







终端 代码以下载jdk1.8 压缩文件。完成后解压。
1.File->New->Project->Maven Project->Next 勾选 create->com.huweiMRWordCount
2.Window->Preferences->Java->Compiler->level 1.8->Apply and close
Window->Preferences->Java->|nstalledJREs->Add->standard VM->Next->配置->Finish->勾选新增 jdk->Apply3.
4…初始页面 JRE System Library【J2SE-1.5】->Build Path->configure->Add Library->JRE System Library->Next ->workspace->finish
5.Remove【J2SE-1.5】->Apply and close配置 pom 文件 ctrl+s
6.MRWordCount 的/src/main/java 新建 package,在 com.huawei.mapreduce 包下新建 MRWordCount的Java class,编写业务代码,ctrl+s
19行:string[]splited=line.split(“”);//请在此处编写代码,将 1ir
FLinkne110orld[root@node-master1Em
22行:Text k2=new Text(word);//请在此处编写代码
23行:LongWritable v2=new LongWritable(1);//请在此处编写代码
33行:long count= 0L;//请在此处编写代码,为count 完成初始化
37行:LongWritablev3=new LongWritable(count);//请在此处编写代码49 行:job.setMapperClass(MyMapper.class);//请在此处编写代码,填入括号内55 行:iob.setReducerClass(MyReducer.class);//请在此处编写代码,填入括号内7.MRWordCount->RUN AS->Maven install
16行:JavaRDDtextFile=jsc.textFile(args[0]);//请考生完成该友步骤代码编写,注意路径需以 args[819行:JavaRDDwords=textFile.flatMap(line->Arrays.asList(line.split("“)).iterator());25行:JavaPairRDD<String,Long>result= wordsAndOne.reduceByKey((v1,v2)->v1+v2 );
28行:result.saveAsTextFile(args[1])
Scp ~/eclipse-workspace/MRWordcount/target/MRWordcount-1.0-SNAPSHoT.jar root@xxx.xxx.xxx.xxx:/root8.输入密码运行并登录ssh root@xxx.xxx.xxx.xxx 输入密码
1s
可选:cd~/eclipse-workspace/MRWordCount/target/
9.vim words.txt i进入编辑模式 tab分隔 esc退出 :wg 回车保存退出
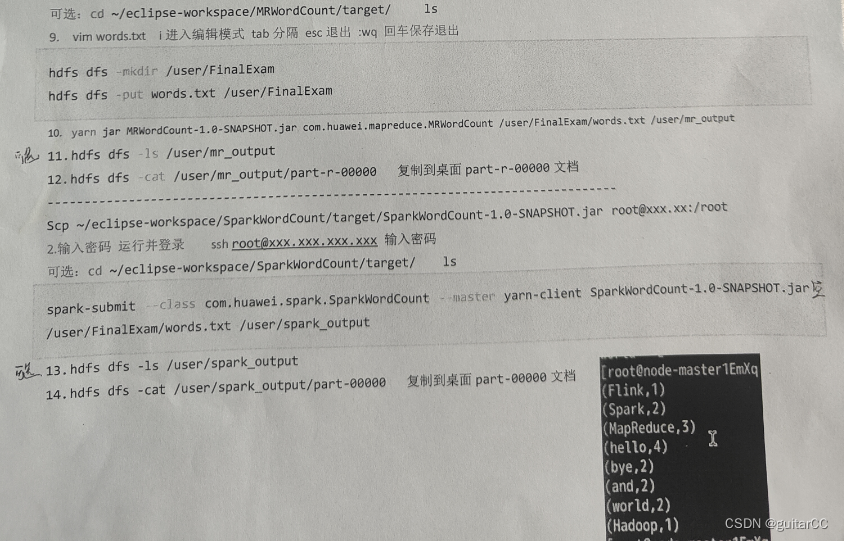
hdfs dfs -mkdir /user/FinalExam
hdfs dfs -put words.txt /user/FinalExam
10. yarn jar MRWordCount-1.0-SNApsHoT,jar, com.huawei .mapreduce.MRNordcount /user/FinalExam/words.txt /user/mr output11.hdfs dfs ls /user/mr output
12,hdfs dfs-cat /user/mr output/part-r-00000复制到面part-r-00080 文档
---------ニ-------------
---- ------- ---- - ----------,
----------Scp ~/eclipse-workspace/SparkWordcount/target/Sparkwordcount-1.0-SNAPsHoT.jar root@xxx.xx: /root2.输入密码 运行并登录sshroot@xxx.xxx.xxx.xxx 输入密码
可选:cd ~/eclipse-workspace/SparkWordCount/target/ls
spark-submit–class com,huawei,spark,sparkWordcount-master yarn-client SparkNordCount-1.0-SNAPSHoT.jar p/user/FinalExam/words.txt /user/spark output
m13.hdfs dfs -ls /user/spark output14.hdfs dfs -cat /user/spark_output/part-00800复制到面part-00000 文档



spark的链接处理
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/HCCDP/jdk-8u341-linux-x64.tar.gz
tar -zxvf jdk-8u341-linux-x64.tar.gz
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/HCCDP/apache-maven-3.6.0.tar.gz
tar -zxvf apache-maven-3.6.0.tar.gz
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/HCCDP/scala-2.11.8.tgz
tar -zxf scala-2.11.8.tgz
vim ~/.bashrc
export JAVA_HOME=/home/user/jdk1.8.0_341 export JRE_HOME=
J
A
V
A
H
O
M
E
/
j
r
e
e
x
p
o
r
t
C
L
A
S
S
P
A
T
H
=
.
:
{JAVA_HOME}/jre export CLASSPATH=.:
JAVAHOME/jreexportCLASSPATH=.:{JAVA_HOME}/lib:
J
R
E
H
O
M
E
/
l
i
b
e
x
p
o
r
t
S
C
A
L
A
H
O
M
E
=
/
h

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
k6rQ0z-1714323607850)]
[外链图片转存中…(img-wfeKzYfb-1714323607850)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新














 973
973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









