







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
写在前面
- 很多粉丝经常私信问我有关指针、链表相关的问题,也非常希望我出一篇有关链表的教学,最近刚好也在整理有关单链表相关的知识点,便作了此文,为大家讲解有关单链表方面的各块知识点。
- 本文考虑到阅读者的水平和能力,内容有深有浅,总体讲解主要是从浅入深循序渐进地阐述有关链表相关的知识


链表真的很难吗?
- 一、前言
- 二、链表的初步认知
- 三、接口算法实现【是时候表演真正的技术了🆒】
- 四、整体代码展示【需要自取】
- 五、有关二级指针和断言的小结【⭐谨记⭐】
- 六、OJ题目实训
- 七、总结与提炼
一、前言
1、顺序表的缺陷【生活小案例1——盛20粒米饭🍚】
缺陷1:空间经常会不够,需要扩容
- 在上一节,我们讲到了顺序表基本函数结构的算法实现,说到了顺序表其实和数组本质差不多,存放的数据都是连续的,但是通过一些头插、尾插和万能插入可以看出顺序表在有些情况下可能会出现空间不够,需要扩容的操作,而且对于扩容机制,我们上次讲到了【本地扩容】和【异地扩容】,尤其是对于异地扩容,需要先释放掉原先存放的地址,然后再去异地申请一块地址,这其实是需要一定代价的
- 对于扩容的大小来说,一扩就是原来的2倍,这些扩出来的2倍我们不一定都能使用得完,所以就存在一定的空间浪费。那有同学说你怎么知道会用不完呢,万一我用完了呢,其实这你我都不敢肯定自己需要使用多大的空间,只是知道现在的空间不够了,需要再申请一些空间
- 这其实就是我们吃饭的时候吃了一碗不够需要再去盛一碗是一样的,那一碗不够你可能就会去盛两碗,但是有点时候两碗又吃不完(能吃完的请忽略😄),所以这个时候我们就会选择少盛一点,但是盛少了又不够吃,如果给你盛1碗20粒米饭这多出来的20粒米你觉得真的够吃吗,所以你还会再去盛。所以要盛多少呢?这就好比我们去申请空间,若是申请得太少了,就可能需要频繁地再去申请,但若是申请得太多了就会用不完,浪费
缺陷2:插入或删除数据时需要挪动大量数据,效率低下
- 虽然有了万能插入,但是我们前面在写头插、尾插、头删、尾删的时候花了不少的功夫去解决这些难题,对于头插,需要将数据从后往前一一后移;对于头删,需要将数据从前往后一一前移,这两种情况就是插入和删除中最坏的两种,时间复杂度接近O(N),因此我们可以看出对于顺序表它还具有一大缺陷就是
对于数据的插入和删除需要挪动大量的数据,因为时间复杂度的过高,导致效率的低下
2、优化方案
因为我们就应该对这两种缺陷做一个改进
- 对于空间不够需要扩容的情况,我们可以使用动态申请,就像动态顺序表那样使用malloc来申请所需要的空间,需要存储一个数据就开一块空间,在本节要介绍的【链表】中,叫做【结点】,当然有些书上写叫做【节点】,这个都可以,没有区别,随你怎么叫。
- 对于增删需要挪动大量数据的情况,我们可以使用一种手段将前后两个结点之间做一个联系,也就是前一个结点存放下一个结点在堆区中申请的那块内存地址,也就是我们在C语言中所学到的指针可以存放一块地址,这样就使得前一个结点和后一个结点产生了一定的关联。然后当我们需要去插入或者删除数据时,只需要修改当前结点所存放的内存地址即可,修改了所存放的地址值,这个时候便与新的结点产生了联系
对于链表这一块,如果C语言的指针和结构体这一块你没有很熟悉的话,学起来确实会比较困难,但这也不妨碍你看本文,我一定会慢慢地带你从浅到深,去领会链表该如何操作
二、链表的初步认知
1、结构的声明与定义
- 首先里看一下链表的结构,它的每一个结点因为要存放数据和下一个结点的地址,因此需要一个数据域、一个指针域,如下图所示👇

- 了解了链表的结构体是如何的,接下来我们用代码的形式将其展现出来
- 可以看到,这里数据域的类型是单独typedef的,这个在顺序表中讲过,因为每一个数据可能并不是整型的,可能是char、long或者是double类型。对于next指针域,你可以看到其为一个结构体指针类型,因为这个next指针,它指向的下一个结点又是一个封装好的结构体。
typedef int SLTDataType;
typedef struct SListNode { //结构体大小:8B
SLTDataType data;
struct SListNode\* next;
//SLTNode\* next; 不可以这样定义,因为还没有到声明
}SLTNode;
- 此处的结构体类型我们也进行了一个typedef,但是当这个结构体声明出来后,有同学就把这个next指针的类型就定义成了typedef后的类型,这个是不对的,如果你这样定义,那说明你的结构体学的不扎实,这是一种错误的定义方式,此处的SLTNode还没有声明出来,所以是不可以使用的
- 它的定义格式实际上是这样的,当你去使用SLTNode定义next指针时,它还没有被声明出来
typedef int SLTDataType;
struct SListNode { //结构体大小:8B
SLTDataType data;
struct SListNode\* next;
};
typedef struct SListNode SLTNode;
2、栈区存放与堆区存放
明白了如何去定义一个结构体,接下去我们就用这个定义的结构体试着去创建一两个结点,然后对它们进行一个链接,我用了下面两种定义和链接方法,你觉得哪个更好呢?
第一种,指针类型【动态开辟】
SLTNode\* n1 = (SLTNode\*)malloc(sizeof(SLTNode));
SLTNode\* n2 = (SLTNode\*)malloc(sizeof(SLTNode));
n1->next = n2;
第二种,变量类型【直接定义】
SLTNode n3, n4;
n3.next = &n4;
- 那有小伙伴可能就被难住了,接下来听我给你说说👊
- 对于链表,当我们去定义一个个结点进行插入的时候,都是希望在最后能将这些结点链接成为一个线性表一样,所以想让它保存在最后。但是第二种直接定义的变量类型却做不到这一点,这样的定义方式属于一种局部变量的定义,对于局部变量的定义,是在内存中的【栈区】为其开辟空间的,这就是我们常说的【栈帧】,函数中的变量定义就需要消耗一定的栈帧,但你这个函数结束之后,那这个栈帧也就销毁了,此时你辛辛苦苦链接起来的链表中各个结点的数据也就随着栈帧的销毁而荡然无存了,这其实就相当于是出Bug了
- 但若是用上面一种定义方式去弄的话,就不会造成这样的现象,之前我们有说到过,对于动态申请的空间,是存放在内存【堆区】中的,而对于堆区中存放的内容,是到程序结束才会销毁,而且上面提到,对于每一个链表结点,我们最好使用动态开辟的方式是申请空间,这样的弹性就更加大一些,不会像顺序表那样需要不断地扩容
3、开始链接结点啦🎉【逻辑结构与物理结构的区分】
- 明白了要使用malloc去动态开辟结点,将其存放在【堆区】中,接下去就开辟几个结点,然后将他们进行一个链接
SLTNode\* BuySLTNode(SLTDataType x)
{
//动态开辟
SLTNode\* newnode = (SLTNode\*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
}
- 可以看到,这里我将动态开辟一块空间并且初始化结点值封装成了一个叫【BuySLTNode】的函数,也就是得到一个链表结点,最后用一个链表结构体类型去接收一下,就有了四个结点值,最后将他们一一链接起来即可🔒
SLTNode\* n1 = BuySLTNode(1);
SLTNode\* n2 = BuySLTNode(2);
SLTNode\* n3 = BuySLTNode(3);
SLTNode\* n4 = BuySLTNode(4);
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;
- 那个这四个结点在你脑海中链接起来是什么样子的呢,我想一定是下面这种样子,每个结点对应一个变量,然后其next指针域使用一个箭头符号指向下一个结点
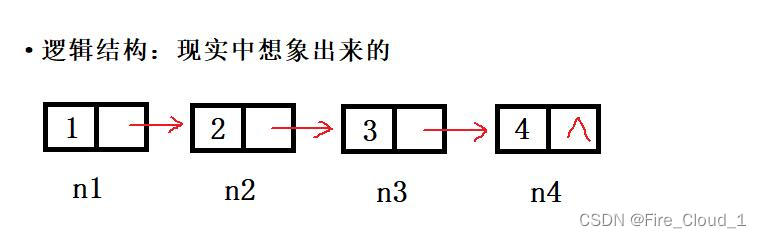
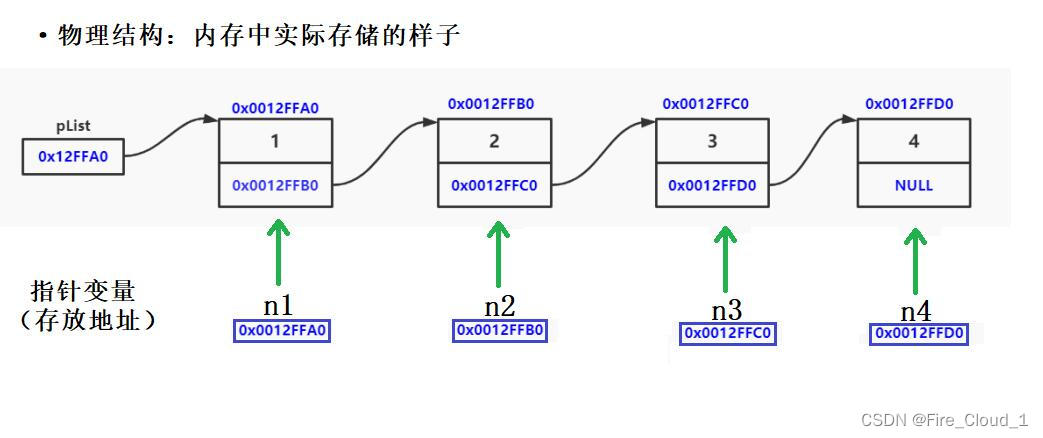
- 这是大多数人的思维,但是在计算机实际的内存中,可不是这样存储的,真正的物理结构是下面这样
- 当你申请出了一块空间,然后初始化这个结点的值并且用一个结构体链表结点去接收的时候,这个n1,n2,n3,n4并不是普通的变量,而是一个指针变量,一个
结构体指针变量,既然是指针那就一定指向一块内存地址,也就是我们在Buy一个结点的时候为这个结点所申请的这块内存地址,而当你去解引用这个指针变量时,也就拿到了这块内存的地址值,这其实就可以解释了为什么n1->next = n2,是等于n2,而不是一个内存地址值,因为这个n2中存放的就是当前这个结点在堆区中申请的这块地址
n1->next = n2;
n2->next = n3;
n3->next = n4;
n4->next = NULL;
- 接下去我解释一下这些结点之间的联系,对于这些结点我们上面说过了,具有一个数据域和一个指针域,对于指针域,它与下一个结点之间的关系其实并不是用一个箭头去指向的,当然下面的这张图我只是为了更加形象,当前结点指针域与下一个结点之间的关系应该是当前结点指针域存放下一个结点在堆区中申请的内存地址
- 那这么说可能还是不太直观,我们进编译器中去DeBug一探究竟🔍
- 可以看出,确实是这样,这下你应该有所理解了吧

4、运行起来了,开始玩链表
搞清楚了链表的各个结点直接是如何前后链接起来的,接下去我们正式地来玩一玩💷,申请多个结点将他们串起来
SLTNode\* BuySLTNode(SLTDataType x)
{
//动态开辟
SLTNode\* newnode = (SLTNode\*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
}
SLTNode\* SListCreate(int n)
{
SLTNode\* phead = NULL, \* ptail = NULL;
for (int i = 0; i < n; ++i)
{
SLTNode\* newnode = BuySLTNode(i);
if (phead == NULL)
phead = ptail = newnode;
else
{
ptail->next = newnode;
ptail = newnode;
}
}
return phead;
}
- 解释一下新写的这段逻辑,通过传进来需要构建的n个结点,我们需要通过循环去一一搭建,那我们就需要使用到构建链表的一个很重要逻辑——尾插法,首先我们要去定义一个头结点指针和一个尾结点指针,对于链表,有
带头结点和不带头结点的类型,后面我会详细介绍。对于这个头结点指针phead,就是用来保存头结点的,对于这个ptail尾结点指针,就是用来链接数据的,将每一个待插入的结点链接到当前尾结点指针的后一个结点,也就是执行这句
ptail->next = newnode;
ptail = newnode;
- 我们通过图示来看一下

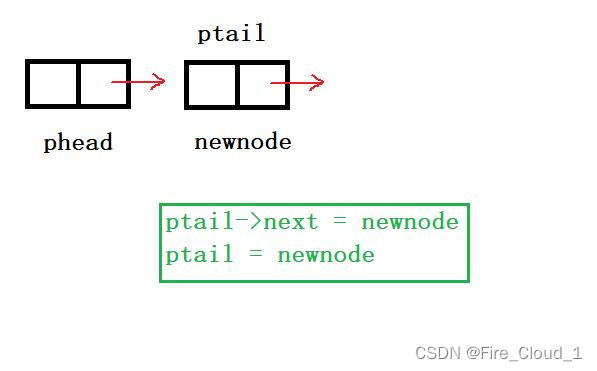
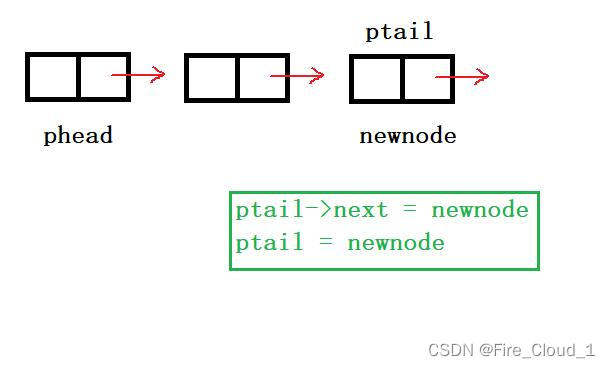

- 可以看到,这通过ptail的移动,newnode被不断插入到链表的后面,但是phead却没有变化,始终守护在头结点的身边👼,
最后当你想要观看整个链表的结构时,去获取这个头结点即可,因为后面的结点都是链接在头结点之后的,所以头结点不可以变化,一旦变化了那么整个链表的结构就乱了😂,最后这是个函数,返回值类型是LSTNode*,因此返回phead,主函数中去接收一下即可 - 也就是这个SList,因为当这个函数结束之后,所建立的栈帧也就跟着销毁了,此时的phead就不复存在,但我们将其return返回了,那这个时候SList就保存了这个头结点,之后便可以根据这个头结点去访问链表中的所有元素
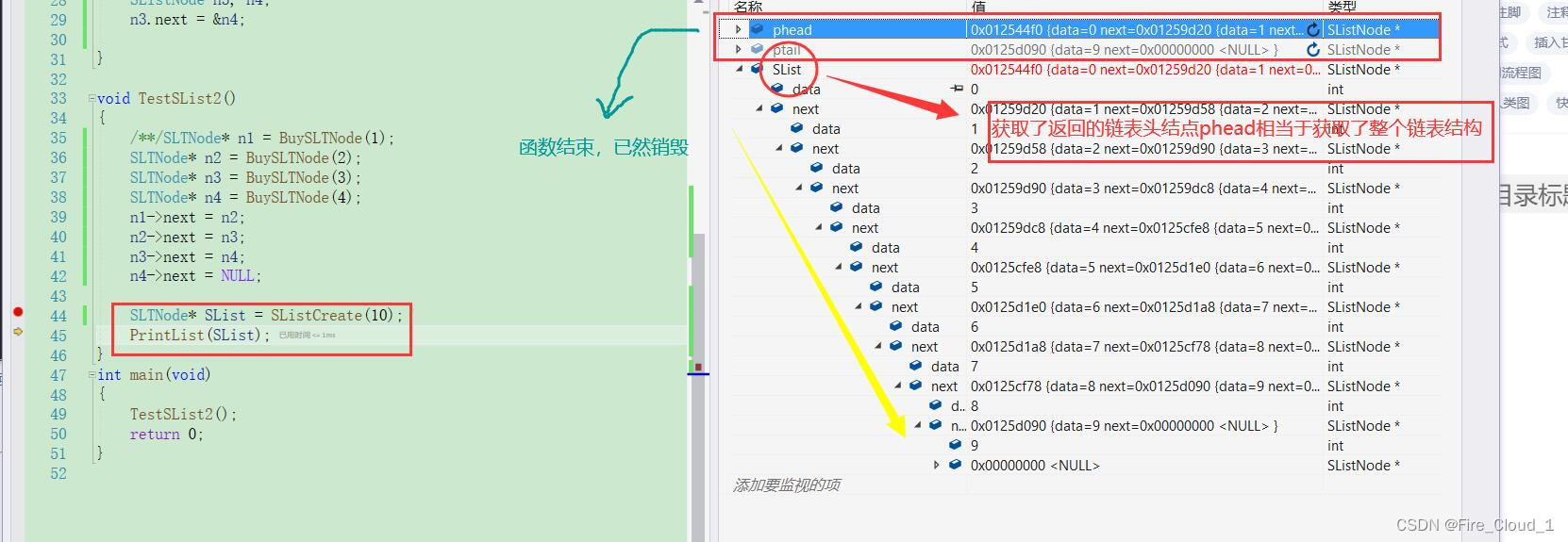
SLTNode\* SList = SListCreate(10);
- 我们去DeBug中看一下,从SList的数据结果来看,它确实获取了整个链表的所有内容😍
打印链表【生活小案例2——王思聪不需要省钱】
- 通过画图和文字说明,懂得了链表存储的逻辑以及使用头结点去访问整个链表,但我们还是看不见摸不着,接下去就进行一个可视化,将这个链表打印出来看看
- 我们一样是本着这个不轻易改变头结点的原则,定义一个结点指针去存放获取这个头结点,将phead的值给到一个cur的指针变量,然后的话就是我们熟悉的遍历操作,上代码⌨️
void PrintList(SLTNode\* phead)
{
SLTNode\* cur = phead; //尽量不用头指针,定义变量存放
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
- 那有同学还是搞不懂既然这个phead和cur都是相同的,那直接使用phead去遍历不就好了,
再定义一个结构体指针又需要消耗内存空间 - 这里我就要和你普及一下有关内存空间的大小的知识了,对于操作系统来说,这个内存空间是很富裕的,在计算机内存中
1M = 10W(byte),1G = 10亿(byte),对于一个cur结构体指针的大小,也就是8个B的大小,对于系统来说完全就是芝麻粒小的东西,所以有没有这个cur完全没有影响。 - 其实这么小一个cur对于操作系统来说和亿万富万看待几千块钱是一个道理,那比如我们经常在媒体娱乐中看到的王思聪,它爸爸就是万达集团的老总王健林,有一天王思聪和王健林说我这个月给您省了5千块钱,但是他爸爸却满不在乎,因为这些前对他来说就是零花钱一般,省了和没省也没什么区别。
- 那从这里就可以反映出对于编程时有些需要使用到的变量定义我们尽量还是不要省,可以起到它独特的作用,比如说帮助理解程序,再者就是像我们这里的保护头结点不被轻易改变
此时美丽的链表就被形象地打印了出来📷

- 但是为了更加形象地让大家看出链表的物理存储结构,所以我这样做👍
printf("[%d|%p]->", cur->data,cur->next);

函数调用栈帧图【✏庖丁解牛,细致剖析】
- 我们可以看到,当在Test函数中调用这个Create函数创建链表时,便对应地开辟出了相应的函数栈帧,
对于Test函数和SListCreate函数都有它们自己单独的栈帧,栈帧内部就是函数体中定义的各种变量。因此在起初创建newnode的时候,phead和ptail均是指向这个链表的第一个结点,存了第一个结点的【地址】。phead是为了函数结束后返回,ptail则是为了链接 - 对于函数而言,建立一个函数开辟栈帧,随着函数的结束栈帧也就跟着销毁了,这里的phead和ptail也不会存在,这就是我们为什么要在堆中申请空间去存放一个个结点,上面说到过,堆中申请的空间不会像栈中那样,随着函数的结束而被释放,对于malloc动态开辟出来的空间是需要你去手动释放的,也就是
free()
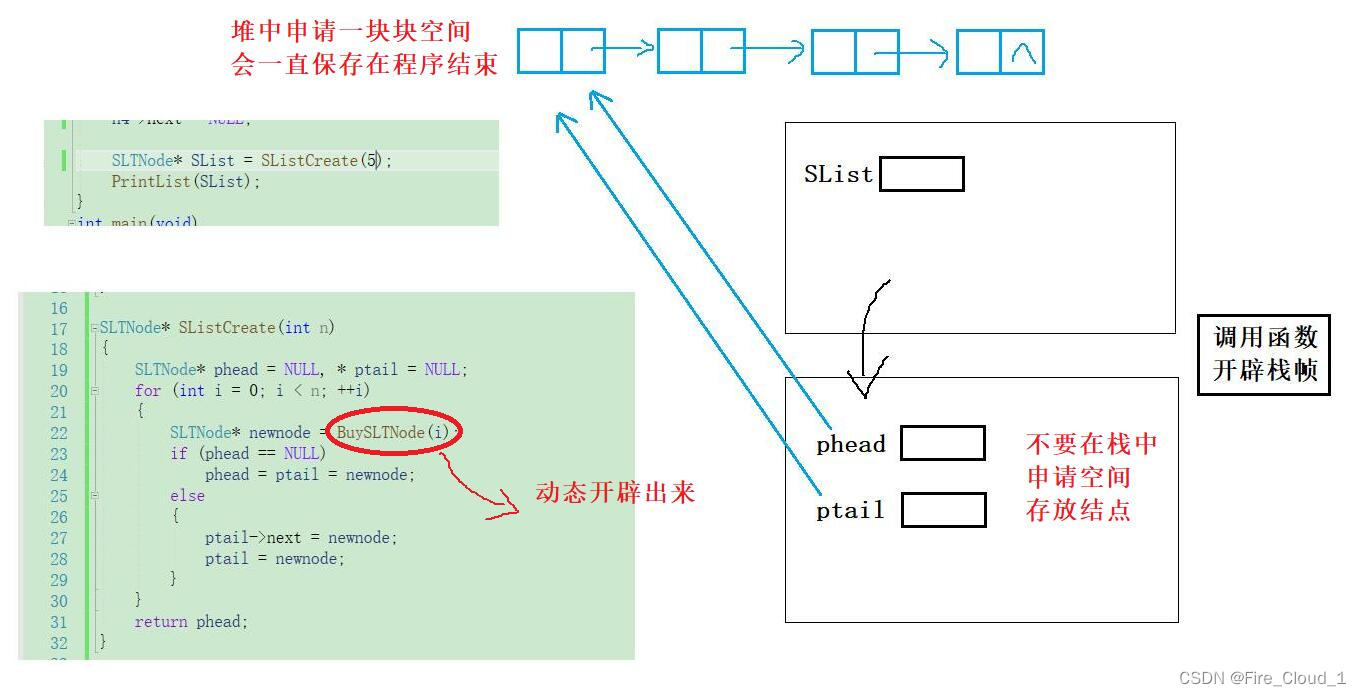
- 随着新结点的插入,尾指针ptail不断进行移动,直至插入最后一个结点之后便结束插入,最后ptail是指向最后一个尾结点,phead是指向头部第一个结点,【保存有整个链表的结构】,最后将这个phead返回由函数外界的SList接收,便将Create函数中的建立的链表的头拷贝给了SList,此时
随着Create函数的结束,所建立的栈帧也将销毁,在函数内部创建的局部变量也跟着一起销毁,不复存在 - 我们在C语言中讲到过有【作用域】这么一个概念,任何变量,都有它的作用域:对于全局变量而言,它的作用域是从声明开始到整个程序结束,但是对于局部变量而言,它的作用域也就是在其所声明的函数内部而已,
出了作用域就销毁了,但好在我们保存并返回了这个指向链表头的指针,这个指针中又保存着第一个结点的地址,此时SList便可以通过这个地址去访问这个链表
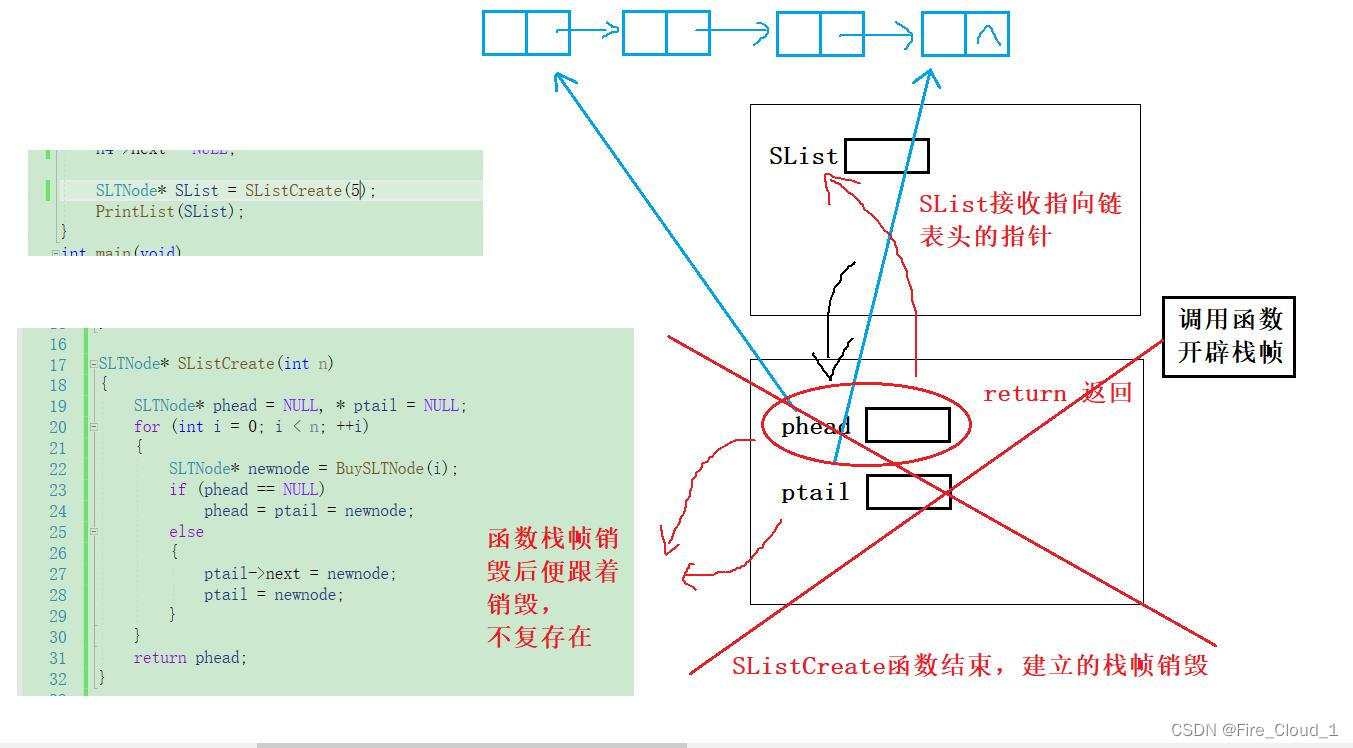
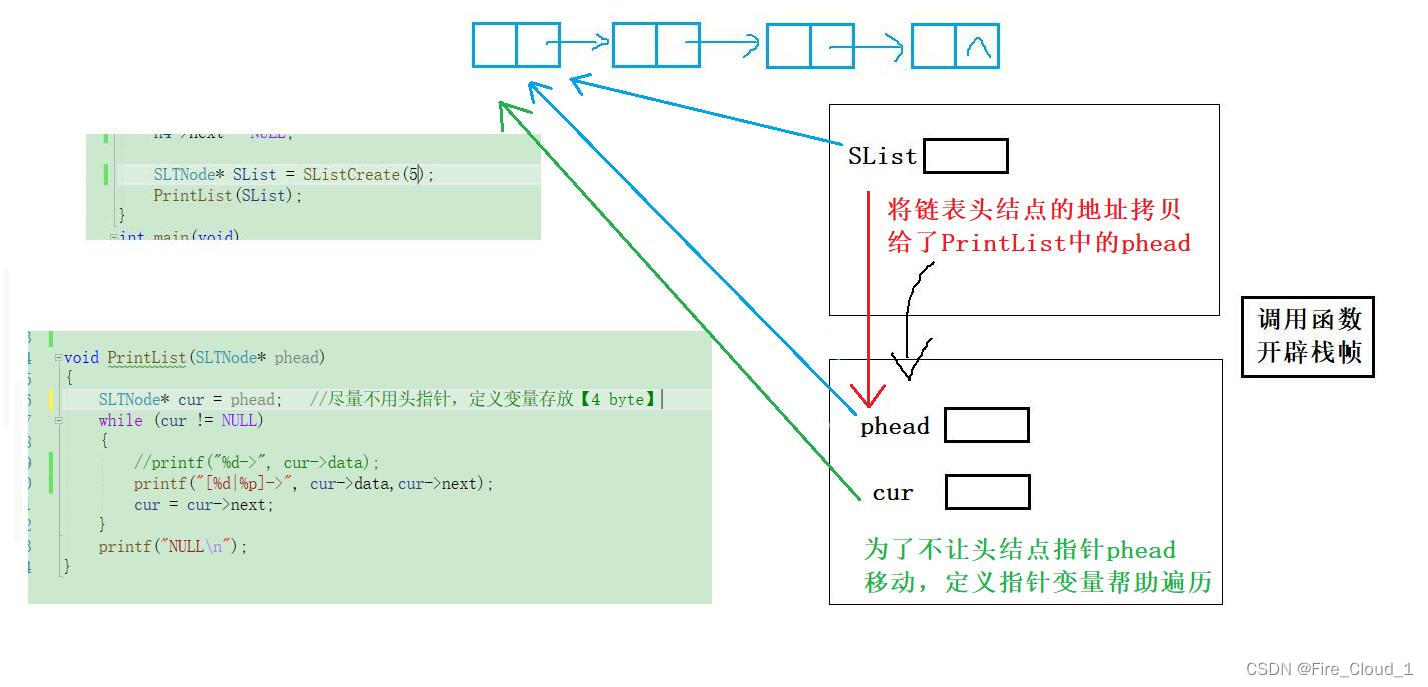
- 当这个SList获取了链表头结点的地址后,便将其传入PrintList中,但是呢PrintList里是不可以使用外界的这个指针变量的,所以在函数形参部分,就定义了一个指针变量去接收,继而就将这个链表头结点指针所保存的地址拷贝给了这个phead的,这里的phead和Create中的phead又是不同的两个东西,不要混淆。此时两个独立的函数栈帧中的指针变量就都指向堆区中的同一块内存地址
- 上面说到过,为了不让这个头结点指针发生变动,就继续定义了一个指针变量去进行一个变量,从而打印出了这个链表的样子
三、接口算法实现【是时候表演真正的技术了🆒】
认真看完了上面两个模块,相信你对链表的整体框架和结构已经有了一个基本的认识,现在我们要真正地去实现一些有关链表操作的接口,以便观察链表这种数据结构在处理数据的时候与顺序表有何不同❓
1、尾插【Hard】
- 首先第一个我们就来看看尾插,这个在顺序表中有讲到过,就是在尾部插入一个数据结点,对于顺序表来说很简单,就是在size的位置放入这个元素接口,然后size++,但是对于链表来说,也会很容易吗?我们一起来看看
经典错误案例分析
void SListPushBack(SLTNode\* phead, SLTDataType x)
{
SLTNode\* newnode = BuySLTNode(x);
SLTNode\* ptail = phead;
// while(tail != NULL)
while (ptail) //一般写成这样
{
ptail = ptail->next;
}
ptail = newnode; //只是存放在局部变量中
}
- 首先我给出一种很多同学常见的思路和写法,也就是定义一个ptail指针从头结点开始慢慢遍历到最后为空的时候,然后把动态开辟出来的结点放到这个ptail中,这是很常见的一种错误,原理也是和我们上面讲到过的函数栈帧的建立和销毁一个道理,这里的ptail只是一个SListPushBack所在的栈帧中的一个局部变量而已,你让它指向堆区新开辟出来的一块空间,在函数内部看起来是链接上了,但是当这个函数结束时,所建立的栈帧便销毁了,此时局部变量出了它的作用域也会跟着销毁,所以这个尾部新插的结点newnode根本就没有链接上
- 对于尾插来说,它的本质其实是让最后一个结点链接新结点,也就是让这个next去存放这块堆区中申请的地址,这就是我们上面所说的物理结构中结点与结点之间的关系
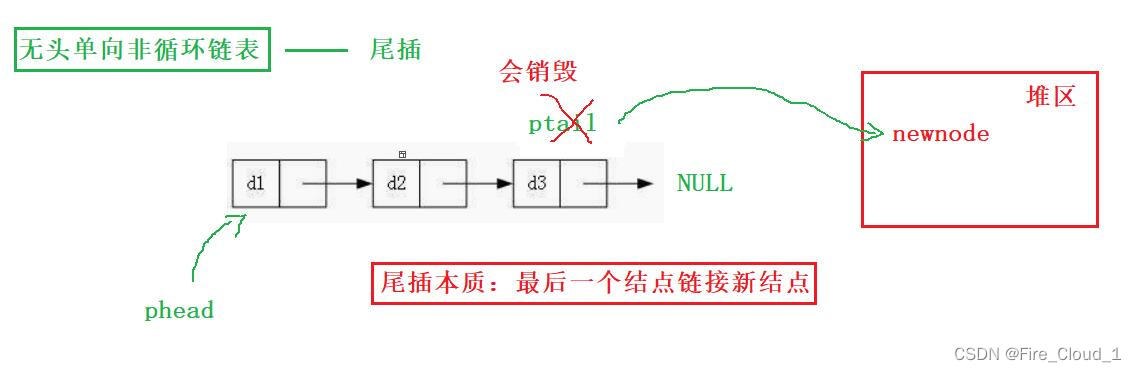
- 所以应该要像下面这么写,去判断ptail的next域是否为空,若为空则表示遍历到了最后一个结点,此时应该使用【 ptail->next = newnode】,让ptail的next域指向这个新的结点才对
void SListPushBack(SLTNode\* phead, SLTDataType x)
{
SLTNode\* newnode = BuySLTNode(x);
SLTNode\* ptail = phead;
while (ptail->next)
{
ptail = ptail->next;
}
ptail->next = newnode;
}
- 当然还有一种特殊情况就是这个单链表为空,那就要进行一个单独的判断,然后让phead指向这个新插入的结点newnode即可

void SListPushBack(SLTNode\* phead, SLTDataType x)
{
SLTNode\* newnode = BuySLTNode(x);
if (phead == NULL)
{
phead = newnode; //形参的改变不会影响实参
}
else
{
SLTNode\* ptail = phead;
while (ptail->next)
{
ptail = ptail->next;
}
ptail->next = newnode;
}
}
- 写了这么一大堆,这回肯定是天衣无缝了,我们去测试一下吧
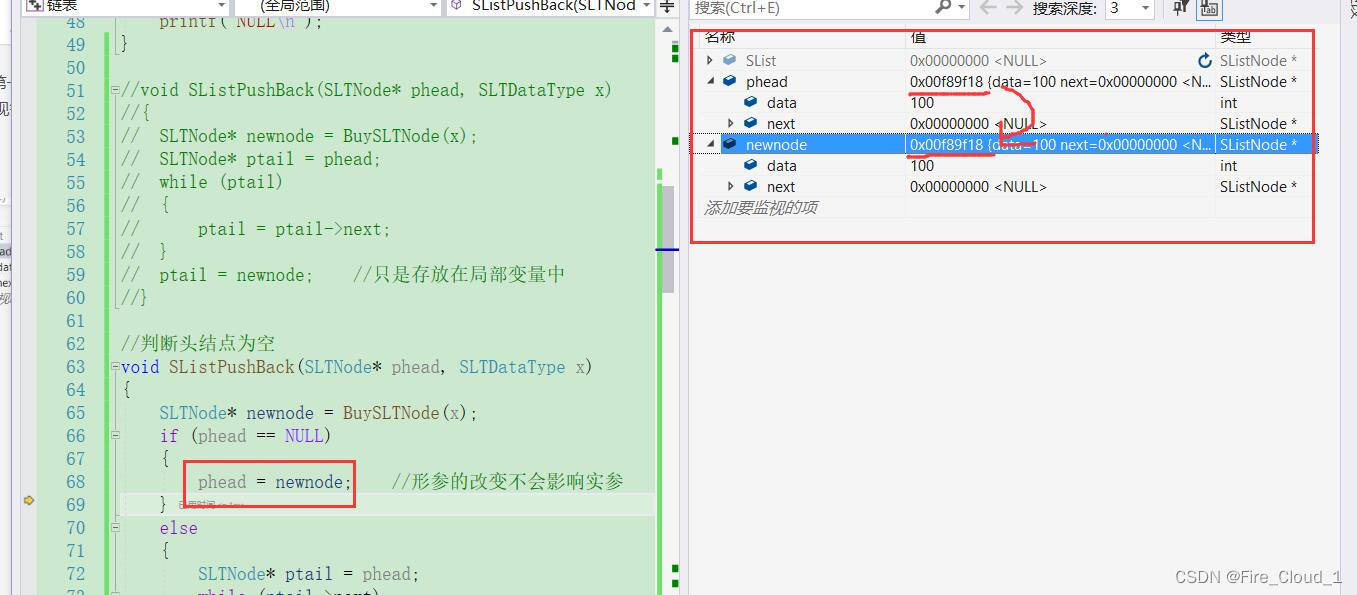
- 哦哦,好像不太对诶😳,插入了三个数据,但是完全没有插进去的样子,这是为什么?我们来DeBug看一下
- 可以看到在DeBug中,我们需要让这个单链表形成的样子应该是第一次尾插的时候将其作为首结点,先进去第一个if判断,然后在后面两次时都进入下面的else判断,但是当我在调试的时候,
发现每一次进入的都是第一个if,也就意味着这个SList一直就是为空的,但是进入函数内部却可以发现其实这个phead是指向了newnode所在的内存地址的,但是在外面看的时候,这个SList却始终都是空的,这是为什么呢? - 这就要说到C语言中的函数传参问题了,我们知道,形参的改变是不会影响实参的,对于这个phead,就是SListPushBack中的形参,只是接收外界实参SList传入的头指针,也就是说phead所指向的地址并不代表SList也指向这块地址,这和我们上面Create的时候不同,Create在创建出这个链表时会返回指向其头部的head指针,外界可以接收到,但是在这里的尾插只是一个操作罢了,
函数的返回值是void,因此外界根本无法从返回值来获取和指向这个首部的指针- 若是你对函数传参还不太理解,可以看看我的这篇文章 ——> C生万物 | 函数的讲解与剖析
- 那有同学说,这该怎么办呐,好不容易写出来了😢。我们继续看下去

二级指针真正改变头结点的指向【⭐⭐⭐⭐⭐】
本模块对于二级指针不太熟悉的同学先去看看二级指针有关的文章,我推荐这篇深入理解二级指针
- 这个时候我们应该联想到C语言中有关指针方面很经典的一道例题,就是交换两个变量的值,我们来回顾一下这个代码
void Swap1(int\* p1, int\* p2)
{
int tmp = \*p1;
\*p1 = \*p2;
\*p2 = tmp;
}
int a = 2, b = 5;
printf("a = %d, b = %d\n", a, b);
Swap1(&a, &b);
printf("a = %d, b = %d\n", a, b);

- 可以看到,两个变量的值得到了交换,也就是很经典的通过
指针接收地址去交换两个变量的值,我们先通过这个小案例带大家DeBug一下 - 可以看到,对于Swap1函数,我们传入了变量a和变量b的地址,然后在形参中,使用到两个指针变量去接收这两个地址,在函数体中,我们又可以通过【*p1和 *p2】解引的操作获取变量a和变量b的内容,引入第三方变量暂时存放一下,就可以实现一个交换了
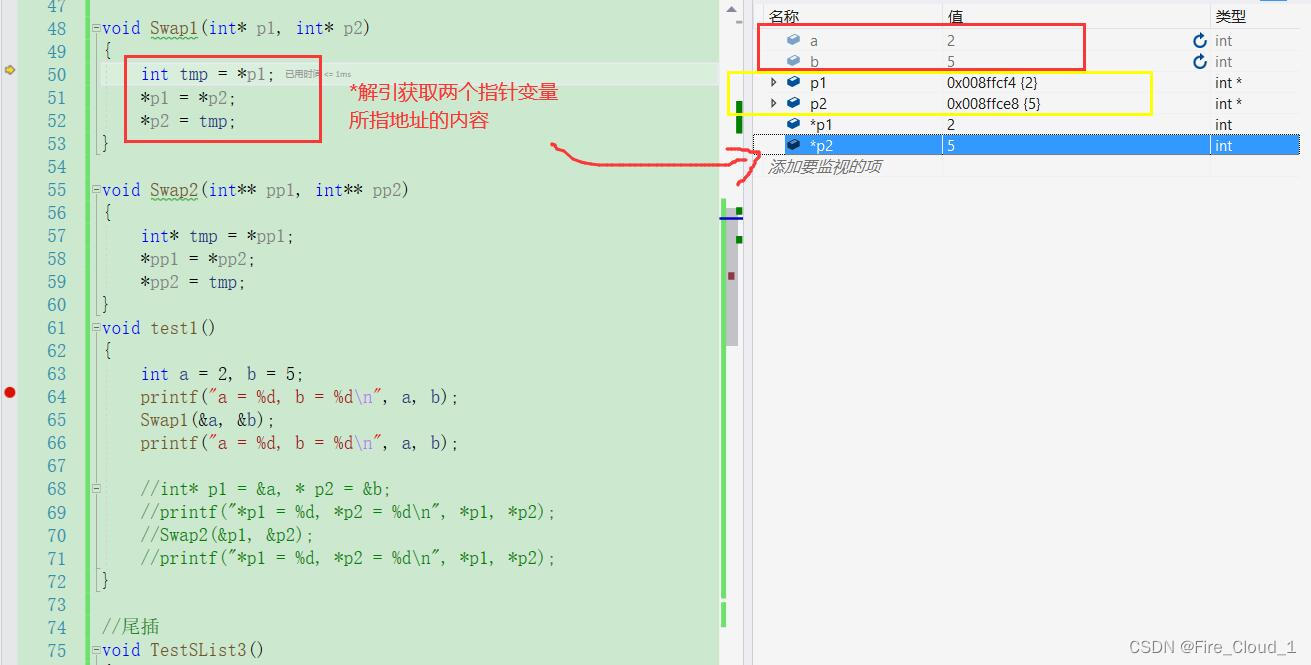
- 然后在Swap函数执行完后,【*p1】和【*p2】的值进行了一个交换

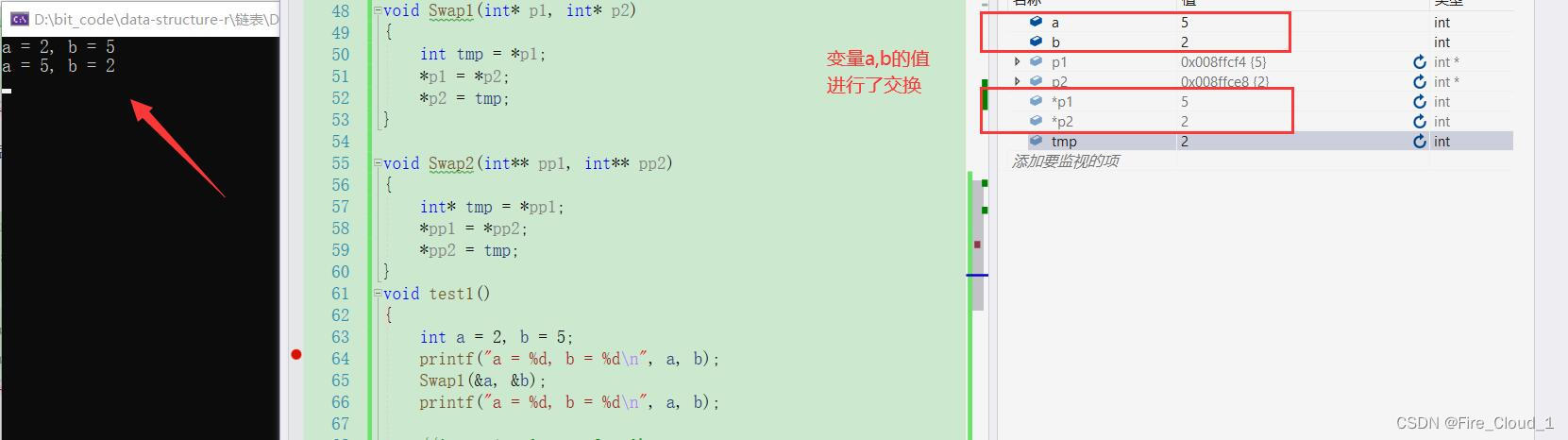
- 当这个Swap函数结束的时候,因为我们传入的是两个变量的地址,所以
指针的解引直接是访问这两块地址的内容,因而就发生了一个交换
若是对上述这个传址的修改不了解,也可以看看我在函数章节中介绍的那个经典案例,讲得很细致清楚
- 好,有了这么一个引入,接下去我们将二级指针的传参时就好理解一些了
- 对于【
int】型的变量,我们要交换改变它们的值需要对【int*】去传入地址,拓展一下 - 对于【
int*】型的变量,我们要交换改变它们的值需要对【int**】去传入地址,传入什么地址呢,传入的就是【int*】的地址 - 这里的【int**】就是我们在C语言中学过的二级指针,接下去还是交换值,通过二级指针来看看如何进行传参交换
void Swap2(int\*\* pp1, int\*\* pp2)
{
int\* tmp = \*pp1;
\*pp1 = \*pp2;
\*pp2 = tmp;
}
void test1()
{
int a = 2, b = 5;
int\* p1 = &a, \* p2 = &b;
printf("\*p1 = %d, \*p2 = %d\n", \*p1, \*p2);
Swap2(&p1, &p2);
printf("\*p1 = %d, \*p2 = %d\n", \*p1, \*p2);
}
- 可以看到,对于这里的变量a我首先通过一个指针变量p1去存放它的地址,对于变量b则是用p2存放,然后在Swap2中,传入这两个【一级指针变量】的地址,给到【二级指针变量】形参分别去接收它们的地址,我们继续通过DeBug来看一下
- 可以看到,pp1这个二级指针存放的是一级指针p1的地址;pp2同理存放p2的地址,
- *pp1解引用将二级指针降为一级指针,使得 【
*pp1 = p1】【*pp2 = p2】,此时他们的指向都是相同的,存放的都是变量a和变量b的内存地址 - 拿一个【int*】类型的一级指针变量tmp去接收*pp1也就是一级指针p1,此时
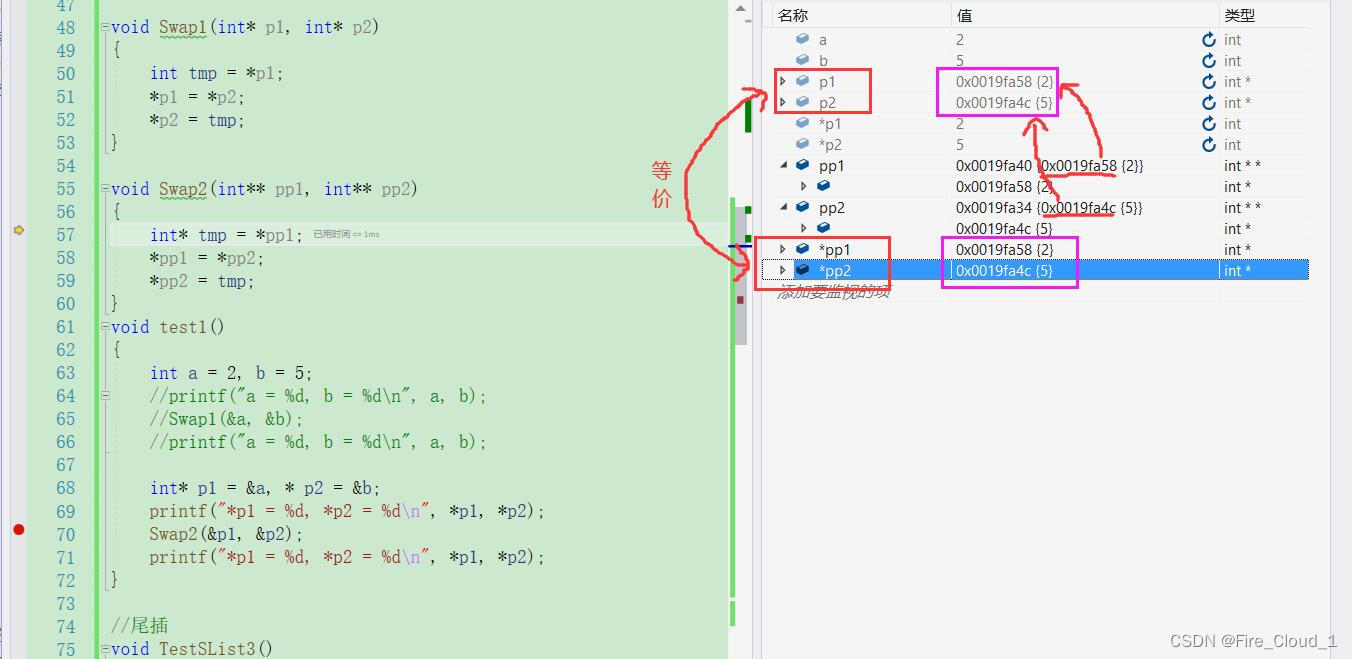
- 可以看到,让Swap2函数结束时,*pp1和 *pp2这两个一级指针的指向便发生了改变,然后通过解引用又改变了指向地址中所粗放的内容

- 结束函数回到test1()可以看到pp1和pp2这两个二级指针都变灰了,这其实就是VS中所展现的
函数调用结束内部变量随着栈帧的销毁而被释放,但是因为我传入的p1与p2的这两个一级指针的地址,所以函数内部就相当于获取到了这两个指针所指向的地址,实现了一个同一操作,因此函数内部的改变便带动了外界的p1和p2指向的改变,由下图便可看出 - 然后从运行结果可以看到*p1和 *p2也就是 a 与 b值进行了一个交换,这就实现了一个通过二级指针传参来交换改变变量内容的操作
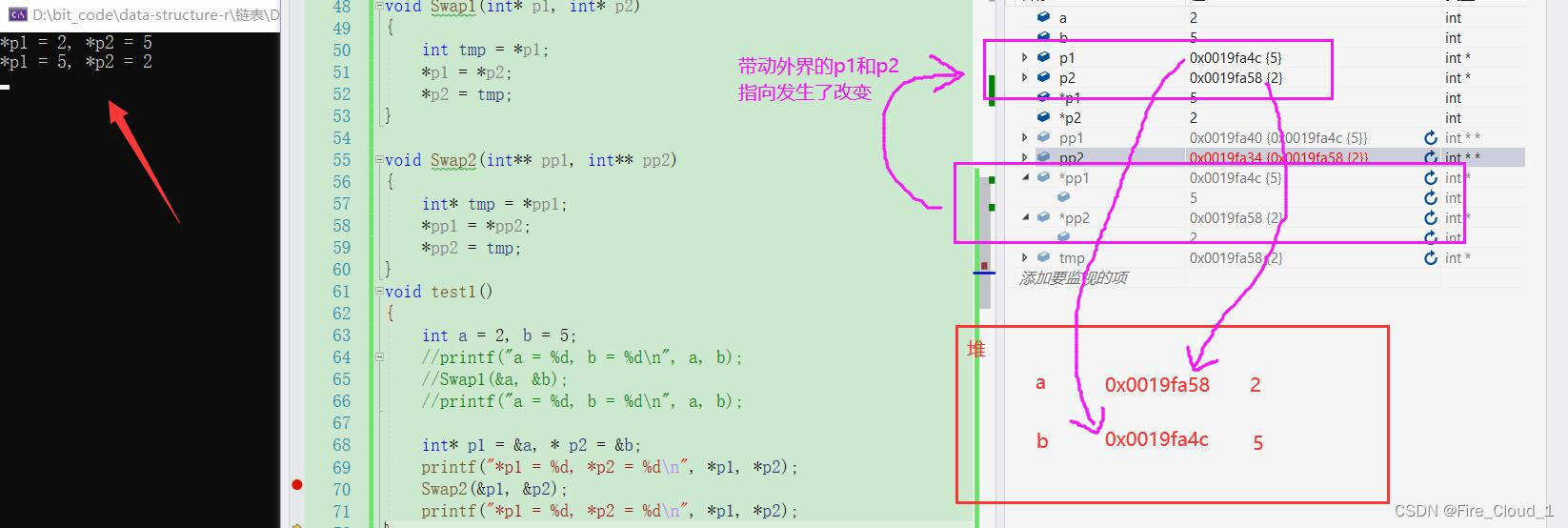
但是我将这个二级指针有什么用呢?难道只是给你普及一下二级指针的知识吗,那当然不是,实际上就是为了通过这个二级指针接收以及结构体指针SList去真正地通过内部的修改改变外部的头结点指针,我们通过代码来看一下
//传二级指针
void SListPushBack(SLTNode\*\* pphead, SLTDataType x)
{
SLTNode\* newnode = BuySLTNode(x);
if (\*pphead == NULL)
{
\*pphead = newnode;
//通过二级指针的解引用改变头结点【从NULL->newnode】
}
else
{
SLTNode\* pptail = \*pphead;
while (pptail->next)
{
pptail = pptail->next;
//无需再使用二级指针,无需改变头结点,只需要做一个链接
//改变结构体的指向,使用结构体指针
}
pptail->next = newnode;
}
}
SLTNode\* SList = NULL;
SListPushBack(&SList, 100);
SListPushBack(&SList, 200);
SListPushBack(&SList, 300);
PrintList(SList);
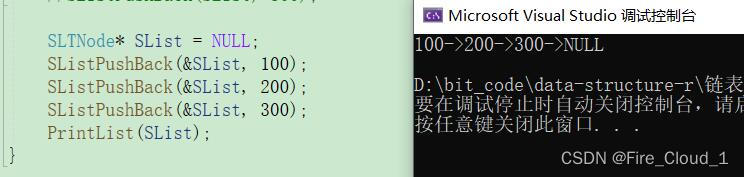
再来解释一下传参和链接的过程
- 可以看到函数中的形参我使用的是一个二级指针,然后在test中,我将这个指向头结点的一级指针SList的地址传了进去,当第一次尾插这个100的时候,便会进入第一个if分支,*pphead便是解引用之后的一级指针,就相当于这个SList,因此当你将新开辟的结点newnode插入时,便直接将【*pphead】指向了这块堆区中的地址。然后在第二次插入200的时候,便会进入第二个else分支,使用一个
一级指针类型的指针变量pptail去接收【 *pphead】,不断往后遍历,然后将两个结点通过【存放地址】的关系链接起来,就完成了我们的尾插操作 - 有同学可能对下面这段else逻辑比较疑惑,为什么在修改头结点的时候要用到二级指针,但是在后面的链接中不需要用到了呢❓,这个时候就要去思考,因为在后驱的结点链接时只是做一个将当前结点的next存放下一个结点在堆区中开辟的地址,这个操作我们前面的一级指针也可以完成,因此无需使用到二级指针。但是在外界传参的时候我们还是选择用
二级指针接收一级指针的地址,以此使得函数内部和外部的指针都可以指向堆区中的同一块空间。而且对于函数的结构已经声明了是无法改变的,不能因为第一次需要改变头结点传入二级指针,但是在后面要无需用到二级指针就突然将这个pphead变为一级指针,这违背了编程的严谨性
接下去一样再通过函数栈帧的形式来讲解一下,加深印象,帮助理解
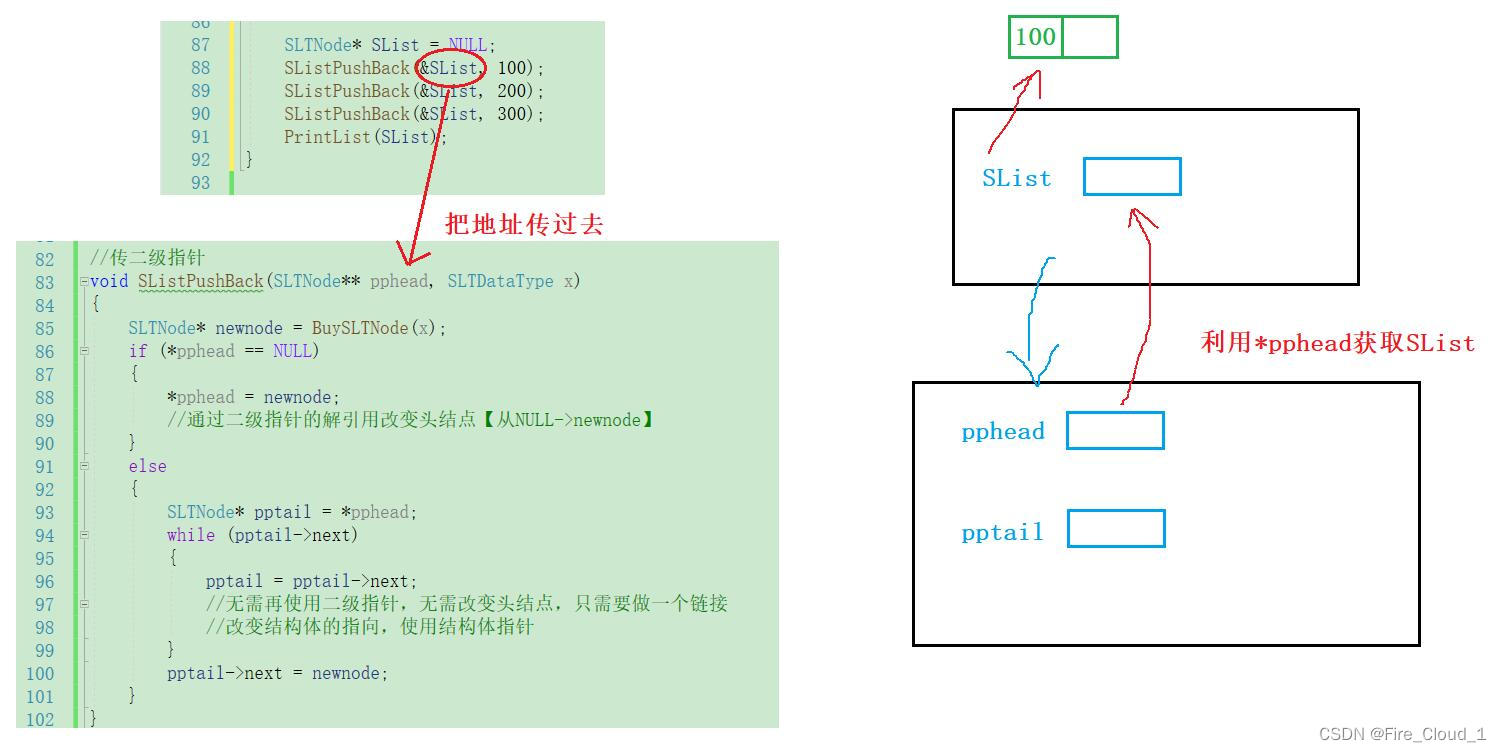
- 可以看到,这里将SList拷贝给了pphead,然后pphead指向这个值为100的结点了,但是呢SList并没有,这里的具体操作就是将SList这个一级指针的地址给到了二级指针pphead
- pphead中存地是SList的地址,这里的【*pphead】解引用之后就是这个SList本身,然后主函数看到【SList = NULL】,所以在判断【*pphead】的时候就相当于在判断【SList】,这才会进入if分支,通过让【
*pphead = newnode】也让这个SList指向了100这个数据结点
- 然后随着PushBack函数的结束,函数所建立的栈帧也就被销毁,pphead和pptail就都没了,但此时这个SList却通过二级指针传参指向了尾插进去的第一个结点,此时这个SList的头部结构才真正地被改变了,可以继续尾插后面的结点
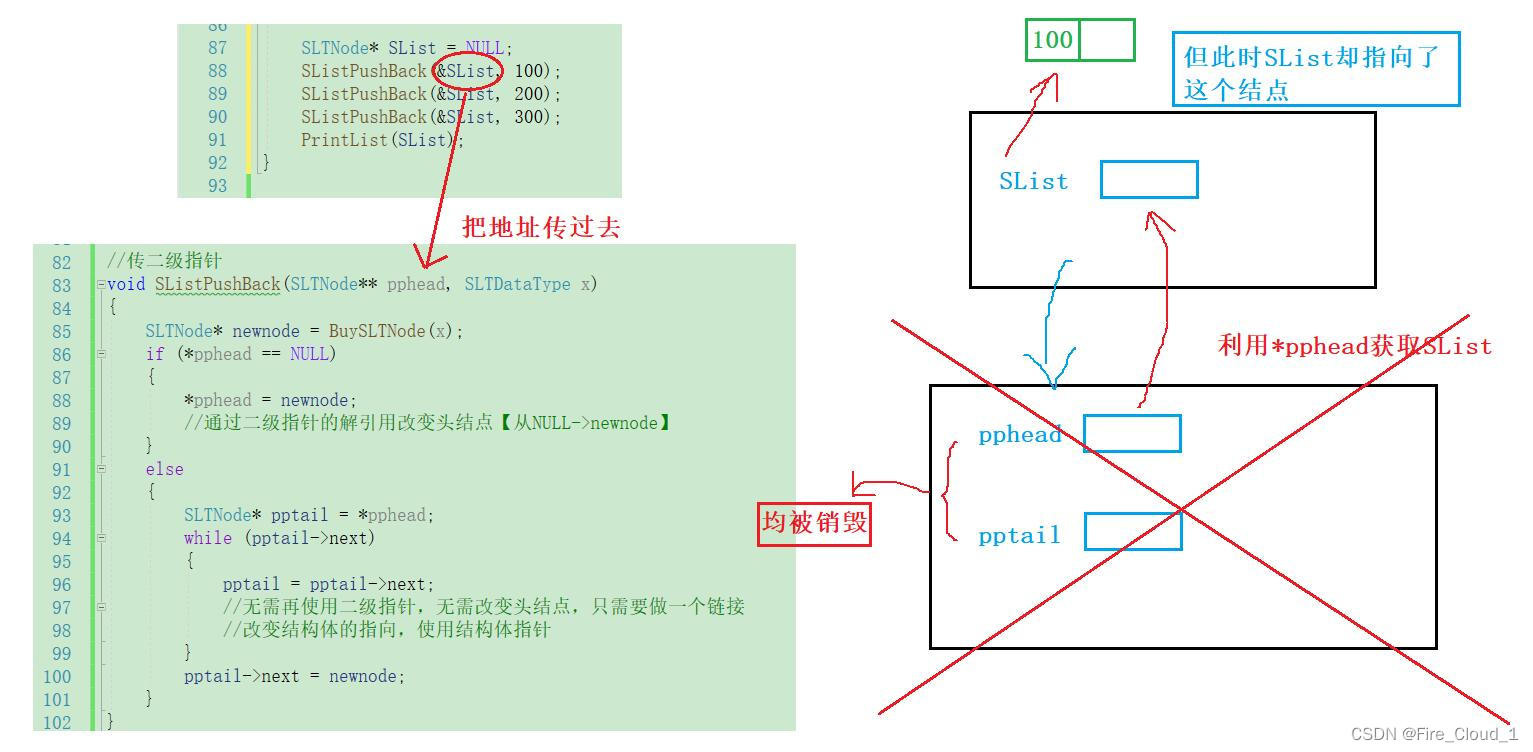
对于尾插法,你学【废】会了吗😝
2、尾删【Circuitous】
有尾插,那一定也有尾删,我们一起来探究一下🔍
经典错误案例分析
- 对于尾删我们一样从一个经典的错误案例开始说起
void SListPopBack(SLTNode\* phead)
{
SLTNode\* ptail = phead;
while (ptail->next)
{
ptail = ptail->next;
}
free(ptail);
tail = NULL;
}
- 对于tail,当其遍历到最后一个结点,也就是next 为空的时候,跳出循环,然后free释放掉这个结点,然后又进行了一步操作将这个tail的值置为空,这个意思就是想着说删除了一个结点后尾结点继续置为空
- 有不少同学一开始都是这样去是实现的,但这么去写是会出现问题的,通过图示看一下
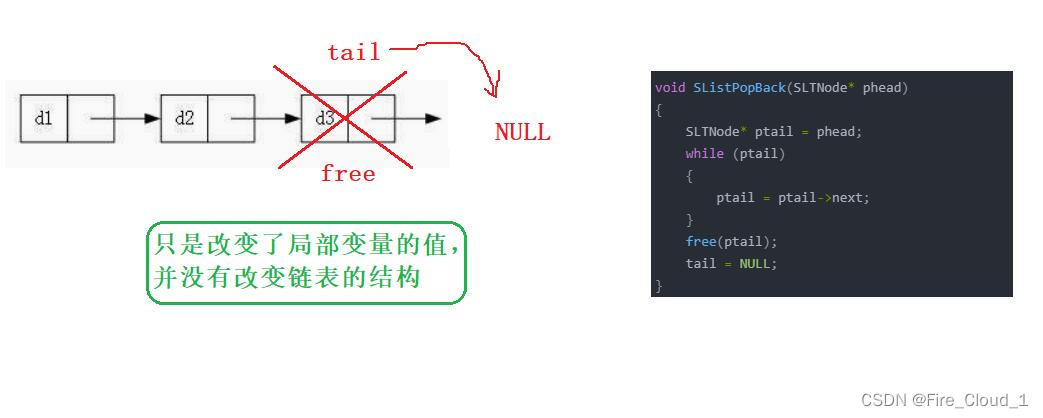
- 通过DeBug我们可以看到,当PopBack函数中将这个ptail置为NULL的时候,确实其内存地址就变成了【0x00000000】,但是这也只是修改了这个局部变量ptail的值,与链表当前一个结点的next域其实没有任何关系,可以看到phead最后一个结点300的next域还是一个地址值,并没有被置空,这其实就相当于一个野指针一般,到后面万一不小心去修改这个next值,就会造成很大的问题,有关野指针的问题,后面我会详细叙述
- 此时只是这个局部变量做了一个修改,并没有改变这个结构体,要改变结构体就要使用到结构体指针
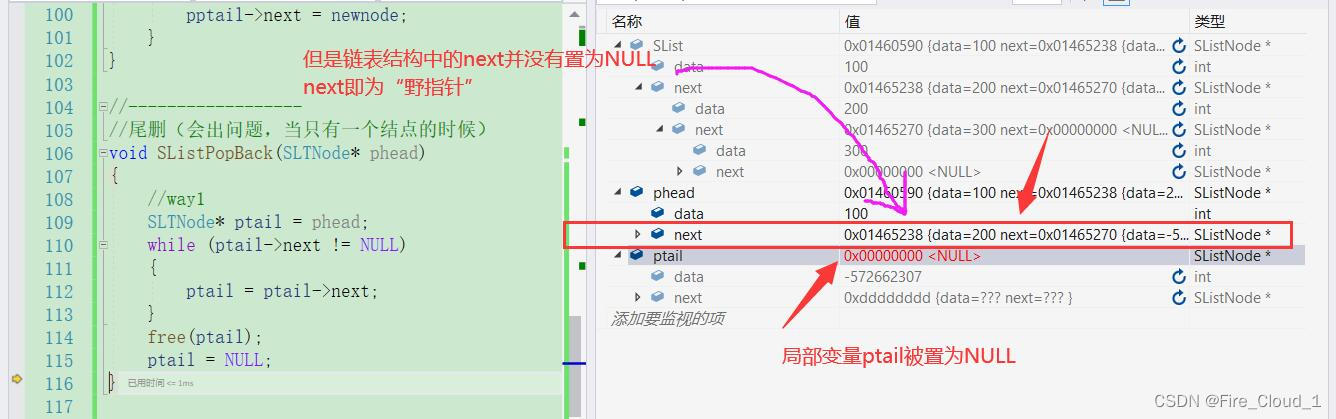
修改方式一:保存ptail的上一个结点
- 首先来看第一种修改方式,也就是将这个ptail向后遍历的时候先做一个保存,放到一个结构体指针prev中,在向后遍历的时候若ptail遍历到最后一个结点,直接free释放ptail即可,然后让prev->next = NULL,这个时候结构体就发生了改变,这个next指针域也发生了真正的改变,不会像上面一样变成一个野指针充满【❗dangerous❗】
//way1
SLTNode\* ptail = phead;
SLTNode\* prev = NULL;
while (ptail->next != NULL)
{
prev = ptail;
ptail = ptail->next;
}
free(ptail);
prev->next = NULL;
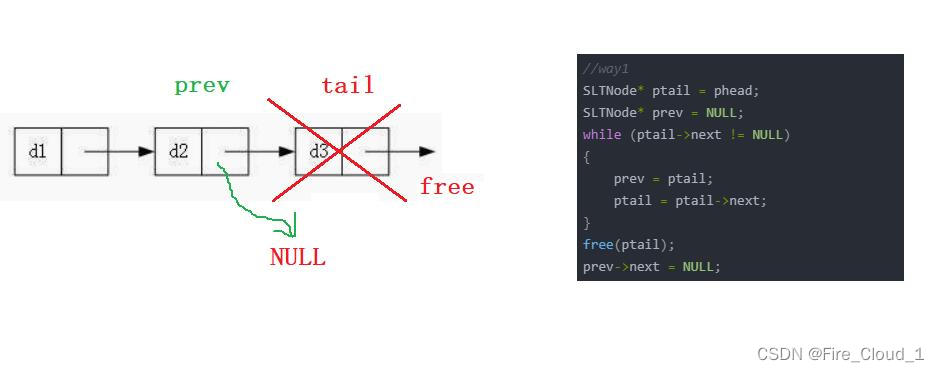
修改方式二:ptail->next->next
- 然后说说第二种修改方式,也就是不需要去再定义一个prev指针去保存,而是直接判断【ptail->next->next】是否为空即可,此时这里的ptail便为尾结点的前一个结点,因此free(ptail->next)就是删除尾结点,最后将这个结点置为空
//way2
SLTNode\* ptail = phead;
while (ptail->next->next != NULL)
{
ptail = ptail->next;
}
free(ptail->next);
ptail->next = NULL;
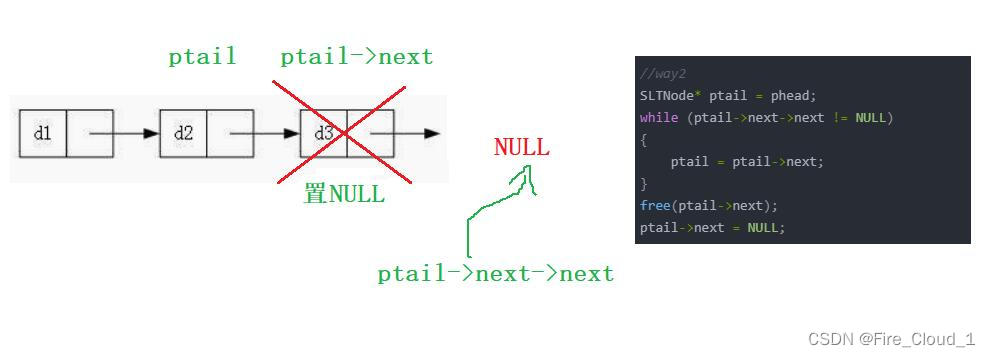
特殊情况修正【单个结点、二级指针修改、断言报错】
- 你以为用这样就可以真正地实现尾删了吗,那还远远不够,路还有很远🐎,继续分析下去吧
- 可以看到,在这里我执行了三次PopBack,然后到最后一次的时候,发现ptail->next==NULL,但是ptail->next->next却是一个越界的位置,这个时候其实就不对了,之前我们有说过,访问越界是一个很大的问题🈲

- 所以,对于单个结点的尾删,我们应该进行一个单独的判断。也就是当前传入进来然后接收的这个phead所指向的next是否为空。若为空,则表示此单链表只有一个结点,直接free这个phead即可,然后将其置为NULL
void SListPopBack(SLTNode\* phead)
{
if (phead->next == NULL)
{ //只有一个结点
free(phead);
phead = NULL;
}
else
{
SLTNode\* ptail = phead;
while (ptail->next->next != NULL)
{
ptail = ptail->next;
}
free(ptail->next);
ptail->next = NULL;
}
}
- 那有同学说,这个时候应该没问题了吧,单个结点的情况都被我考虑到了,简直天衣无缝😏
- 但是。。。Exception它又来了
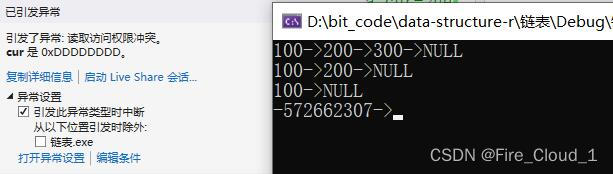
- 不说了,没有爱了❤️直接DeBug吧⌨️
- 那这里是又可以看到,我们在写尾插的时候出现过的情况,就是函数内部做了改变但是外界并不知晓,那这个时候该怎么办呢?没错,就是它,👉
二级指针👈
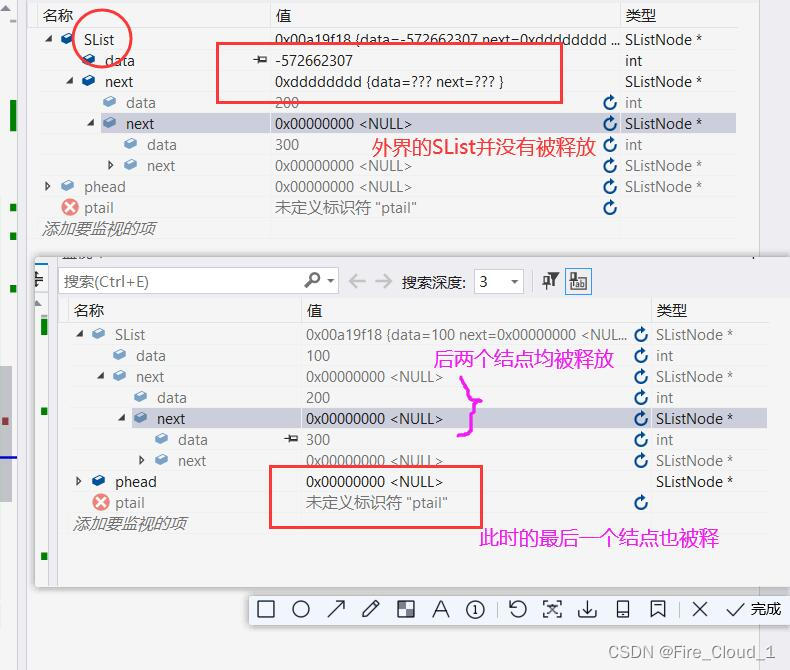
- 那这下可好了,整个函数的结构又要重新定义,这其实是正常的,调Bug💻就是不断在试错的过程,当你找出错来了,那就应该及时更正,不要怕麻烦
- 一样,就像下面这么改,对于只有单个结点需要单独处理时使用*pphead去获取一级指针进行操作~
void SListPopBack(SLTNode\*\* phead)
{
if ((\*phead)->next == NULL)
{ //若只有一个结点,直接将其释放,传入二级指针便改变了链表的头结点
free(\*phead);
\*phead = NULL;
}
else
{
SLTNode\* ptail = \*phead;
while (ptail->next->next != NULL)
{
ptail = ptail->next;
}
free(ptail->next);
ptail->next = NULL;
}
}
- 然后我们再来看一下运行结果,可以看到,链表终于被清干净了💧
在这里插入图片描述
- 真的是天衣无缝、百无一失了吗?我再删一次你看看😱

- 可以看到,此时的链表已经为空,但是我又执行了一次PopBack操作,那有同学说,那你这不是手欠吗,人家都被删空了你还要再删一次,成心跟人过不去是吧😠
- 记住一点,你永远要考虑要一些随性操作的用户,指不定那天进行了一些你开发时想都想不到的操作😈
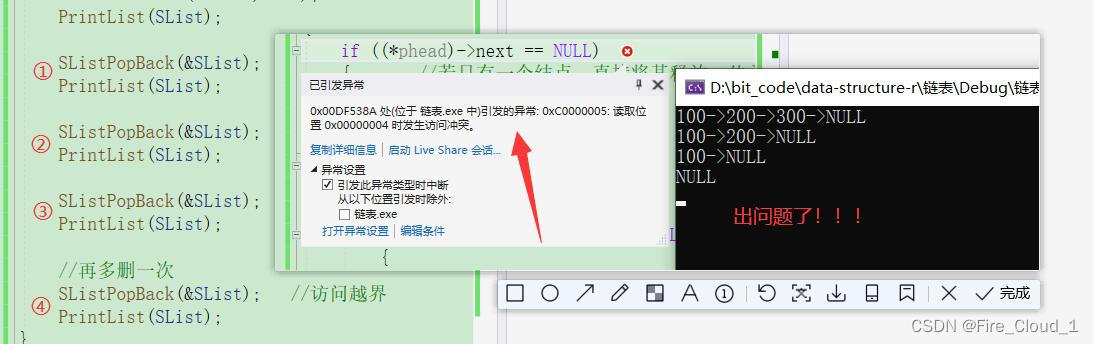
- 这其实就是什么问题?没错,就是访问越界的问题,当你将链表已经删空的时候,再去对链表进行一个删除,此时访问的就是一个随机的位置,超出了你所能访问的界限,编译器也就很好地为你【检查出了错误】
- 那此时我们应该怎么办呢?没错,就是在PopBack函数进来的一开始,就进行一个判断,看看这个指针所指向的头是否为空,若是为空,则执行相应的报错
- 在这里我们选择直接使用暴力的方式,也就是断言【assert】,不要温柔的if判断,直接报出来哪里有问题,然后打一顿再说💪
void SListPopBack(SLTNode\*\* phead)
{
assert(\*phead);
if ((\*phead)->next == NULL)
{ //若只有一个结点,直接将其释放,传入二级指针便改变了链表的头结点
free(\*phead);
\*phead = NULL;
}
else
{
SLTNode\* ptail = \*phead;
while (ptail->next->next != NULL)
{
ptail = ptail->next;
}
free(ptail->next);
ptail->next = NULL;
}
}
以上就是尾删法的最终版本,你又学【废】了吗😝
说完尾插和尾删,还有头插和头删,但是不要惊慌,对于头插和头删,没有你想象得那么复杂😵
3、头插【Easy】
- 对于头插其实并不复杂,也就是创建出一个新的结点newnode,然后让这个结点的next域存放首个结点的地址,还是一样,对于头插和头删,都是要使用到二级指针的,否则内部的改动是无法带动外部的变化
- 要将这个二级指针化为一级指针我们说过很多遍,
一次*解引用即可。链接上后将这个新的头所存在的地址给到指向头结点的指针即可
void SListPushFront(SLTNode\*\* pphead, SLTDataType x)
{
SLTNode\* newnode = BuySLTNode(x);
newnode->next = (\*pphead); //二级指针解引,变为一级指针
\*pphead = newnode; //再让newnode变为新的头
}
- 怎么样,简单吧,很快就说完了,一方面是因为我们前面铺垫得很多,你所掌握的东西我已经不需要说了,另一方面在对于单链表而言,它的头插和头删确实比尾插和尾删来得高效
4、头删【Easy】
- 说完头插,马上趁热打铁来说说头删
- 还是一样,并不复杂。因为删除这个头,那当其删除之后,它的后一个结点也就成为了新的头,这个时候就需要做一个更新,但这个前提是你能访问到后面这个结点,所以我们要事先去保存当前头结点的后一个结点,然后将头结点free释放,最后更新让头结点指针重新指向下一个新的结点即可
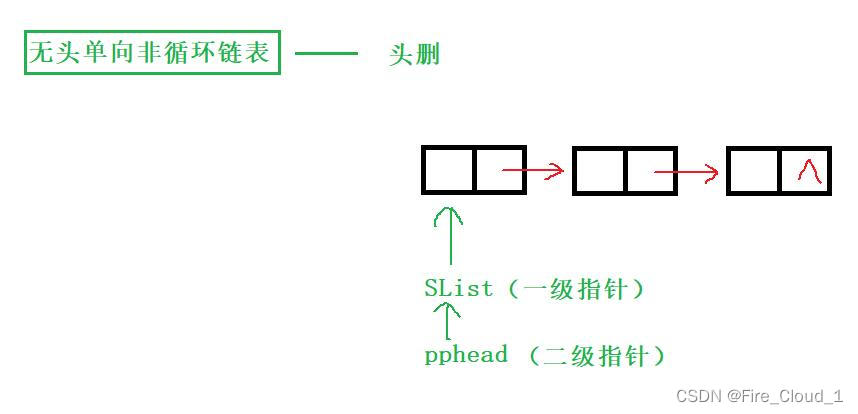
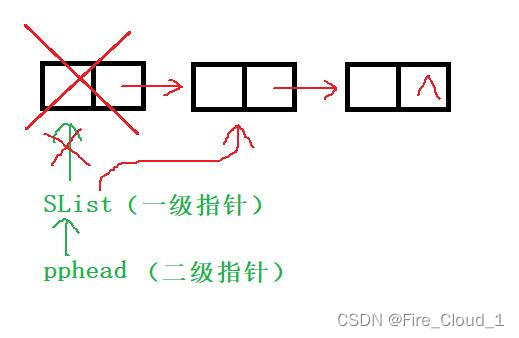
void SListPopFront(SLTNode\*\* pphead)
{
assert(\*pphead); //删除都先断言一下,看看传进来的链表是否为空
SLTNode\* nextNode = (\*pphead)->next; //先保存当前首结点的下一个结点
free(\*pphead);
(\*pphead) = nextNode;
}
5、查找
- 看完了
尾插、尾删、头插、头删。接下来我们要学习的是去链表中查找指定元素,先来看看接口定义
SLTNode\* SListFind(SLTNode\* phead, SLTDataType x);
- 可以看到,形参接收的是头结点指针,以及需要查找的值,返回值类型是一个结构体指针,也就是说返回的是一个指向待查结点的结构体指针,并不是一个下标,一个位置,那函数内部我们该如何去写呢?
- 很简单,只需要一个cur指针先获取头结点的指向,然后一个个向后查询即可,若是发现其指向的data值相同,便返回当前的cur指针
SLTNode\* cur = phead;
//while (cur != NULL)
while (cur)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
//返回的是指向这个待查结点的指针,并不是位置
- 我们来测试一下看看
SLTNode\* SList = NULL;
SListPushBack(&SList, 1);
SListPushBack(&SList, 2);
SListPushBack(&SList, 3);
SListPushBack(&SList, 4);
SListPushBack(&SList, 5);
PrintList(SList);
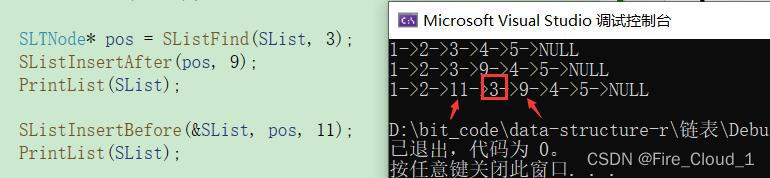
SLTNode\* pos = SListFind(SList, 3);
if (pos != NULL) {
printf("找到了\n");
printf("pos = %d\n", pos->data);
}
else {
printf("没找到\n");
}
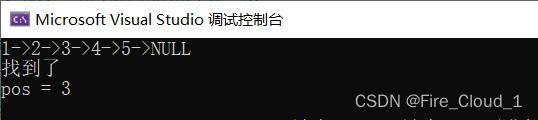
- 可以看到,确实是可以找到,我将这个结点的data值打印了出来
那有同学问,找到返回了这个值又能怎样呢,可以拿来做什么?那我告诉你这个用处可大了,后面我们将在找到的这个pos所指的结点之前、之后进行插入和删除相应的结点,都是要以这个Find接口作为前提
6、在pos位置之后插入结点
- 接下来我们就来看一看如何在找到的pos位置之后插入一个结点呢
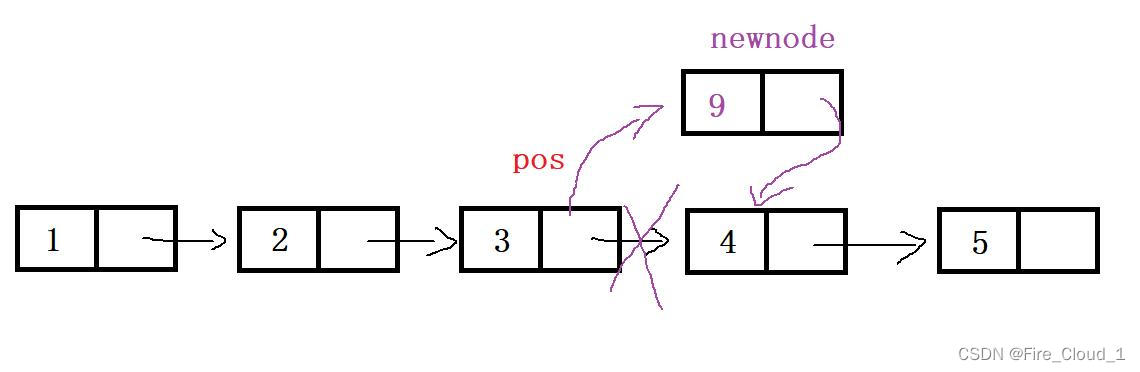
- 可以看到,我们最后要达到的是这种效果,就是pos的next要指向这个newnode,然后newnode的next要指向pos->next,这时候有些同学就会这么去写。先让这个pos的next指向newnode,然后再让newnode的next指向pos的next
- 这个逻辑其实就有问题,当
pos的next所指位置变化之后也就找不到4这个结点了,执行完第一条语句后pos的next就变成了newnode,这个时候再让newnode指向pos的next,也就是让newnode指向它自己,这也就不对了
//pos的下一个位置就没了,相当于是newnode自己指向自己
pos->next = newnode;
newnode->next = pos->next;
- 所以应该把这两条语句做一个交换。先让newode的next指向pos的next,也就是4,然后再让pos指向这个newnode,这个时候结点之间的链接就没问题了😯
newnode->next = pos->next;
pos->next = newnode;
- 通过这段代码,我们插入一个值试试看。从打印结果看来,确实在3后面插入了一个9

警惕传入空指针【✒细致讲解断言assert】
- 还是一样,继续思考有没有可能出现特殊情况,我们来看看这种
- 可以看到,链表中的结点值只有1~5但是却需要找一个88,很明显是找不到的,此时便会return NULL,那么外界的pos接受到的值就是一个空值,也就说这是一个空指针,所以当你传一个空指针进去,你让函数内部怎么实现一个插入呢
SLTNode\* pos = SListFind(SList, 88);
SListInsertAfter(pos, 9);
PrintList(SList);
- 此时可以看到,程序发生了奔溃/(ㄒoㄒ)/~~

- 看到这个地方,我相信你的第一反应就是在函数一开始的加一个断言,判断这个pos是否为空
- 可能有些同学不了解里面的传参机制以及判断机制,我这里讲一下
- 对于assert断言来说,就是还函数还没有执行的时候去做的一件事,所以要
放到一段程序的开头,而不是应该把它放在函数体的中间或者结尾,这点首先要明确; - 其次assert断言的内部参数你需要传入的是你需要检查的
传入进来的某个参数变量,一般是去判断是否为空或者是否小于0。所以对于参数,你应该写入的是会报出错误的对立面,举个例子,当你想要检查a是否大于0,a小于0就会报错,因此应该写assert(a > 0)。若是去判断一个指针是否为空,就要这样写:assert(p != NULL),或者直接简写成assert( p ),就像我们的while循环去判空是一个道理; - 知道了传参逻辑,最后说说
assert的判断机制,就是当你所写的表达式不成立时,也就是当【p == NULL】时,就会出现警告,报出错误。在计算机中【0是假,非0才是真】,当【p = NULL】时,这个表达式就变为了假,非0一般指1,就是p != NULL,表明传进来的指针p不为空,那也就是不会满足条件 - 我们通过CPlusPlus来看看,明确说到当表达式的值为0的时候,就会向标准的错误设备写入一条消息终止调用,也就是断言assert后面的语句均不会执行

- 所以应该在InsertAfter函数的开头加上这一句话
//0是假,非0才是真
assert(pos != NULL); //若不为空,则不会执行;若为空,则报出警告
//assert(pos);
- 此时可以看到,加上这句话后断言就出现了,直接给你报出了
哪个源文件的哪一行出了问题,也就是我们刚才写断言的地方,这个时候你立马可以进行【精确定位】然后排错,这个时候也就提高了程序的可维护性,所以作为我们程序员来说,学会使用断言是很重要的,但是断言并不是什么地方都可以随便加的,根据需求来加,也就是【因地制宜】,不然会出现麻烦,结尾总结的时候会说到📖

【生活小案例3——请人吃饭要带钱💴】
- 通过传入空指针去插入一个结点可以看到是一个很荒谬的事情,我们联想一个生活中的小案例来理解一下,顺便轻松一刻🎸
- 你传入一个空指针和一个待插入的结点值,其实就相当于你带你说今天请你朋友去外面吃饭,但是吃饭之后一看
钱包是空的,于是这个时候就只能让你朋友付钱了【假设不支持手机支付】,那你说这个事情是不是很荒谬,assert断言其实就是在出门之前检查一下你有没有带钱,如果没有带那就会报出警告提醒你要带钱出门 - 所以在函数进行传递指针的时候一定要检查传递的是不是空指针,就想出门检查自己有没有带钱是一个道理
7、在pos位置之前插入结点
- 说完了在这个pos位置之后插入结点,那有后一定有前,现在我们来谈一谈如何在获取到的pos位置前插入一个结点。对于这个,说在前面,会出现两种情况:
- 一种是当前找到的pos在链表中间的某个地方,
- 还有一种比较特殊,就是这个pos刚好是头结点,这个时候进行的其实就是我们上面说过的
头插法,那既然是头插法,就需要去改变这个链表的头,所以又需要使用到二级指针
void SListInsertBefore(SLTNode\*\* pphead, SLTNode\* pos, SLTDataType x)
{
if (\*pphead == pos) {
//若pos位置就为原先的头结点,则使用头插法进行插入
SListPushFront(pphead,x);
}
else {
SLTNode\* cur = \*pphead;
while (cur->next != pos)
{
cur = cur->next;
}
SLTNode\* newnode = BuySLTNode(x);
//此处无需考虑前后错乱问题,直接链接即可
cur->next = newnode;
newnode->next = pos;
}
}
- 直接给出代码做讲解。一样的老套路,通过*pphead进行解引用,
获取到外界SList这个头结点指针,然后去进行一个判断即可,若这个 *phead和pos相同,那表明所Find找到的pos就为链表的头结点。直接调用一下我们上面写过的头插法即可,实现了功能的复用,具体图示如下👇

- 然后再来说一下普通情况,也就是在链表其中的某一个位置前插入,所以我们
要获取pos指针所指向的前一个位置,开头说到过,虽然单链表对于插入和删除很方便,但是访问结点并不方便,需要从头结点开始访问,于是还是一样的套路,定义一个cur指针首先获取到头结点指针的值,也就是把二级指针pphead解引用一下,然后一直去遍历即可,直到这个【cur->next = pos】为止停下来,表示当前cur所指向的结点所在的下一个位置便是pos,此时就可以做一个链接了,具体图示如下👇 - 可以看到,此时无需像在后面插入结点一般去考虑这个先后的顺序关系,只需要将【cur】【newnode】【pos】这三个指针做一个链接即可
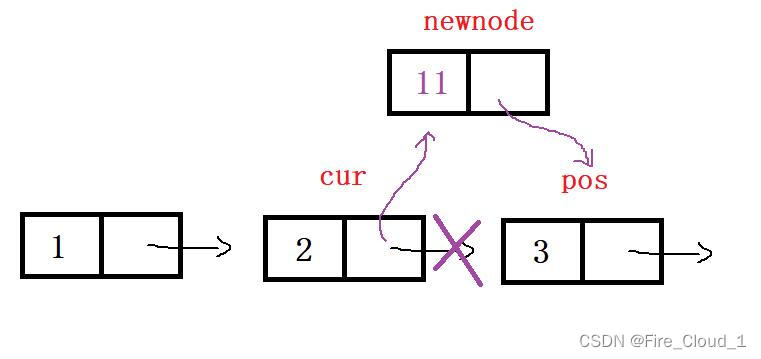
- 最后我们来通过测试验证一下结果
- 这是普通情况
- 来看特殊情况
在这里插入图片描述
看完了如何插入结点,接下去我们来说说如何在查找到的pos位置前后删除结点
8、删除pos位置之后的结点
- 首先来说一说如何删除pos位置之后的结点
- 首先来看一下函数体声明,很明显,只需要传入一个pos指针即可,其余不需要
void SListEraseAfter(SLTNode\* pos)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
}
}
* 直接给出代码做讲解。一样的老套路,通过\*pphead进行解引用,`获取到外界SList这个头结点指针`,然后去进行一个判断即可,若这个 \*phead和pos相同,那表明所**Find找到的pos就为链表的头结点**。直接调用一下我们上面写过的头插法即可,实现了功能的复用,具体图示如下👇

* 然后再来说一下**普通情况**,也就是在链表其中的某一个位置前插入,所以我们`要获取pos指针所指向的前一个位置`,开头说到过,虽然单链表对于插入和删除很方便,但是访问结点并不方便,需要从头结点开始访问,于是还是一样的套路,定义一个cur指针首先获取到头结点指针的值,也就是把二级指针pphead解引用一下,然后一直去遍历即可,直到这个【`cur->next = pos`】为止停下来,表示当前cur所指向的结点所在的下一个位置便是pos,此时就可以做一个链接了,具体图示如下👇
* 可以看到,此时无需像在后面插入结点一般去考虑这个先后的顺序关系,只需要将【cur】【newnode】【pos】这三个指针做一个链接即可

* 最后我们来通过测试验证一下结果
* 这是普通情况

* 来看特殊情况
### 在这里插入图片描述
看完了如何插入结点,接下去我们来说说如何在查找到的pos位置前后删除结点
### 8、删除pos位置之后的结点
* 首先来说一说如何删除pos位置之后的结点
* 首先来看一下函数体声明,很明显,只需要传入一个pos指针即可,其余不需要
void SListEraseAfter(SLTNode* pos)
[外链图片转存中...(img-kS6c48ML-1715464292375)]
[外链图片转存中...(img-PyRM5Swz-1715464292376)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









