







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
现如今大数据分析异常火爆,如何正确分析数据,并且抓住数据特点,获得不为人知的秘密?今天沉默带你用python爬虫,爬取淘宝网站进行淘宝商品大数据分析的实战!
文章目录
- python大数据可视化分析淘宝商品,开专卖店不行啊
- 1.1 淘宝搜索接口的分析1.1.1 cookie获取的途径
- 1.3 格式化页面,查找数据1.4 将数据存储到csv文件中
- 1.2 价格分布直方图实现逻辑1.3 商品销售地分析实现逻辑1.4 商品店名称聚集实现逻辑
通过这场项目实战,我将带你进入大数据分析的世界,并且学习爬虫技术,pandas,pyecharts,matplotlib等技术。
干货主要有:
- ① 200 多本 Python 电子书(和经典的书籍)应该有
- ② Python标准库资料(最全中文版)
- ③ 项目源码(四五十个有趣且可靠的练手项目及源码)
- ④ Python基础入门、爬虫、网络开发、大数据分析方面的视频(适合小白学习)
- ⑤ Python学习路线图(告别不入流的学习)

上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)

一、明确爬取方向
淘宝的商品数量是特别巨大的,如此海量的数据我们如何去爬取,并且分析?因此我们需要明确爬取方向。怎么才可以爬取自己想分析的数据?我们最有效的方法就是从淘宝主页的搜索接口找到突破口。
1.1 淘宝搜索接口的分析
淘宝web网站
我总结如下步骤:
- 第一步:登录淘宝网站,获取我们登录的淘宝账号
- 第二步:获取我们的cookie
- 第三步:获取搜索接口
- 第四步:分析接口,确定爬取数量
1.1.1 cookie获取的途径
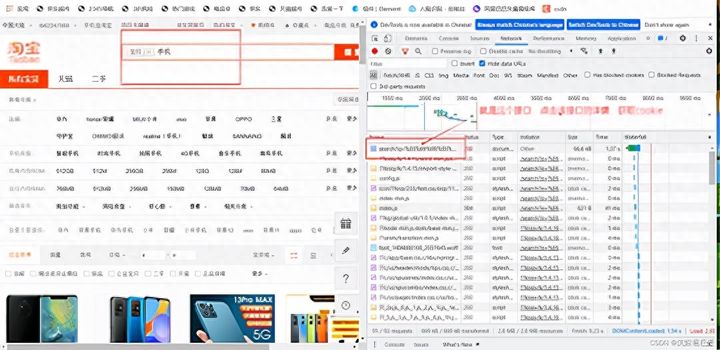
我们登录上淘宝账户后,按电脑的F12键,进入开发者模式
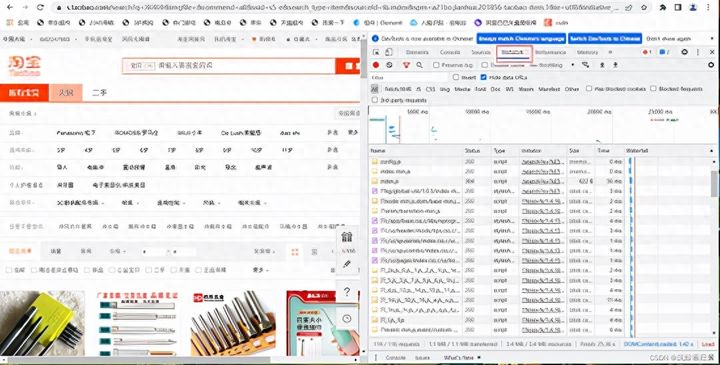
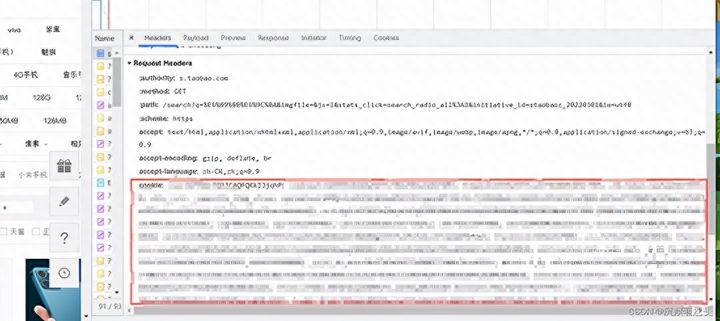
点击Network,这里就是淘宝前端接口交互的信息,然后我们随便在搜索框中搜索信息,然后在开发者框中找search接口,点击该接口,你就会找到cookie信息,复制一份信息,保存起来,待后续爬虫使用。
1.1.2 搜索接口的分析
分析搜索接口
https://s.taobao.com/search?q=小米手机&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200415&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=0
https://s.taobao.com/search?q=小米手机&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200415&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=44
https://s.taobao.com/search?q=小米手机&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200415&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=88
分析得知:每个页面参请求数基本相同,只有最后一个页码参数不同,而且是规律的: 当前页面数据 (页数-1) *
所以当我们想要将前端页面跳转至下一页爬取数据只需要将url拼接上面逻辑
运算后的数据即可。
二、爬虫脚本编写
以男士衬衫商品为例子,开展的简单数据分析,其目的是了解淘宝网站线上销售男士内裤的方法和模式。通过获取到的淘宝网站男士衬衫销售数据情况,进一步分析和判断出哪个价格区间及品牌等信息更加受到网购消费者的青睐和偏好,从而给自己买一个性价比较好的衬衫。
1.1引入库
代码如下(局部):
# -*- coding: utf-8 -*-
import requests
import re
import pandas as pd
import time
如果上述的的库没有下载,请安装后在使用;(如果没有安装库,就会爆红)
1.2 获取页面信息
# 此处写入登录之后自己的cookies
cookie = ''
# 获取页面信息
def getHTMLText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
user_cookies = cookie
cookies = {
}
for a in user_cookies.split(';'): # 因为cookies是字典形式,所以用spilt函数将之改为字典形式
name, value = a.strip().split('=', 1)
cookies[name] = value
try:
r = requests.get(url, cookies=cookies, headers=headers, timeout=60)
print(r.status_code)
print(r.cookies)
return r.text
except:
print('获取页面信息失败')
return ''
1.3 格式化页面,查找数据
# 格式化页面,查找数据
def parsePage(html):
list = []
try:
views_title = re.findall('"raw_title":"(.*?)","pic_url"', html)
print(len(views_title)) # 打印检索到数据信息的个数,如果此个数与后面的不一致,则数据信息不能加入列表
print(views_title)
views_price = re.findall('"view_price":"(.*?)","view_fee"', html)
print(len(views_price))
print(views_price)
item_loc = re.findall('"item_loc":"(.*?)","view_sales"', html)
print(len(item_loc))
print(item_loc)
views_sales = re.findall('"view_sales":"(.*?)","comment_count"', html)
print(len(views_sales))
print(views_sales)
comment_count = re.findall('"comment_count":"(.*?)","user_id"', html)
print(len(comment_count))
print(comment_count)
shop_name = re.findall('"nick":"(.*?)","shopcard"', html)
print(len(shop_name))
for i in range(len(views_price)):
list.append([views_title[i], views_price[i], item_loc[i], comment_count[i], views_sales[i], shop_name[i]])
# print(list)
print('爬取数据成功')
return list
except:
print('有数据信息不全,如某一页面中某一商品缺少地区信息')
1.4 将数据存储到csv文件中
# 存储到csv文件中,为接下来的数据分析做准备
def save_to_file(list):
data = pd.DataFrame(list)
data.to_csv('F:\\Github\\pythonobject\\taobao\\商品数据.csv', header=False, mode='a+') # 用追加写入的方式
1.5 完整代码
# -*- coding: utf-8 -*-
import requests
import re
import pandas as pd
import time
# 此处写入登录之后自己的cookies
cookie = ''
# 获取页面信息
def getHTMLText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
user_cookies = cookie
cookies = {
}
for a in user_cookies.split(';'): # 因为cookies是字典形式,所以用spilt函数将之改为字典形式
name, value = a.strip().split('=', 1)
cookies[name] = value
try:
r = requests.get(url, cookies=cookies, headers=headers, timeout=60)
print(r.status_code)
print(r.cookies)
return r.text
except:
print('获取页面信息失败')
return ''
# 格式化页面,查找数据
def parsePage(html):
list = []
try:
views_title = re.findall('"raw_title":"(.*?)","pic_url"', html)
print(len(views_title)) # 打印检索到数据信息的个数,如果此个数与后面的不一致,则数据信息不能加入列表
print(views_title)
views_price = re.findall('"view_price":"(.*?)","view_fee"', html)
print(len(views_price))
print(views_price)
item_loc = re.findall('"item_loc":"(.*?)","view_sales"', html)
print(len(item_loc))
print(item_loc)
views_sales = re.findall('"view_sales":"(.*?)","comment_count"', html)
print(len(views_sales))
print(views_sales)
comment_count = re.findall('"comment_count":"(.*?)","user_id"', html)
print(len(comment_count))
print(comment_count)
shop_name = re.findall('"nick":"(.*?)","shopcard"', html)
print(len(shop_name))
for i in range(len(views_price)):
list.append([views_title[i], views_price[i], item_loc[i], comment_count[i], views_sales[i], shop_name[i]])
# print(list)
print('爬取数据成功')
return list
except:
print('有数据信息不全,如某一页面中某一商品缺少地区信息')
# 存储到csv文件中,为接下来的数据分析做准备
def save_to_file(list):
data = pd.DataFrame(list)
data.to_csv('F:\\Github\\pythonobject\\taobao\\商品数据.csv', header=False, mode='a+') # 用追加写入的方式
def main():
name = [['views_title', 'views_price', 'item_loc', 'comment_count', 'views_sales', 'shop_name']]
data_name = pd.DataFrame(name)
data_name.to_csv('F:\\Github\\pythonobject\\taobao\\商品数据.csv', header=False, mode='a+') # 提前保存一行列名称
goods = input('请输入想查询的商品名称:'.strip()) # 输入想搜索的商品名称
depth = 5 # 爬取的页数
start_url = 'https://s.taobao.com/search?q=' + goods # 初始搜索地址
for i in range(depth):
time.sleep(3 + i)
try:
page = i + 1
print('正在爬取第%s页数据' % page)
url = start_url + 'imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200408&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=' + str(
44 * i)
html = getHTMLText(url)
# print(html)
list = parsePage(html)
save_to_file(list)
except:
print('数据没保存成功')
if __name__ == '__main__':
main()
运行项目,输入男士衬衫,回车,自动爬取数据
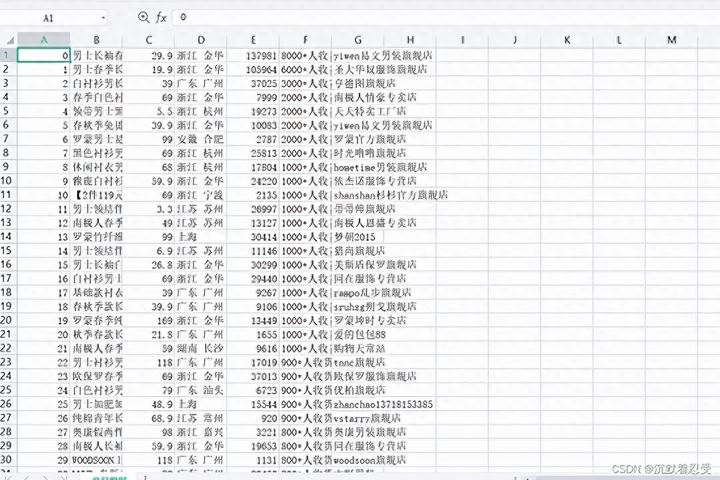
保存的商品信息csv文件:
三、数据可视化实现
数据可视化说白了,也就是通过数据分析,将得出的结果用图表的形式展示出来,图表的展示无非就是k,v的方式实现,所以我们可以借助pandas,将海量的数据分析出来,并且将分析后的数据处理成可视化表所识别的数据格式就可以实现数据可视化。我们这里可视化依赖于pyecharts和matplotlib。
1.1 引入依赖
没有以下库的请下载安装
import pandas as pd
import operator
from matplotlib import pyplot as plt
import matplotlib as mpl
from pyecharts.charts import Bar, Pie
# 用于设值全局配置和系列配置
from pyecharts import options as opts
mpl.rcParams['font.sans-serif'] = ['KaiTi'] # 画图时显示中文
mpl.rcParams['font.serif'] = ['KaiTi']
data = pd.read_csv('F:\\Github\\pythonobject\\taobao\\商品数据.csv', encoding='utf-8')
1.2 价格分布直方图实现逻辑
# 商品价格分析
def priceshow():
print(data['views_price'].describe())
# 价格分布直方图
plt.figure(figsize=(16, 9)) # 这里是图片长宽比例
plt.hist(data['views_price'], bins=30, alpha=0.4, color='orange')
plt.title('价格频数分布直方图')
plt.xlabel('价格')
plt.ylabel('频数')
plt.savefig('价格分布直方图.png')
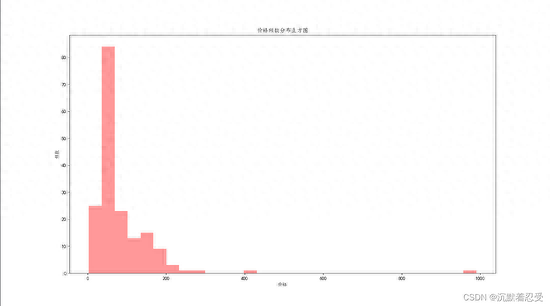
1.3 商品销售地分析实现逻辑
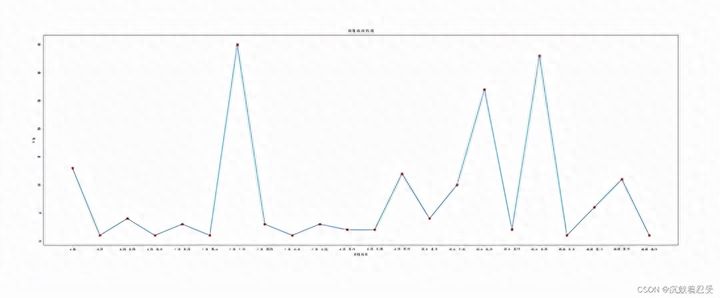
# 分析商品的数据(商品销售地分析)
def shop_localdatashow():
# 销售地分布
group_data = list(data.groupby('item_loc'))
loc_num = {
}
for i in range(len(group_data)):
loc_num[group_data[i][0]] = len(group_data[i][1])
print(loc_num)
plt.figure(figsize=(30, 10))
plt.title('销售地折线图')
plt.scatter(list(loc_num.keys()), list(loc_num.values()), color='r')
plt.plot(list(loc_num.keys()), list(loc_num.values()))
plt.xlabel('销售地区')
plt.ylabel('个数')
plt.savefig('销售地.png')
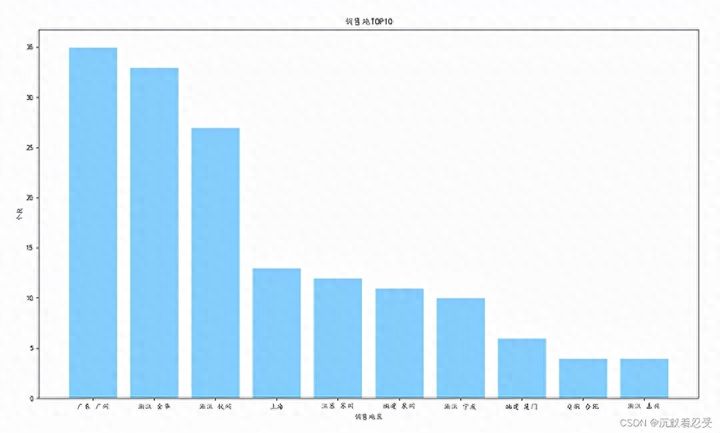
sorted_loc_num = sorted(loc_num.items(), key=operator.itemgetter(1), reverse=True) # 排序
loc_num_10 = sorted_loc_num[:10] # 取前10
loc_10 = []
num_10 = []
for i in range(10):
loc_10.append(loc_num_10[i][0])
num_10.append(loc_num_10[i][1])
plt.figure(figsize=(16, 9))
plt.title('销售地TOP10')
plt.xlabel('销售地区')
plt.ylabel('个数')
plt.bar(loc_10, num_10, facecolor='lightskyblue', edgecolor='white')
plt.savefig('销售地TOP10.png')
top10生产地表
1.4 商品店名称聚集实现逻辑
数据获取,通过pyecharts展示数据

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
_convert/47d1a90dbecac9b794d04a65fbb67a93.jpeg)
1.4 商品店名称聚集实现逻辑
数据获取,通过pyecharts展示数据
[外链图片转存中…(img-3HvJKpmR-1714973477266)]
[外链图片转存中…(img-jOLyuvRa-1714973477267)]
[外链图片转存中…(img-neS9Ni13-1714973477267)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 3585
3585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









