







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
重启
* 查看防⽕墙状态 systemctl status firewalld

2. 在/opt ⽬录下创建 module(程序⽂件夹)、software(安装包) ⽂件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software

### **2****.****在Hadoop106节点安装JDK、Hadoop**
#### **·安装JDK**
1. 将jdk-8u341-linux-x64.tar.gz 利⽤xftp上传到/opt/software
2. 解压jdk到/opt/module⽂件夹
[root@hadoop100 ~]# tar -zxvf /opt/software/jdk-8u341-linux-x64.tar.gz -C /opt/module/
3. nano /etc/profile.d/my\_path.sh ⽂件,输⼊
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_341
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
4. source ⼀下 /etc/profile ⽂件,让新的环境变量 PATH ⽣效
[root@hadoop100 ~]# source /etc/profile
5. 检验⼀下成功不
[root@hadoop100 ~]# java -version
#### **·安装Hadoop**
1. 将hadoop-3.3.3.tar.gz利⽤xftp上传到/opt/software
2. 解压hadoop到/opt/module⽂件夹
[root@hadoop100 ~]# tar -zxvf /opt/software/hadoop-3.3.3.tar.gz -C /opt/module/
3. 在 /etc/profile.d/my\_path.sh ⽂件,加⼊下⾯内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.3.3
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin
export PATH= P A T H : PATH: PATH:HADOOP_HOME/sbin

4. source ⼀下 /etc/profile ⽂件,让新的环境变量 PATH ⽣效
[root@hadoop100 ~]# source /etc/profile

5. 测试
[root@hadoop100 ~]# hadoop version
#### **·新增ens37网卡**
1. 关闭 hadoop106
2. 右击虚拟机选项卡 -> 配置 -> 添加 -> ⽹络适配器 -> 改成桥接
3. 启动 hadoop106
4. nmcli connection add type ethernet con-name ens37 ifname ens37 autoconnect yes
5. nano /etc/sysconfig/network-scripts/ifcfg-ens37
6. 更改 ifcfg-ens37 ⽂件
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens37
UUID=59021522-3de9-492b-9308-b6ab7596aceb
DEVICE=ens37
ONBOOT=yes
IPADDR=10.227.x.1y6
NETMASK=255.255.254.0
注:
x:班级号,7班是2或8班是3
y:组号,1-10
service network start

#### **·Hadoop101配置**
1. 打开 hadoop101完全分布式新增hadoop106节点.md 2023-12-18
2. nano /etc/hosts 加⼊
10.227.x.1y6 hadoop106
注:x:班级号,7班是2或8班是3;y:组号,1-10
3. nano $HADOOP\_HOME/etc/hadoop/workers 加⼊ hadoop106
4. ssh-copy-id -i ~/.ssh/id\_rsa.pub hadoop106
5. rsync -av
$HADOOP\_HOME/etc/hadoop root@hadoop106:/opt/module/hadoop-3.3.3/etc/
6. rsync -av /etc/hosts root@hadoop106:/etc
7. 远程到 hadoop106 ssh hadoop106
8. nano /opt/module/hadoop-3.3.3/etc/hadoop/hadoop-env.sh 修改 JAVA\_HOME export
JAVA\_HOME=/opt/module/jdk1.8.0\_341
### **3****.****启动集群**
1. jpsall.sh 中加⼊ hadoop106 nano ~/bin/jpsall.sh
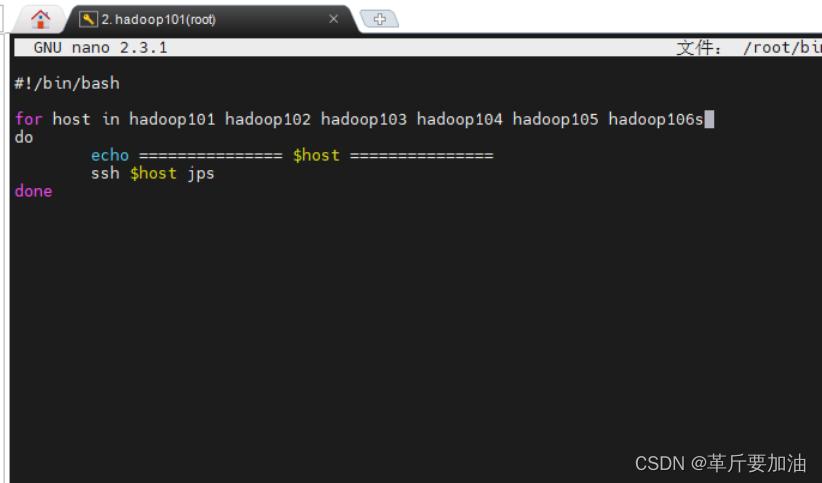
2.shutdown\_all.sh 中加⼊ hadoop106 nano ~/bin/shutdown\_all.sh
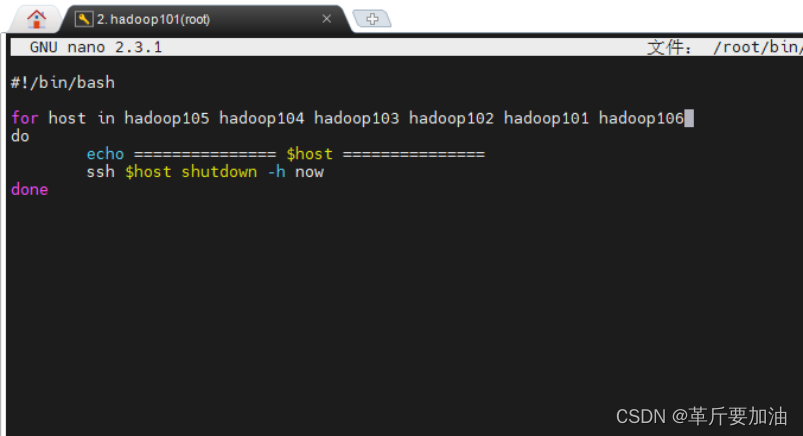
3. 启动集群 myhadoop.sh start
4. 观察各节点进程的启动情况



### **4.个人配置中遇到的问题**
* #### **电脑没有vmnet8虚拟网卡**
编辑--->虚拟网络编辑器--->VMnet8--->还原默认设置--->NAT设置--->更改网关IP--->应用确定
设置 ---> 网络和Internet ---> 更改适配器选项 ---> 查看VMnet8,出现并显示已启用
* #### **Hadoop104、105DataNodeID缺失**
通过查找日志,在记录中找到了对应的节点的DataNode,然后我们进入到了103节点的$HADOOP\_HOME/data/dfs/data/current/VERSION目录下,复制了103节点的VERSION文件,然后分别进入到了104和105节点的$HADOOP\_HOME/data/dfs/data/current下,创建了VERSION文件,将从103中复制的内容粘贴到了新创建的文件中,并根据在日志中查找到的将其对应的DataNodeID,其内容如下(示例):
storageID=DS-5c72e6f4-c180-44b4-9f26-6abc84327f43
clusterID=CID-fd0aa33f-424c-4212-a725-dd33a3ff126c
cTime=0
datanodeUuid=75809195-27bf-4c87-bb4d-8fb81642e7ae
storageType=DATA_NODE
layoutVersion=-57
其中,storageID会由系统自动生成,更改以后重新启动集群,集群数据接收正常
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
其中,storageID会由系统自动生成,更改以后重新启动集群,集群数据接收正常
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-e8CTcEhF-1713129669762)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









