







纸上得来终觉浅,绝知此事要躬行。本文记录如何使用Pandas、Matplotlib基础知识对爬取的ipad信息作可视化,包括如下内容:
-
价格分布
-
销量对比
-
店铺销量前20
-
发货地省份统计
数据准备 :某宝ipad商品信息(戳这里查看爬取过程)
数据转换 原始数据里,价格和销量数据类型不是整型或者浮点数,需要将其转换格式后才能更好的定量分析,下面是我转换后的数据。

因为有些商品没有销量,我在爬取的时候默认以“未知”填充,转换后以NaN值替换“未知”,表示该商品销量数据缺失。
初步筛选 导入Pandas库,使用read_csv()方法读取我们准备好的数据
data = pd.read_csv('data.csv',names=['origin','name',"price",'sale','shop'],index_col=["name"]) # 读取数据删除NaN 缺失数据不在分析范围内,故将所有带有NaN值的商品删除(即每一行带有NaN值都删去)
data.dropna(axis=0,how="any")排序和再筛选 转换,删除NaN值后的数据还不能直接使用,注意分析的是ipad,但是表格里充斥着许多的ipad配件商品,而且有些平板品牌也不是ipad(在此假定所有平板均为ipad),爬虫无法区分哪些是平板,哪些是配件,一股脑全部爬取。在此我们划定一个价格阙值=500,低于阙值即认为是配件,因为配件一般比主机便宜(纯属经验划分)
data = data[(data['price'] > 500)] # 筛选价格超过500的数据price = data.price #选取价格sale = data.sale #选取销量
现在我们已经拿到很纯的价格和销量数据了,关于如何在DataFrame里统计特定数值的频数,我还不清楚,不过可以曲线统计,Python列表数据提供有count()方法统计元素出现个数,只需将店铺整列提取出来,转换为列表,然后统计,排序后选取前20个。
# 统计值出现的次数def filter(lis):count = {}for i in lis:count[i] = lis.count(i)return count #返回类型为字典,省名为键,次数为值
另外商品发货地格式并不统一,有些仅定位到省,有些则定位到地级市,需要将省份提取出来再进行统计,排序后,选取前七名,第七名以后的统计为"其他"。
origins = DataFrame({"origin":filter(origin)}).sort_values(axis=0,by="origin",ascending=False) # 转换为DataFrame类型,然后降序排序# 同样地选取店铺后统计出现次数,再转换为DataFrame类型,排序后选取前20个shop = DataFrame({"count":filter(data.shop.values.tolist())}).sort_values(axis=0,by="count",ascending=False)['count'][:20]other = origins['origin'][7:].sum() # 计算第七个后的发货地次数总和,记为其他piedata = origins['origin'][:7].tolist() + [other]province_info = origins.index.tolist()[:7] + ['其他']
到此所有的数据都准备好,下一步使用Matplotlib绘制图像
开始绘图
在绘制图像之前,先来捋清楚什么样的数据该选择什么样的数据图来展示呢?
上述准备好的数据可以分为定性数据和定量数据,针对这两种数据的展示互有差异,但又相辅相成。
定性数据:是一组表示事物性质、规定事物类别的文字表述型数据,如省份。
定量数据:指以数量形式存在着的属性,并因此可以对其进行测量,以物理量为例,距离、质量、时间等都是定量数据。
常用数据展示图 :
-
直方图 适合比较不同对象间的数值差异
-
饼图 重点体现数据的类型和所占整体的比例
-
折线图 重点体现数据的变化趋势和未来走向,适合以时间为自变量的数据
-
雷达图 重点体现数据间不同维度之间的差异
-
散点图 考察两个变量之间的关系
-
风向玫瑰图 反映一个对象的方向和频率(个人感觉风向玫瑰图和雷达图表示类型相似)
-
柱状图 对比不同类别数据间的差异
-
箱型图 适合展示一组数据的分散情况
-
热力图 以特殊高亮的形式显示访客热衷的页面区域和访客所在的地理区域的图示
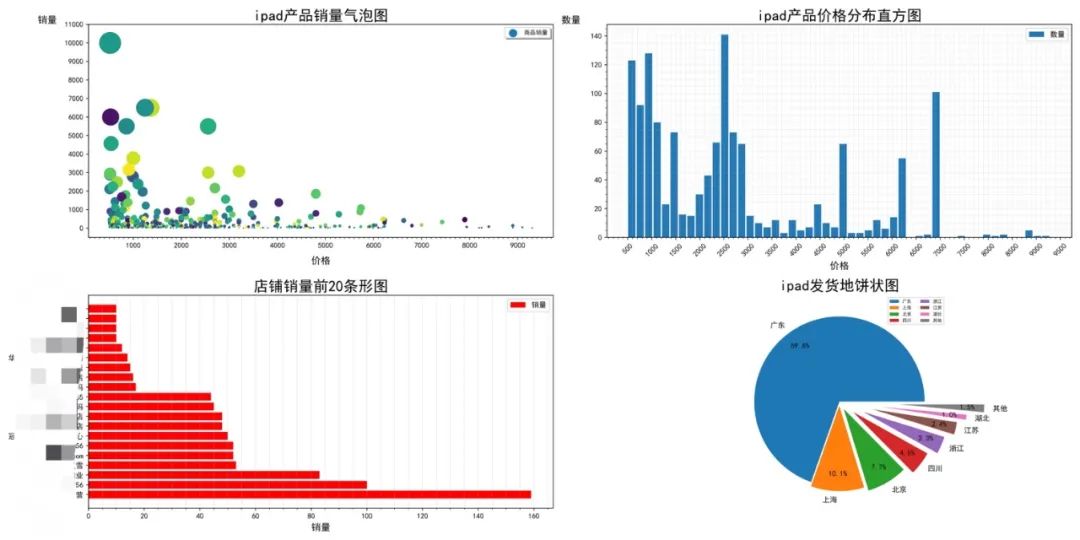
基于上述理解,我将使用直方图展示价格分布、用柱状图展示店铺前20销量、用气泡图展示价格和销量之间的关系、用饼图展示商品按省份归类后的比值分布。
先对图做一个划分,要在一张图上展示四张子图
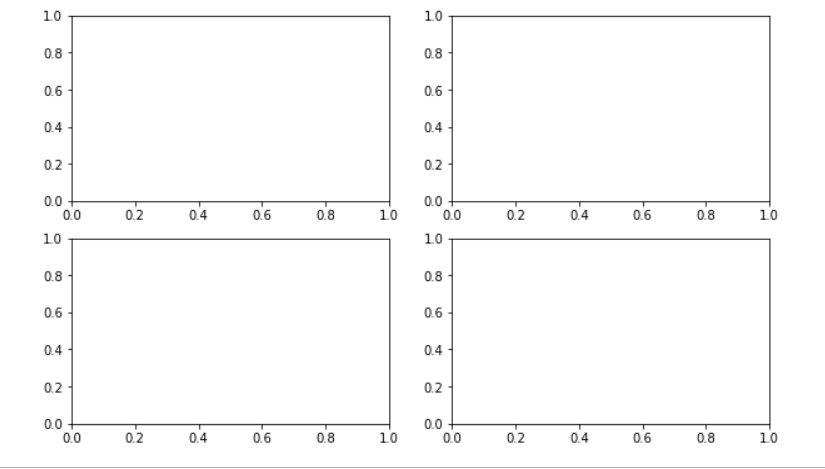
大小相等子图
我用subplots(2,2)方法划分子图区域,可以看到每一个子图,其大小等同,如果想控制子图大小,实现如下效果,推荐使用GridSpec类实现
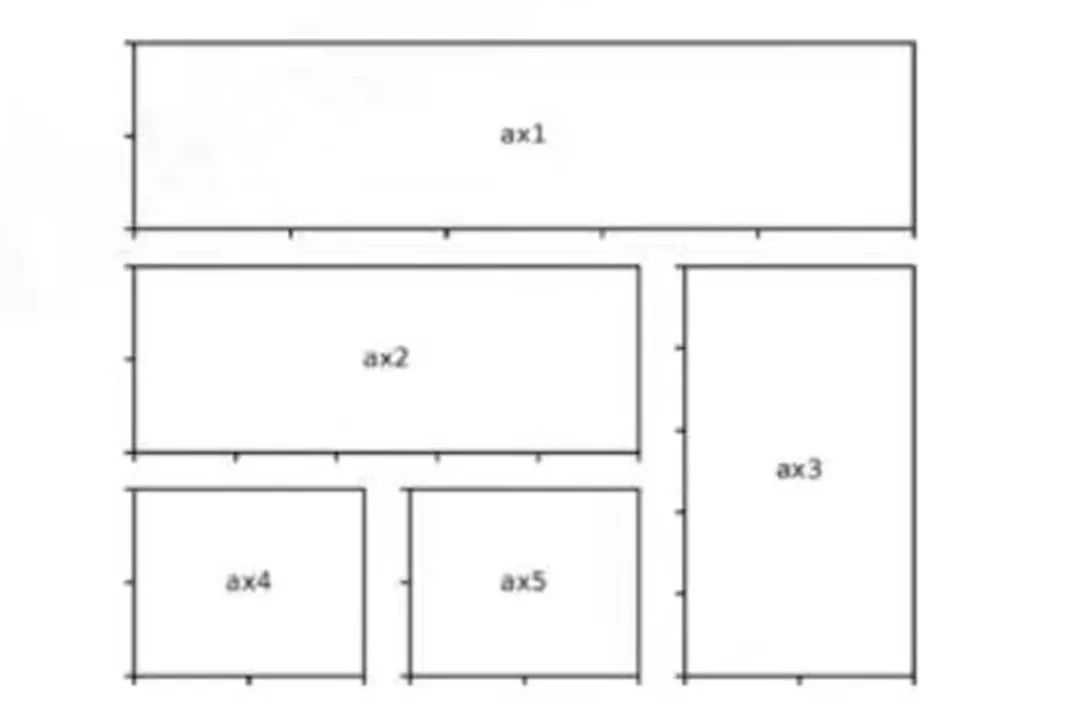
大小不等同子图
具体图像如何绘制(戳这里回顾绘图函数),仅展示代码,在绘图过程中出现如下问题:
-
默认刻度不美观,如何自定义刻度
-
饼图图例过大,遮挡饼图展示
-
添加图例、标题、轴标签后子图互相遮掩
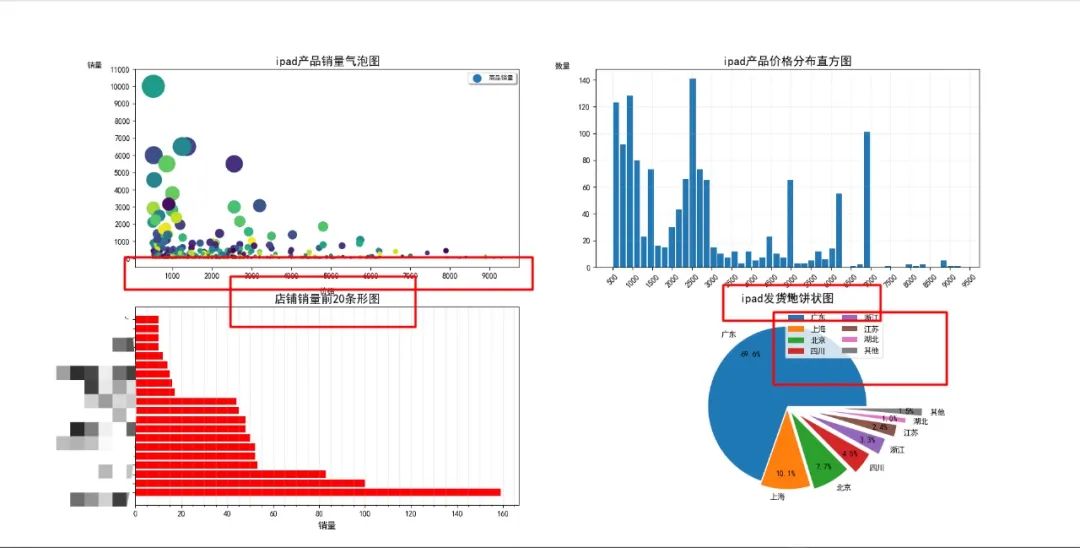
子图部分遮掩,饼图图例过大,无次要刻度
以上问题解决方法:
-
可通过如下方法设定主次要刻度
ax.x/yaxis.set_major_locator(),ax.x/yaxis.set_minor_locator()
-
饼图图例过大,可设置图例字体调整
-
修改配置参数
rcParams.update({"figure.autolayout":True}),防止子图互相遮掩
完整代码,重要语句都写了注释的
# -*- coding: utf-8 -*-
"""
@Date: 2021/3/25 23:01
@File: ipad_nanalysis.py
@Software: PyCharm
"""
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame,Series
from matplotlib import ticker ,rcParams
# 配置
rcParams.update({'figure.autolayout':True}) # 防止子图出现重叠
rcParams['font.family']= "SimHei" # 设置中文字体
rcParams['axes.unicode_minus']=False # 坐标轴显示负号
# 清洗和筛选数据
data = pd.read_csv('data.csv',names=['origin','name',"price",'sale','shop'],index_col=["name"]).dropna(axis=0,how="any") # 读取数据
data = data[(data['price'] > 500)] # 筛选价格超过500的数据
price = data.price #选取价格
sale = data.sale #选取销量
origin = [i.split(" ")[0] for i in data.origin] # 筛选发货地,有些发货地格式为省份在前城市在后,如:广东 深圳,但在此仅需省份
# 统计省份出现的次数
def filter(lis):
count = {}
for i in lis:
count[i] = lis.count(i)
return count #返回类型为字典,省份名为键,次数为值
origins = DataFrame({"origin":filter(origin)}).sort_values(axis=0,by="origin",ascending=False) # 转换为DataFrame类型,然后降序排序
# 同样地选取店铺后统计出现次数,再转换为DataFrame类型,排序后选取前20个
shop = DataFrame({"count":filter(data.shop.values.tolist())}).sort_values(axis=0,by="count",ascending=False)['count'][:20]
other = origins['origin'][7:].sum() # 计算第七个后的发货地次数总和,记为其他
piedata = origins['origin'][:7].tolist() + [other]
province_info = origins.index.tolist()[:7] + ['其他']
# 气泡图
fig ,ax = plt.subplots(2,2,figsize=(20,10))
ax1,ax2,ax3,ax4 = ax[0][0],ax[0][1],ax[1][0],ax[1][1]
ax1.scatter(x=price,y=sale,s=sale * 0.08,c=np.random.randint(0,1000,(len(sale),)),label="商品销量",)
# 设置y轴限度
ax1.set_ylim(-500,max(sale) + 1000)
# 设置xy轴的主要,次要刻度
ax1.xaxis.set_major_locator(ticker.MultipleLocator(1000))
ax1.yaxis.set_major_locator(ticker.MultipleLocator(1000))
ax1.xaxis.set_minor_locator(ticker.MultipleLocator(100))
# 添加图例,标题,轴标签
ax1.legend(fontsize=8,shadow=True,frameon=True,markerscale=0.5)
ax1.set_title("ipad产品销量气泡图",pad=5,fontsize=15)
ax1.set_xlabel("价格",fontsize=10,labelpad=10)
ax1.set_ylabel("销量",rotation=0,labelpad=10,loc="top")
# 直方图
ax2.hist(price,bins=50,width=150)
ax2.xaxis.set_major_locator(ticker.MultipleLocator(500))
ax2.set_xlabel("价格",fontsize=10,labelpad=5)
ax2.set_ylabel("数量",rotation=0,labelpad=10,loc="top")
ax2.set_title("ipad产品价格分布直方图",fontsize=15,pad=5,fontweight="bold")
ax2.yaxis.set_minor_locator(ticker.MultipleLocator(5))
ax2.xaxis.set_minor_locator(ticker.MultipleLocator(100))
ticklabel = ax2.xaxis.get_ticklabels()
plt.setp(ticklabel,fontsize=10,rotation=45)
ax2.grid(alpha=0.3,linewidth=0.5,which="both") #添加网格
# 饼图
ax4.pie(piedata,labels=province_info,explode=[0,0.05,0.1,0.2,0.3,0.4,0.5,0.7],autopct="%.1f%%",pctdistance=0.8,textprops={'fontsize':10},)
ax4.legend(loc="best",ncol=2,fontsize=6)
ax4.set_title("ipad发货地饼状图",fontsize=15)
# 条形图
ax3.barh(shop.index,width=shop.values,color="red")
# 设置次要刻度
ax3.xaxis.set_minor_locator(ticker.MultipleLocator(5))
ax3.grid(axis='x',which="both",alpha=0.3)
ax3.set_title("店铺销量前20条形图",fontsize=15,pad=5)
ax3.set_xlabel("销量",fontsize=12,labelpad=5)
#plt.savefig("taobao_info.png",dpi=500)
plt.show()相关数据仅作学习用,侵权请联系

















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









