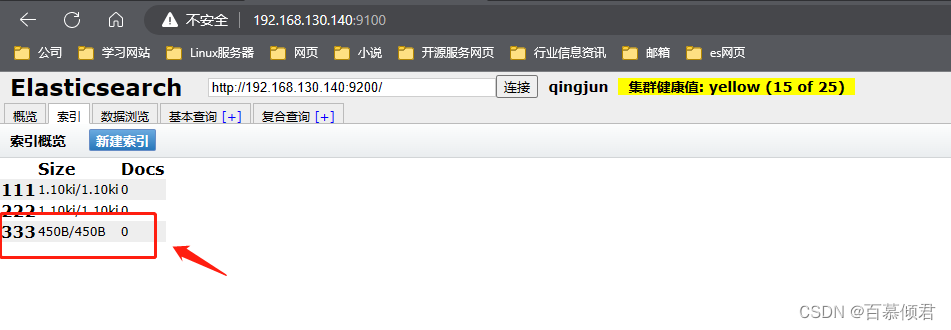
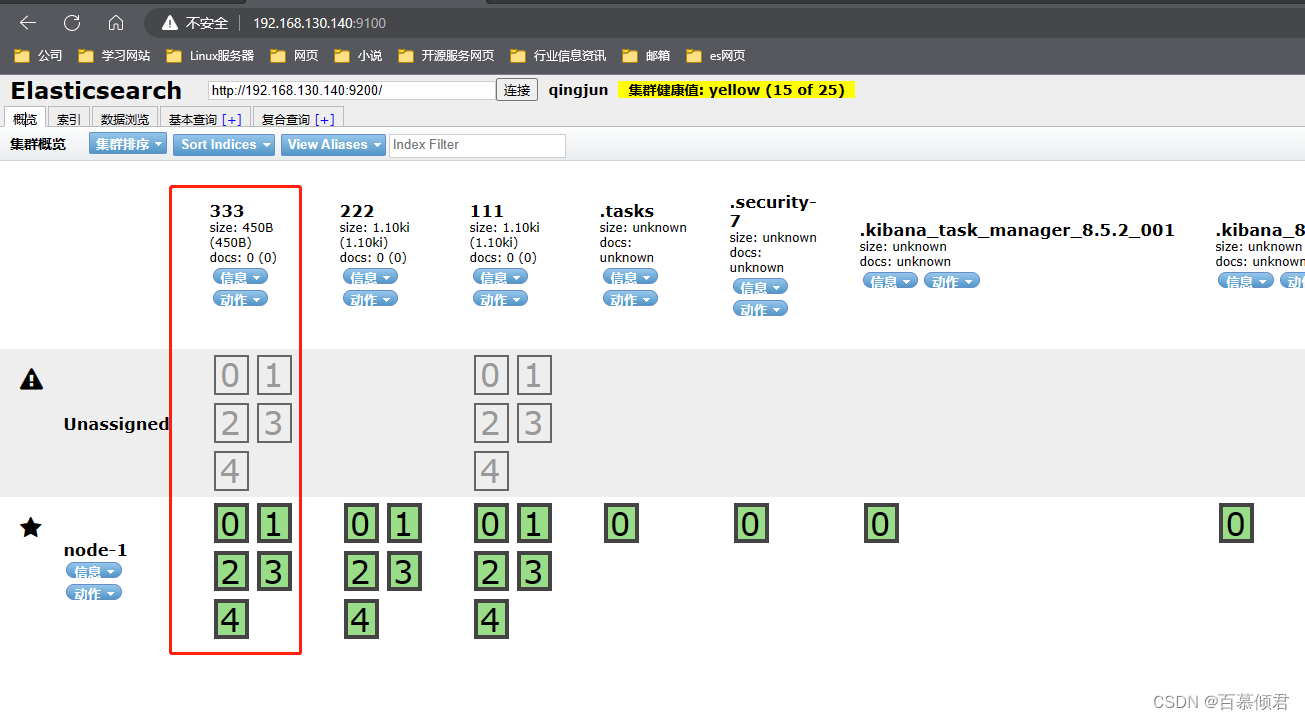
- 第四部分:概览中的集群信息汇总。可以看到es已经创建的索引,这些索引信息包含了索引的名称、索引的大小和索引的数据量,并且通过“信息”和“动作”两个按钮可以查看索引信息,或者给索引创建别名。
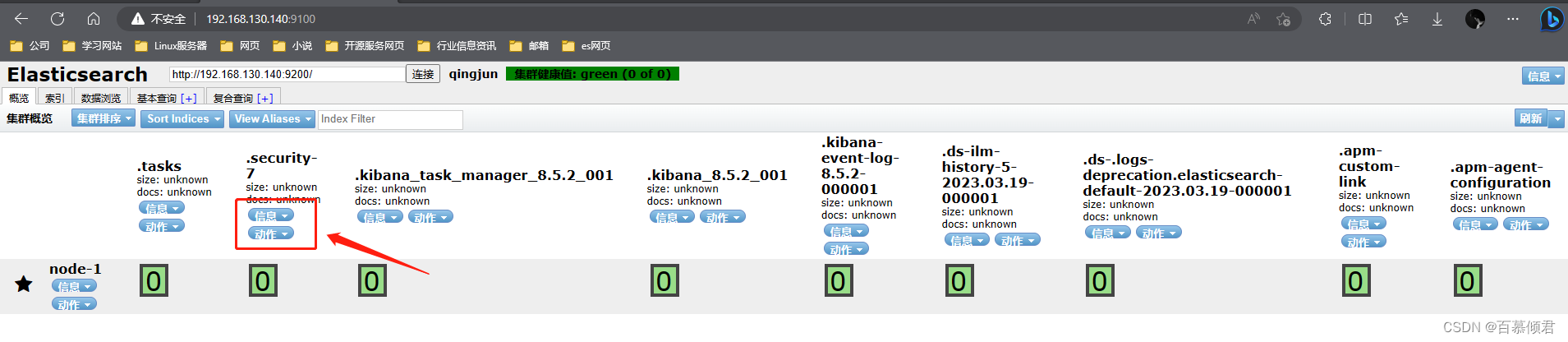
- 第五部分:集群健康值。es中有专门的衡量索引健康状况的标志,分为三个等级:
- green,绿色。代表所有的主分片和副本分片都已分配,集群是 100% 可用的。
- yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的,不会有数据丢失,所以搜索结果依然是完整的。不过高可用性在某种程度上会被弱化。如果更多的分片消失,就会丢数据了。可以把 yellow 想象成一个需要及时调查的警告。
- red,红色。至少一个主分片以及它的全部副本都在缺失中。意味缺少数据,搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
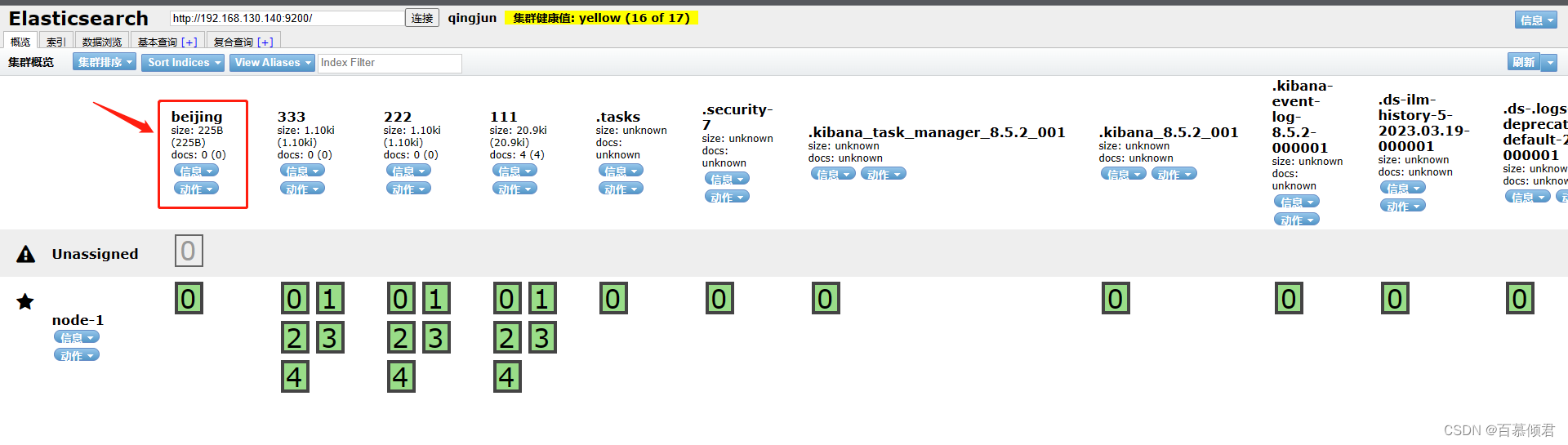
- 当只有一台主机时,索引的健康状况是 yellow。因为一台主机,集群没有其他的主机可以做副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的。
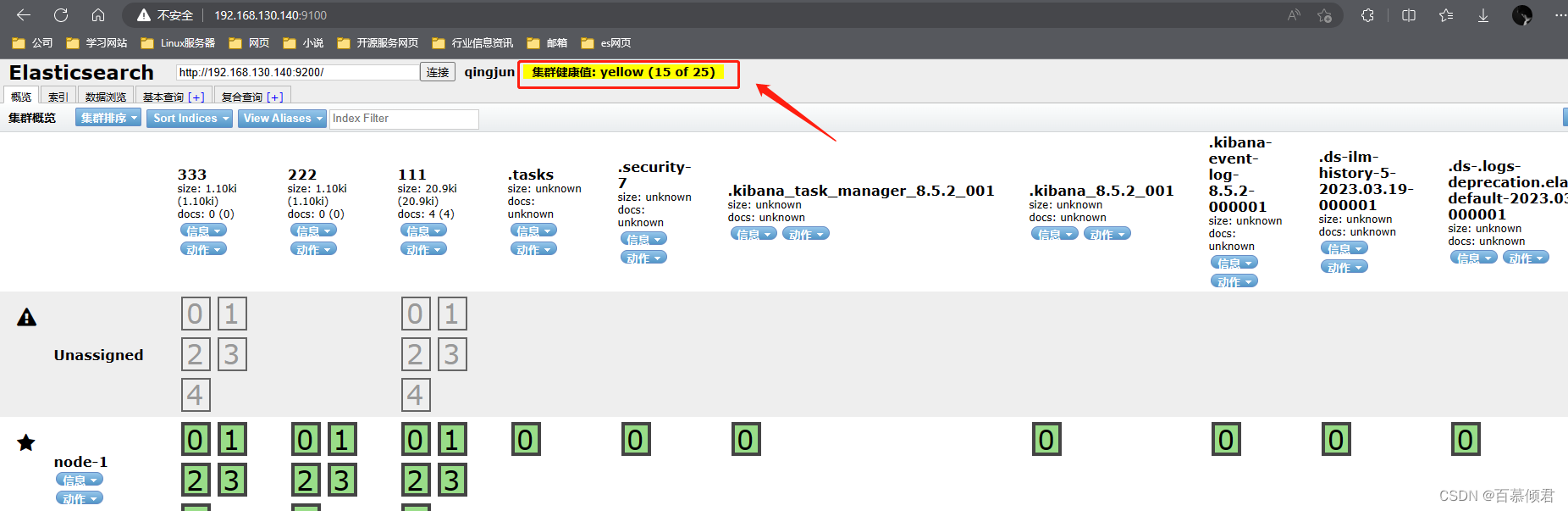
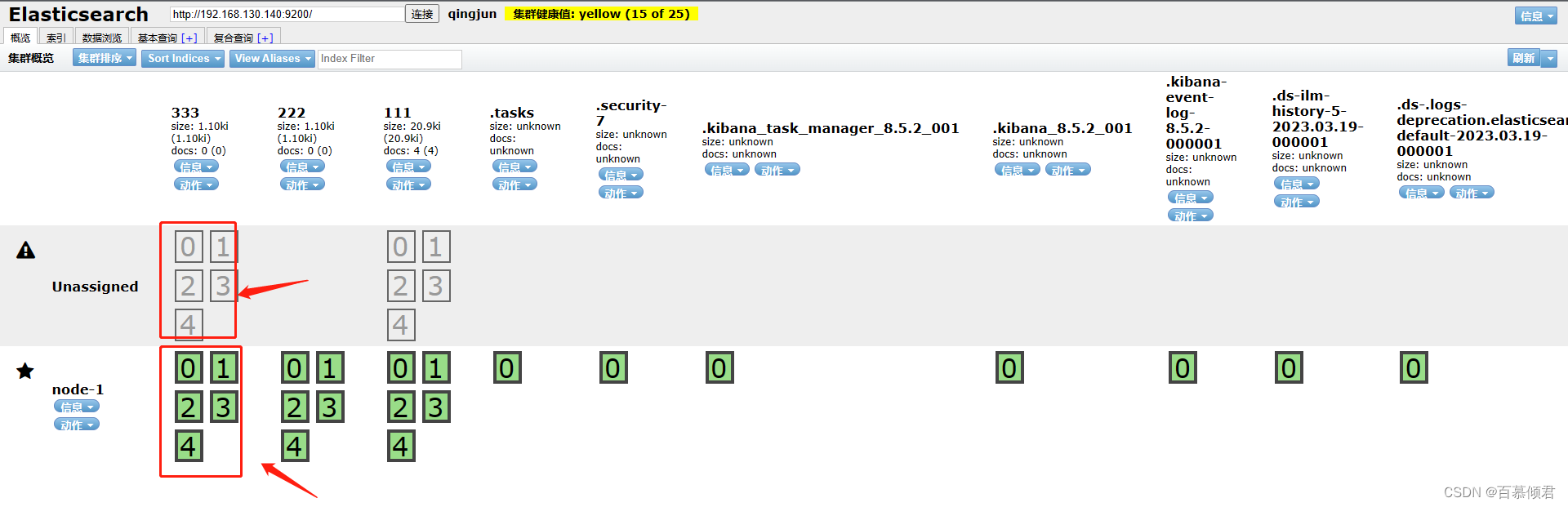
- 第六部分:索引分片。Elasticsearch数据就存储在这些分片中。每一个方框就是elasticsearch的分片,粗线方框是es的主分片,主分片旁边细线方框是es的备份分片,对应关系,粗线方框0的备份分片是细线方框0,以此类推。
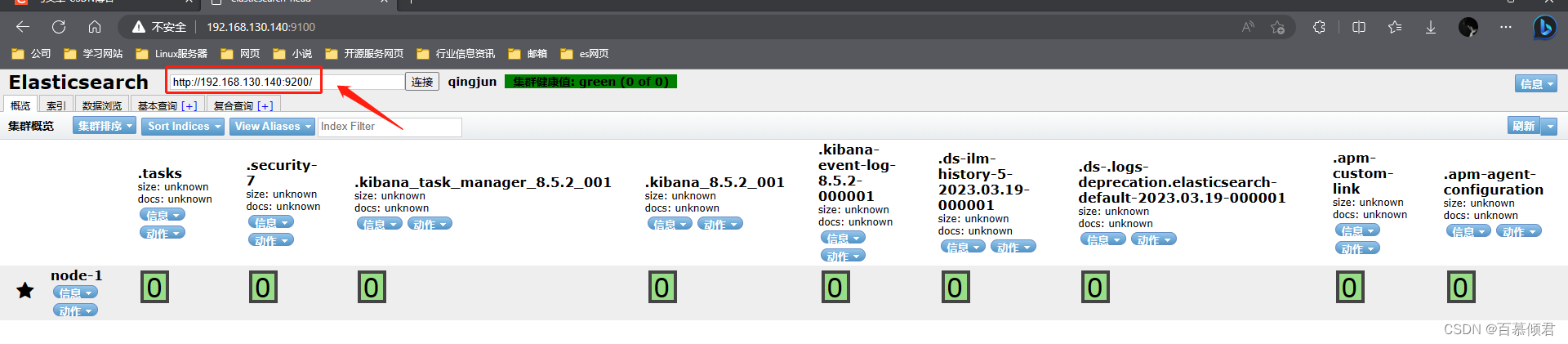
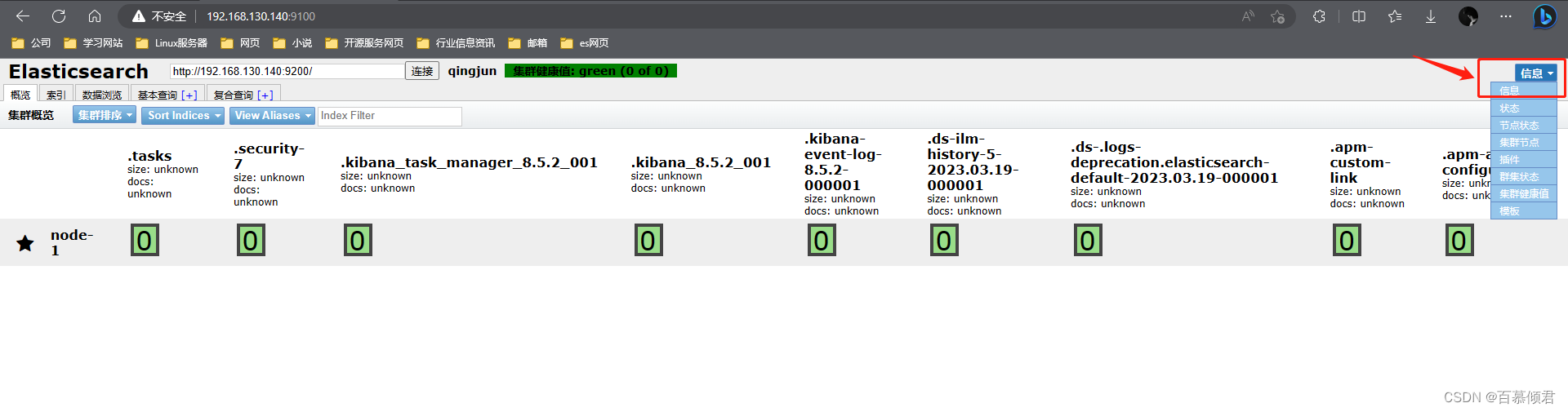
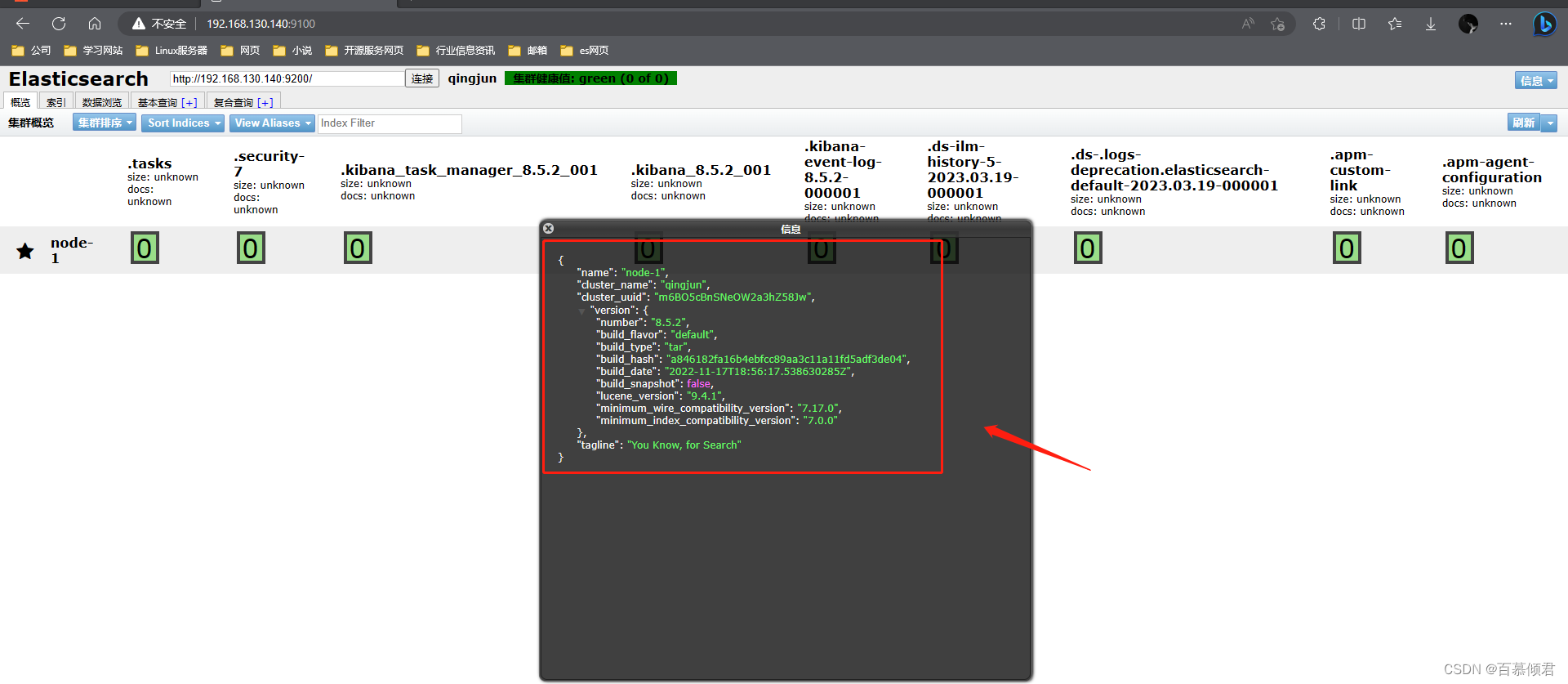

3.2.1.1 unassigned问题解决
副本分片作用:
- 主要目的是为了故障转移,为备份数据。如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色。
产生unassigned问题原因:
- 副本分片和主分片不能放在同一个节点上,在这里集群里只有一个节点,副本分片没有办法分配到其他的节点上,所以出现所有副本分片都是未分配的情况。因为只有一个节点,如果存在主分片节点挂掉了,那么整个集群理应就挂掉了,不存在副本分片升为主分片的情况。
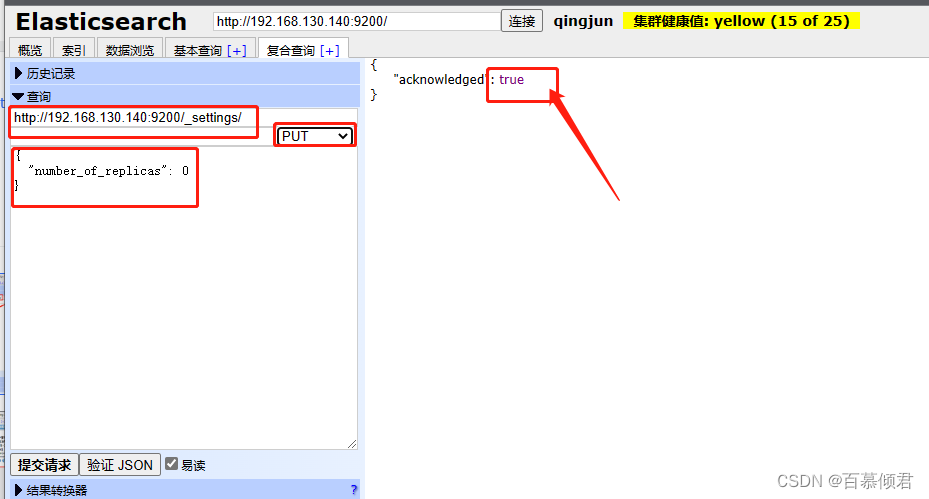
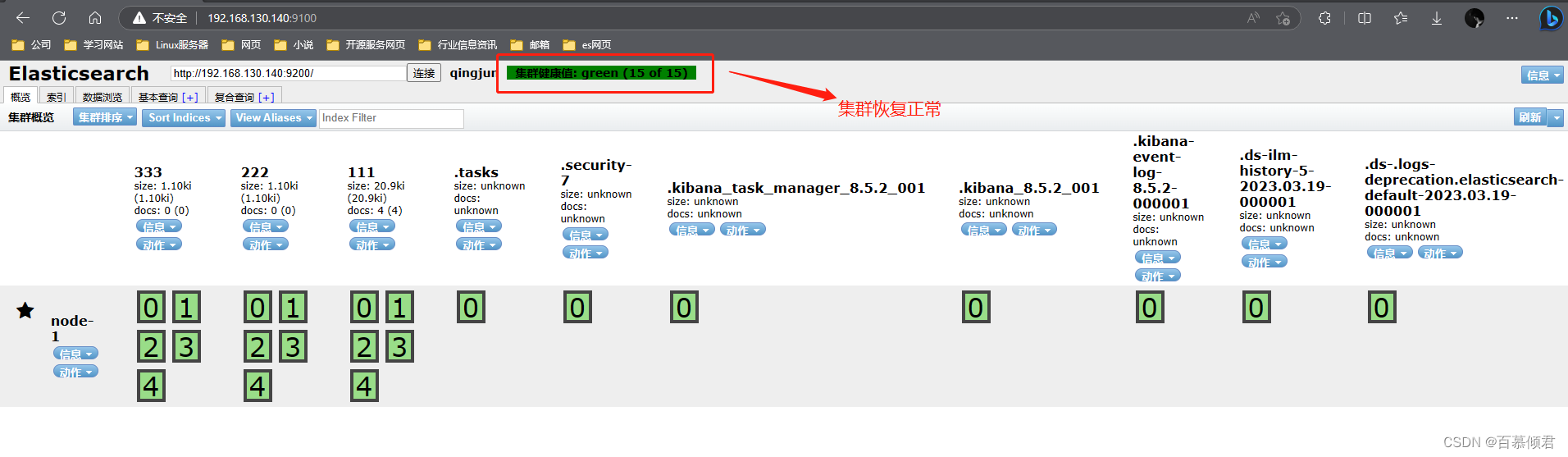
处理手段:
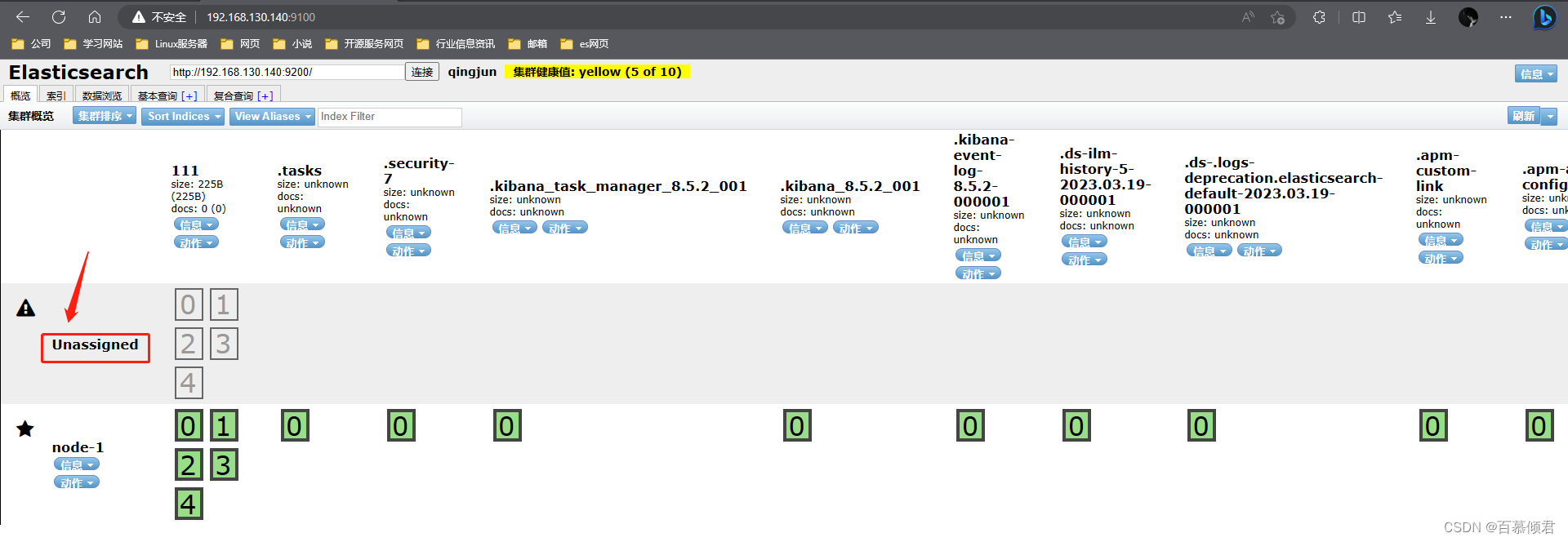
- 将每个索引的副本数重置为0即可解决这个未知节点问题。“number_of_replicas”:0
3.2.2 索引页
- 可以查看当前es集群中的索引情况。
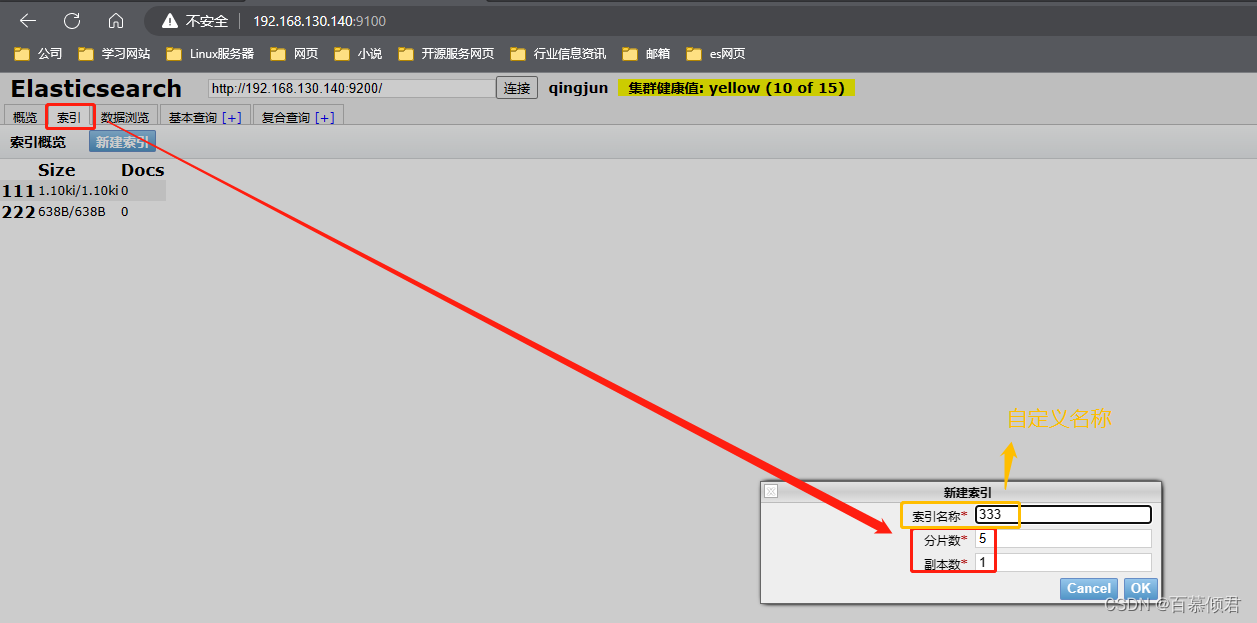
1.新建索引。
2.查看。
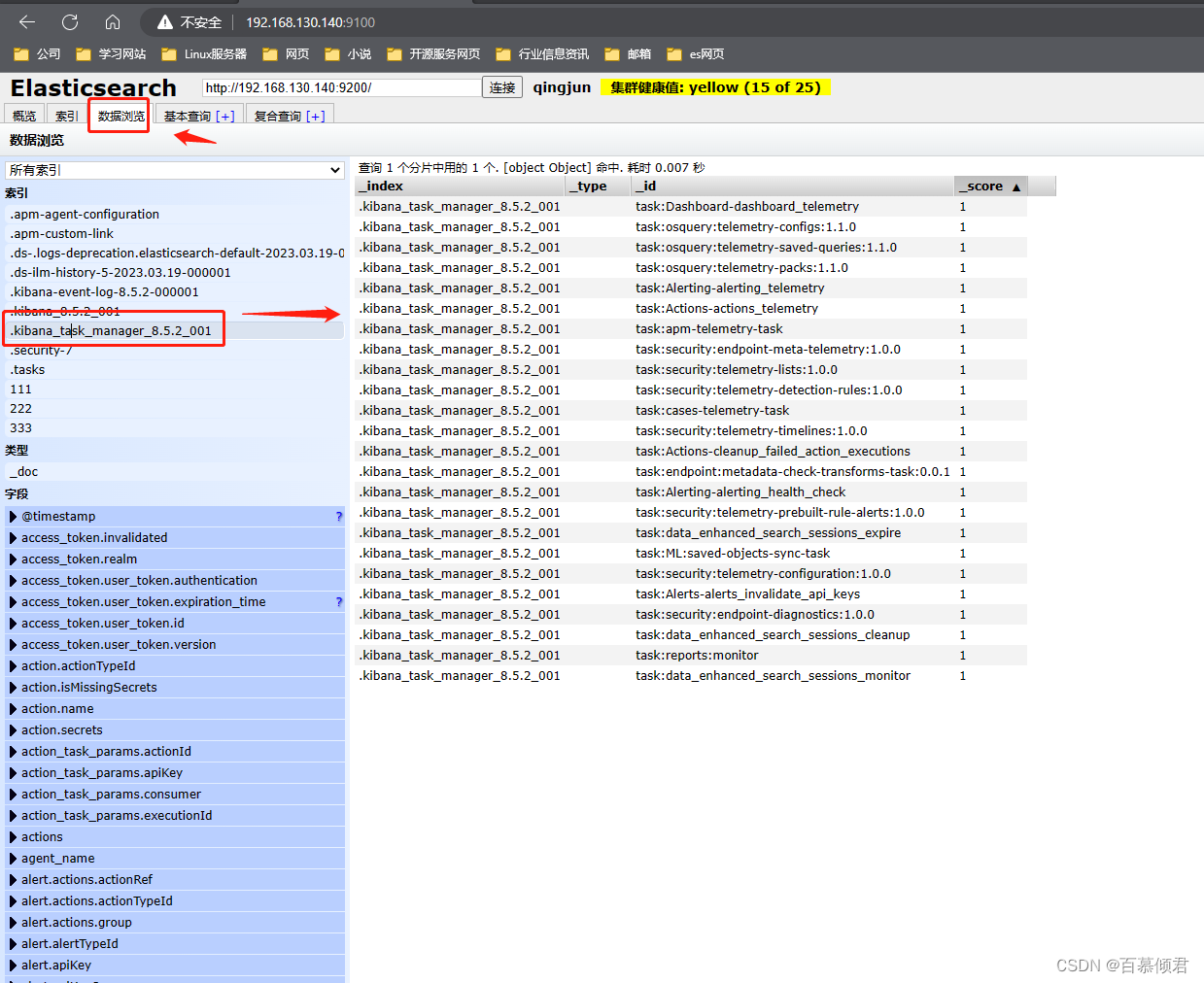
3.2.3 数据浏览页
- 可以查看特定索引下的数据。
3.2.4 基本查询页
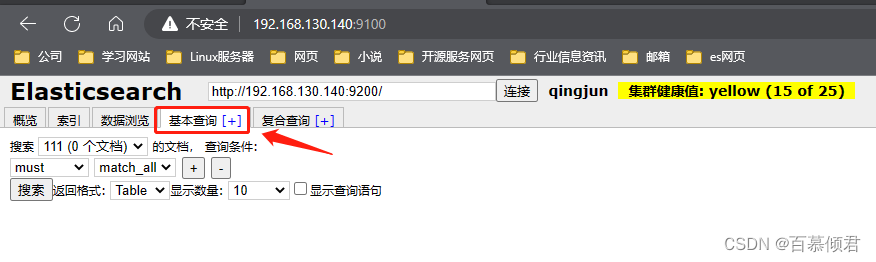
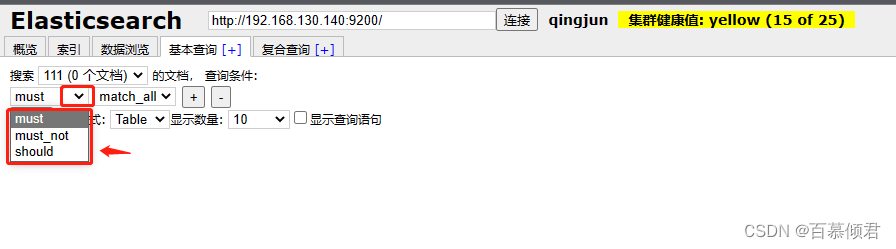
匹配方式:
- must子句:文档必须匹配 must 查询条件,相当于“=”。
- should子句:文档应该匹配 should 子查询的一个或多个条件。
- must_not子句:文档不能匹配该查询条件,相当于“!=”。
- term:表示的是精确匹配。
- wildcard:表示的是通配符匹配。
- prefix:表示的是前缀匹配。
- range:表示的是区间查询。
注意事项:
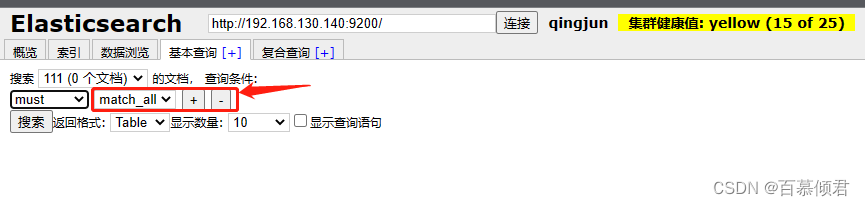
- 当用多个查询条件进行搜索或查询时,需要注意多个查询条件间的匹配方式。
- 匹配方式主要有3种,即must、should 和mus_not。
- “+”“_”按用于增加查询条件或减少查询条件。
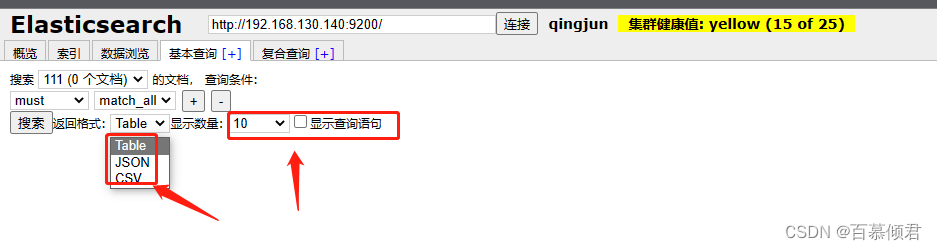
- 在查询结果展示区域中,用户可以设置数据的呈现形式,如 table、JSON、CVS 表格等还可以勾选“显示查询语句”选项,呈现通过表单内容拼接的搜索语句。
3.2.4.1 term指定查询

3.2.4.2 range范围查询

3.2.4.3 多条件查询

3.2.5 复合查询页
基本了解:
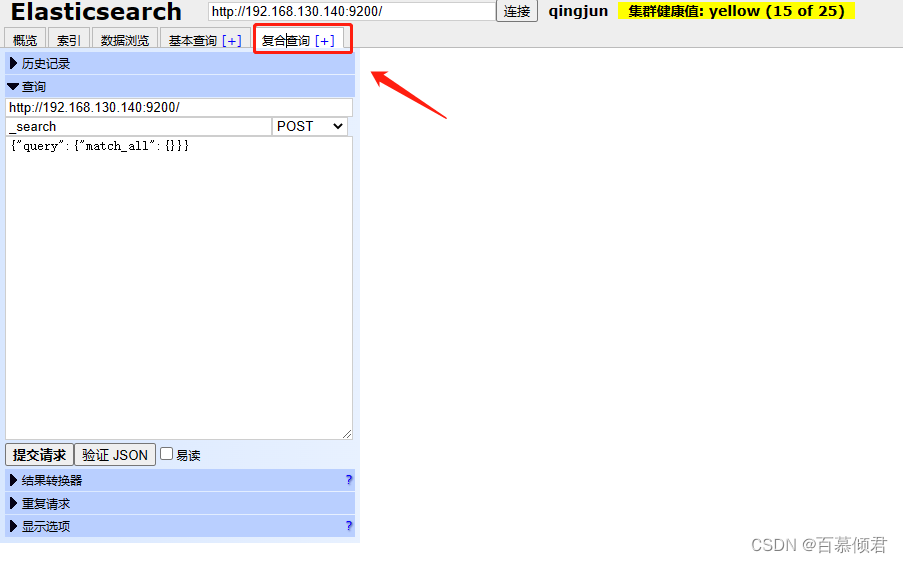
- “复合查询”标签页可以自由拼接条件,进行复杂的数据查询。
- “复合查询”标签页为用户提供了编写 RESTful接口风格的请求,用户可以使用JSON 进行复杂的查询,比如发送 PUT 请求新增及更新索引,使用 delete 请求删除索引等。
RESTful API的基本格式:
- http://ip:port/索引/类型/文档ID
配置接口的四个选项:
- 在es中,以POST 方法自动生成ID,而 PUT 方法需要指明ID。
- 请求方法与HTTP 的请求方法相同,如 GET、PUT、POST、DELETE 等。
- 还可以配置查询JSON 请求数据、请求对应的es节点和请求路径。
- 支持配置JSON验证器对用户输入的JSON 请求数据进行JSON 格式校验。
- 支持重复请求计时器配置重复请求的频率和时间。
- 在结果转换器中支持使用 JavaScript 表达式变换结果。
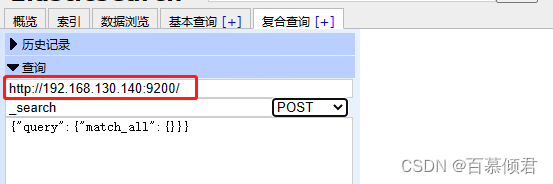
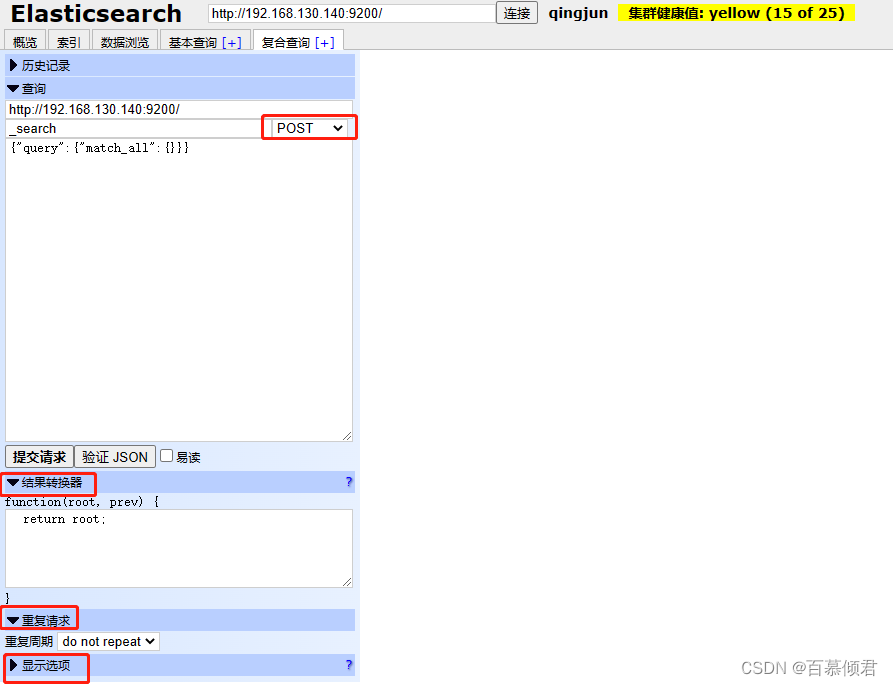
3.2.5.1 查询数据
- 查询。查询索引111中编号为1的文档。

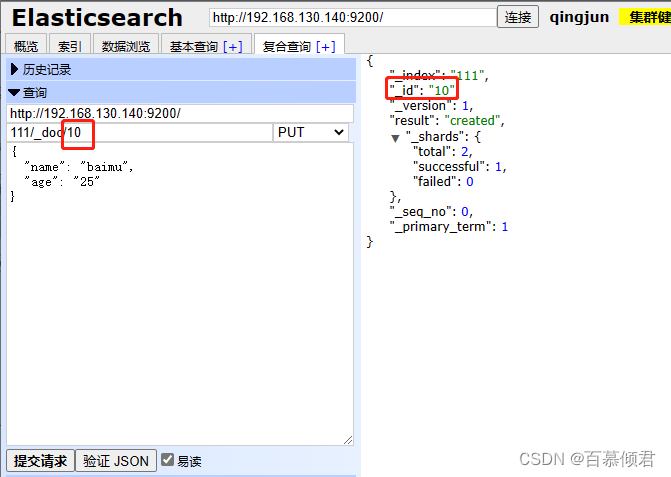
3.2.5.2 插入数据
新增数据有两种方式,POST和PUT,两者的区别就是POST自动生成文档编号,也可以指定,而PUT需要指定文档编号生成。
1.post方式指定id生成。


2.post方式不指定id生成会是随机生成一个id。

3.put方式指定id生成。
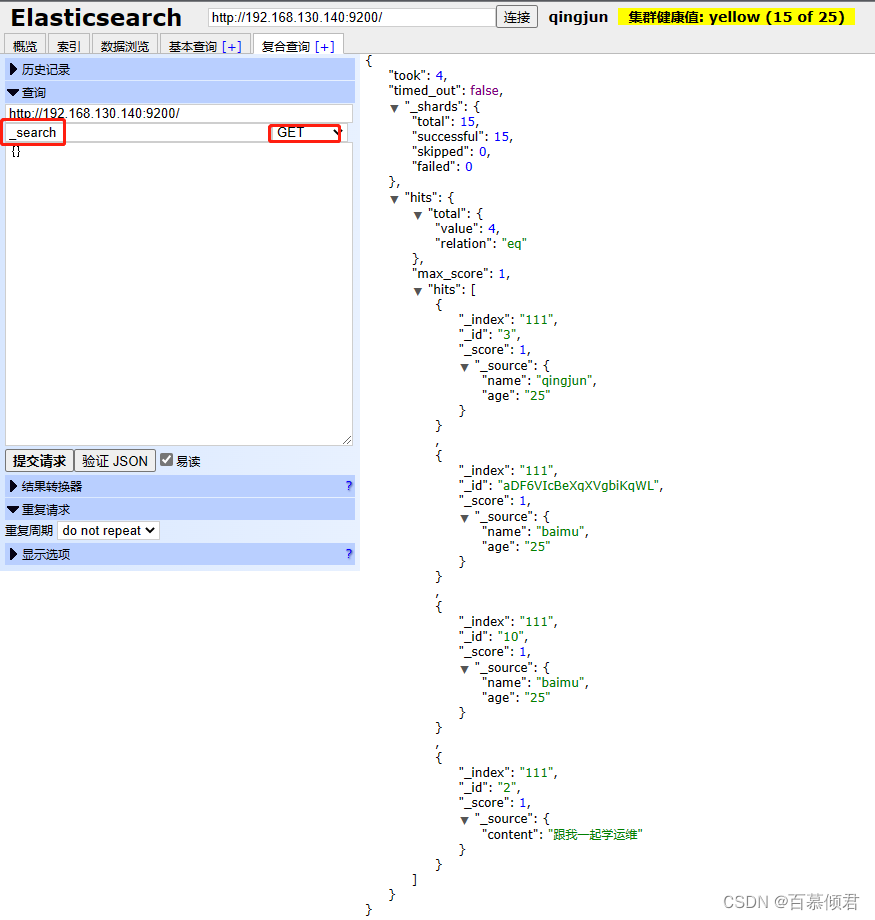
3.2.5.3 查询所有文档
3.2.5.4 布尔查询
- must:文档必须匹配这些条件才能被搜索出来。
- must_not:文档必须不匹配这些条件才能被搜索出来。
- should:如果满足这些语句中的任意语句,则将增加搜索排名结果 score; 否则,对查询结果无任何影响。其主要作用是修正每个文档的相关性得分。
- filter:表示必须匹配,但它是以不评分的过滤模式进行的。这些语句对评分没有贡献只是根据过滤标准排除或包含文档。
注意事项:
- 如果没有 must 语句,那么需要至少匹配其中的一条 should 语句。但如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。
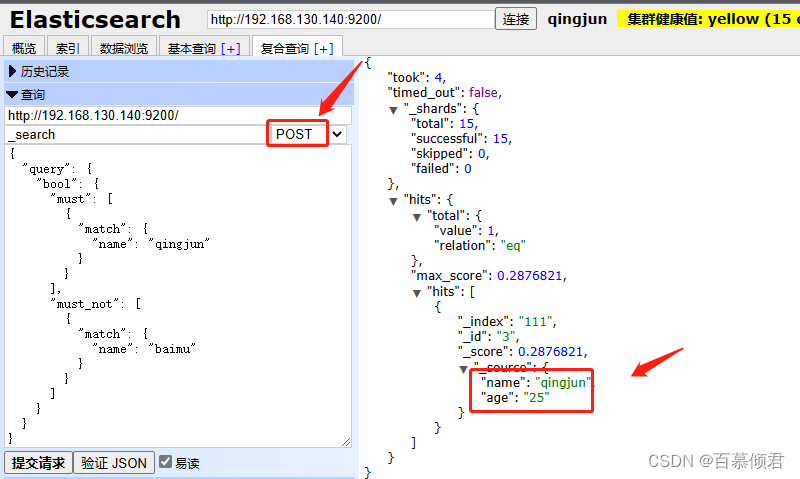
- 查看匹配”qingjun“,且不匹配”baimu“的文档。
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "qingjun"
}
}
],
"must_not": [
{
"match": {
"name": "baimu"
}
}
]
}
}
}
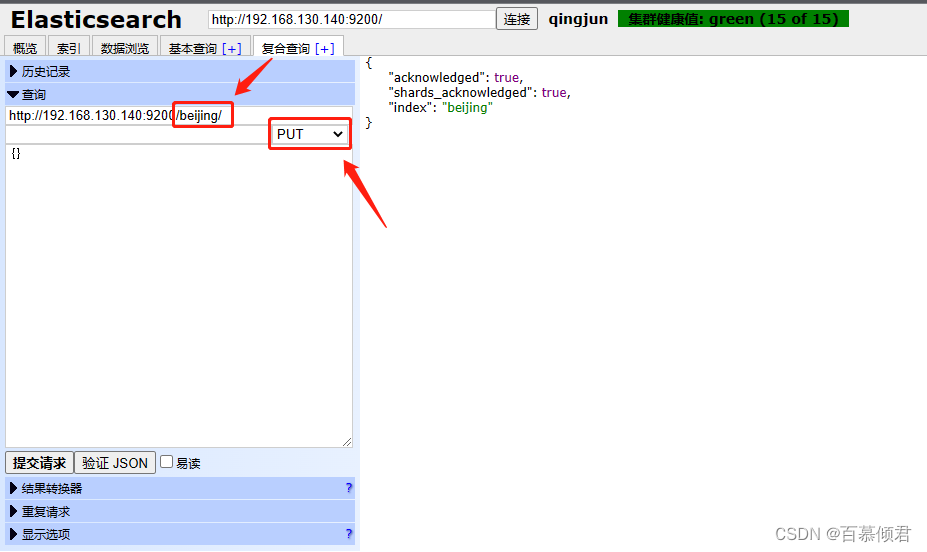
3.2.5.5 创建索引库
四、ik分词器
什么是IK分词器 ?
- 分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神"会被分为"我"“爱”“狂"神”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
注意事项:
- 如果要使用中文,建议使用ik分词器 !
- ik提供了两个分词算法:ik_smat 和ik_max_word,其中 ik_mart 为最少切分,ik_max_word为最细粒度划分!一会我们测试!
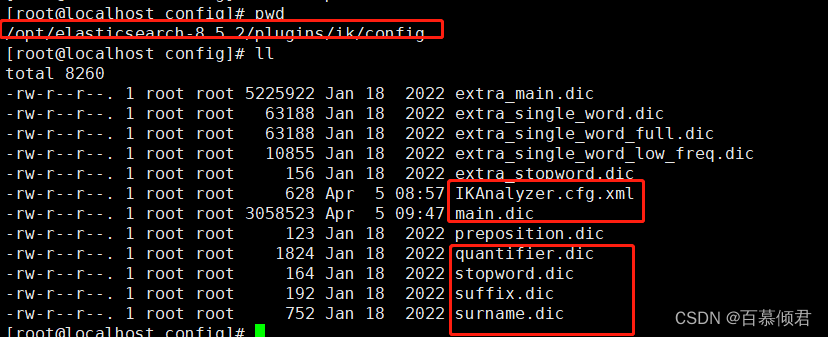
常用配置文件:
- IKAnalyzer.cfg.xml:用来配置自定义词库。
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起,最常用的文件。
- quantifier.dic:存放了一些单位相关的词。
- suffix.dic:存放了一些后缀。
- surname.dic:中国的姓氏。
- stopword.dic:包含了英文的停用词,停用词 stop word ,比如 a 、the 、and、 at 、but 等会在分词的时候直接被干掉,不会建立在倒排索引中。
4.1 Windows安装
1.下载ik分词器安装包,注意下载版本需要与安装的es版本一致。github下载地址
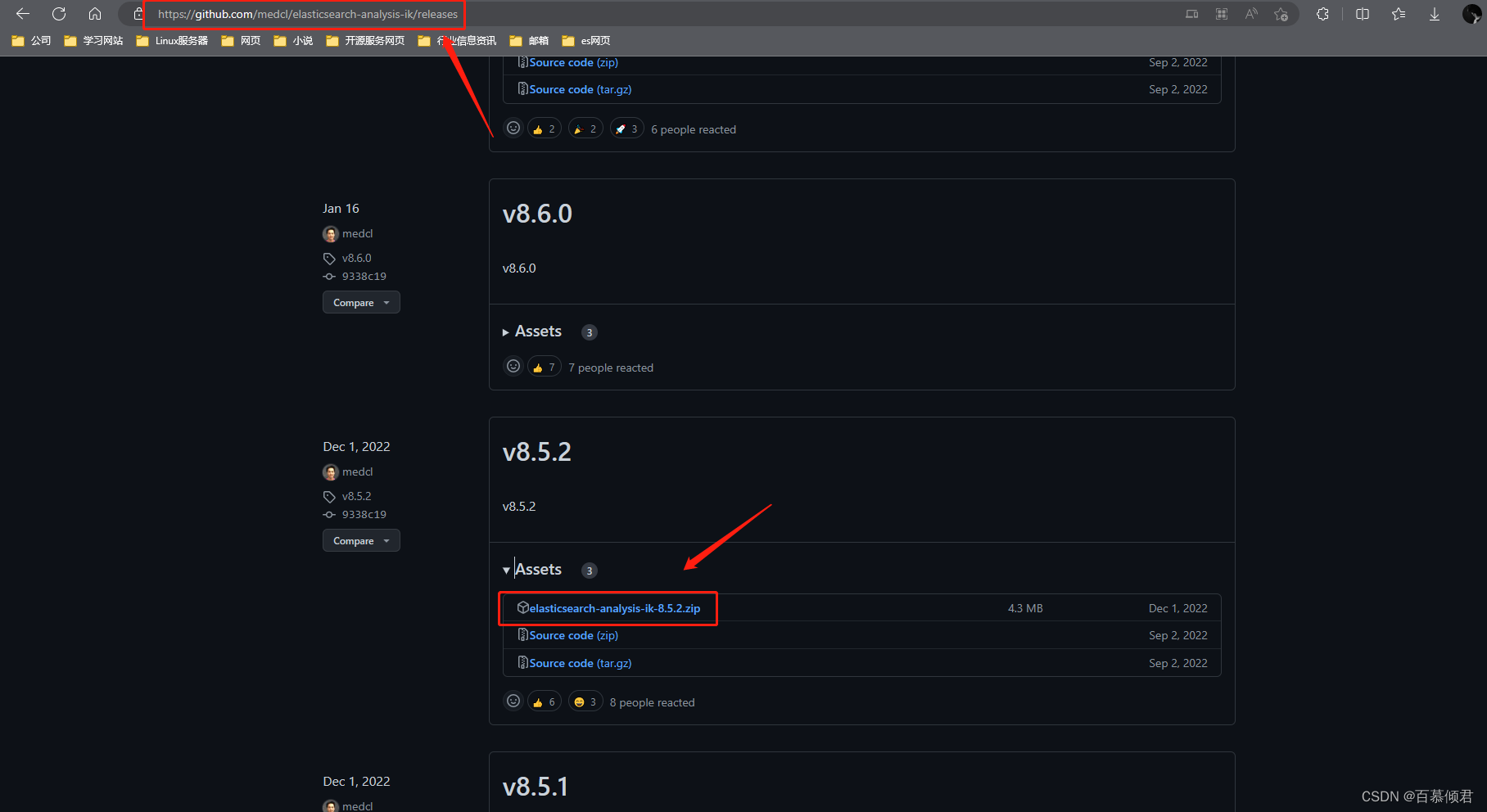
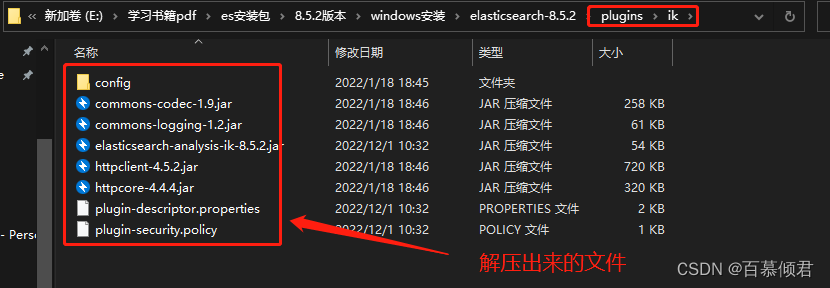
2.将下载的压缩包解压到我们本地安装es根目录下的plugins目录。我这里新增加了一个ik目录是为了好区分,该目录下的所有文件就是解压出来的。
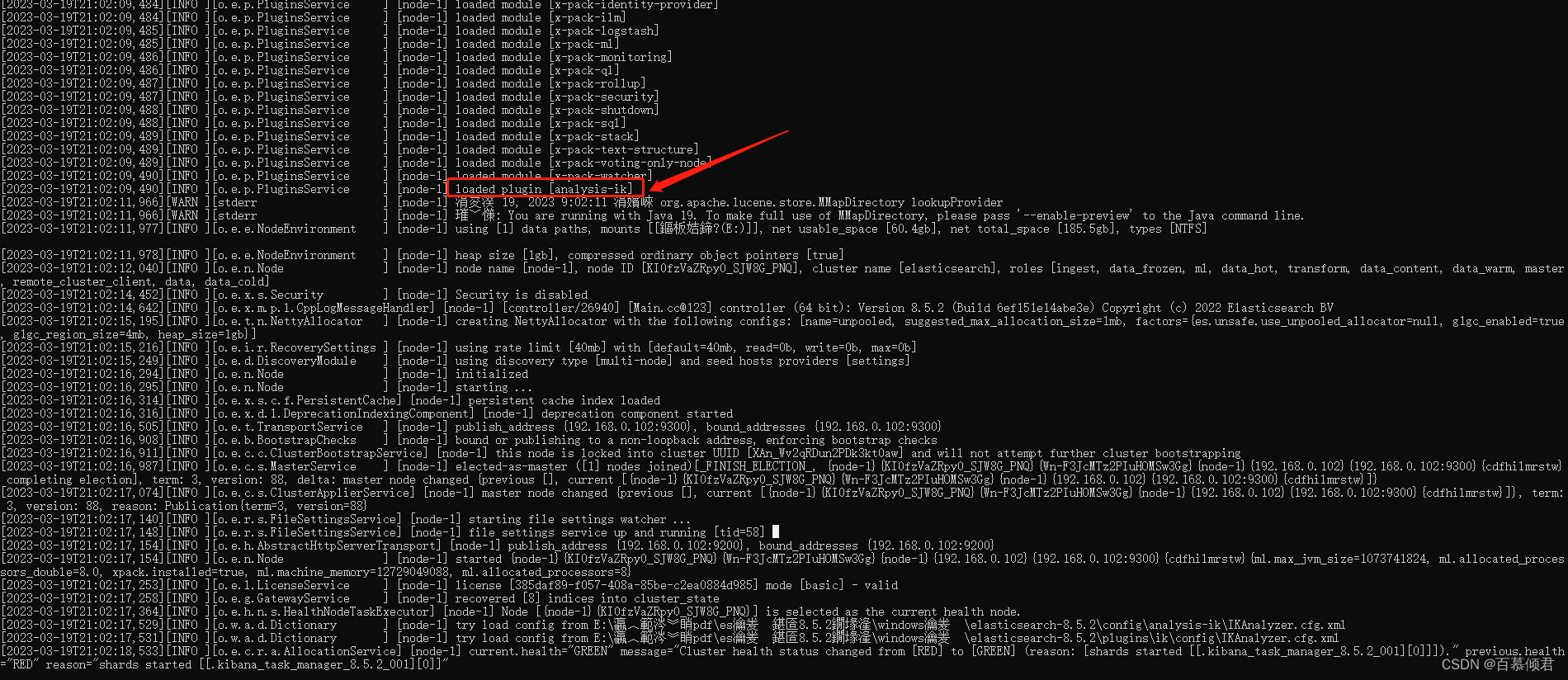
3.重启es,包括与之相关的所有服务kibana。重启再启动后能读到分词器,日志就会显示。
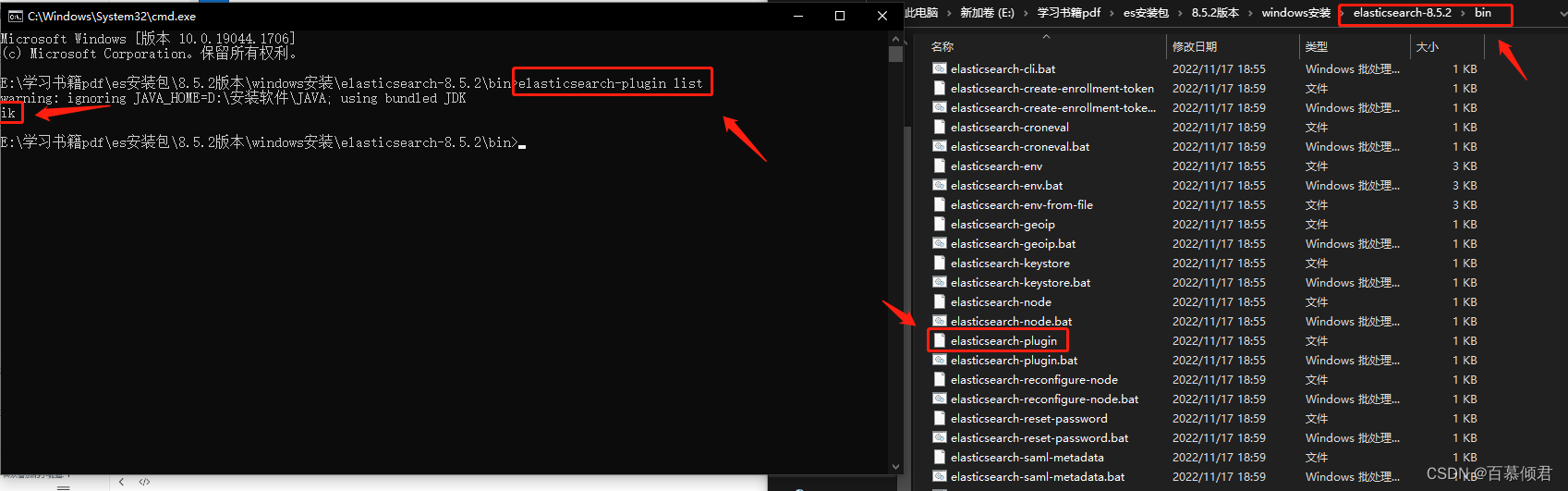
4.可以通过elasticsearch-plugin命令查看加载进来的插件,这里就显示了一个ik插件。
5.启动kibana测试。
get _analyze ##get请求,_analyze为请求对象(分词器)。下面括号内容为请求要求。
{
"analyzer": "ik_smart", ##选中ik分词器。
"text": "跟我一起学运维" ##分哪个词。
}
ik_smart为最少切分,是将一句话按段切分出来的,分出来的内容没有重复的字。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
3gVD-1712958655487)]
[外链图片转存中…(img-Tvv6qsjO-1712958655487)]
[外链图片转存中…(img-z3YU7fF0-1712958655487)]
[外链图片转存中…(img-eftk3AyQ-1712958655488)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-x3DdHPEz-1712958655488)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 8155
8155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









