







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

其中’Unnamed: 0’,‘user_geohash’(有缺失)两列数据我们在分析时不涉及,对这两列数据进行删除。
import pandas as pd
final_data.drop([‘Unnamed: 0’,‘user_geohash’],axis=1,inplace=True)
final_data.head()

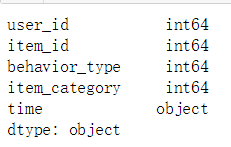
成功进行删除,检查数据类型
data.dtypes
2、一致化处理:
- 可以发现目前time是object型的,因为分析涉及到时间、天、小时,所以,要把数据集里的时间戳列,即time_stamp列转化为日期。。
data[‘date’] = data[‘time’].map(lambda x:x.split(’ ')[0])
data[‘hour’] = data[‘time’].map(lambda x:x.split(’ ')[1])
data[‘date’]=pd.to_datetime(data[‘date’])
data[‘hour’] = data[‘hour’].astype(‘int32’)
data.head()
data.dtypes


可以看到目前date和Hour的类型已经成功转换,符合我们的预期,查看表格中是否有空数据,并查看一下表格的量
data.isnull().sum()
data.shape

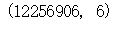
可以看到数据中并没有空数据,数据的规模在1000万左右,分为6列,依次为用户id、商品id、用户行为类型、时间。其中用户行为类型中1代表点击(当做pv),2代表collect(收藏),3代表cart(加入购物车)数据较为完整,不需要继续进行清洗,对数据进行分析
五、数据分析
- 流量指标分析:流量指标是指用户在某一个网站操作的每一个步骤记录的指标,埋点数据,PV是指其浏览量,UV代表独立访客数,访问深度代表每个独立访客的浏览量,页面跳出率 则是指浏览某个页面离开的次数/这个页面的全部访问次数
1、不同时间下PV、UV的流量变化情况
1)每天的PV、UV变化情况
- 首先计算一下总流量
总PV值=数据条数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
data.shape[0]
总流量为12256906,在计算一下日平均流量、日平均独立访客数
##日PV
pv_daily = data.groupby([‘date’])[‘user_id’].count().reset_index().rename(columns={‘user_id’:‘pv_daily’})
pv_daily.head()
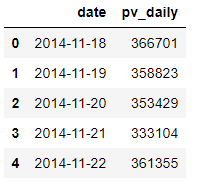
- 日平均独立访客数与日平均流量的区别在于要进行去重
##日UV
uv_daily = data.groupby([‘date’])[‘user_id’].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={‘user_id’:‘uv_daily’})
uv_daily.head()
s=uv_daily[‘uv_daily’]
pv_daily[‘uv_daily’]=s
pv_daily
将两表合并

plt.figure(figsize=(40,20),dpi=80)
font={
“family”:“kaiti”,
“size”:‘30’
}
plt.rc(“font”,**font)
plt.subplot(211)#在第一个位置日平均流量图
plt.plot(pv_daily[‘date’],pv_daily[‘pv_daily’],‘co-’)
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter(‘%m/%d’))
plt.gca().xaxis.set_major_locator(mdates.DayLocator()) # 按月显示,按日显示的话,将MonthLocator()改成DayLocator()
plt.gcf().autofmt_xdate()
ax=plt.gca()
ax.spines[“top”].set_color(“w”)
ax.spines[“bottom”].set_color(“r”)
ax.spines[“left”].set_color(“r”)
ax.spines[“right”].set_color(“w”)
plt.gcf().autofmt_xdate()
#设置X轴标签
plt.xlabel(“时间”)
#设置y轴标签
plt.ylabel(“日平均流量统计图”)
plt.title(‘日平均流量’)
plt.figure(figsize=(40,20), dpi=80)
plt.subplot(212)#第二个位置绘制日平均独立访客数
plt.plot(pv_daily[‘date’],pv_daily[‘uv_daily’],‘yo-’)
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter(‘%m/%d’))
plt.gca().xaxis.set_major_locator(mdates.DayLocator())
ax=plt.gca()
ax.spines[“top”].set_color(“w”)
ax.spines[“bottom”].set_color(“r”)
ax.spines[“left”].set_color(“r”)
ax.spines[“right”].set_color(“w”)
plt.title(‘日独立访问客流量’)
plt.gcf().autofmt_xdate()
#设置X轴标签
plt.xlabel(“时间”)
#设置y轴标签
plt.ylabel(“日独立访客量统计图”)
plt.show()
绘制子图,将日平均流量和独立访问客数放在一起进行对比分析:
-

-
可以发现在双十二当天是流量和独立访客数的高峰,在平常波动不大
每天时刻数据
每天的时刻数据
pv_daily_hour = data.groupby([‘hour’])[‘user_id’].count().reset_index().rename(columns={‘user_id’:‘pv’})
uv_daily_hour = data.groupby([‘hour’])[‘user_id’].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={‘user_id’:‘uv’})
pv_daily_hour.head()
uv_daily_hour.head()


plt.figure(figsize=(15,18),dpi=80)
plt.subplot(211)
plt.plot(pv_daily_hour[‘hour’],pv_daily_hour[‘pv’],‘bo-’)
plt.title(“每小时PV”)
plt.savefig(“每小时PV.png”)
plt.xticks(np.arange(0, 24, step=1))
plt.xlim(data.index.values[0])
plt.figure(figsize=(15,18),dpi=80)
plt.subplot(212)
plt.plot(uv_daily_hour[‘hour’],uv_daily_hour[‘uv’],‘yo-’)
plt.title(“每小时UV”)
plt.savefig(“每小时UV.png”)
plt.xticks(np.arange(0, 24, step=1))
plt.xlim(data.index.values[0])
plt.show()

- 从早上5:00-10:00,18:00-21:00这两个时间段pv有较明显上升;uv从早上6:00-10:00有较明显增加,而后到21点uv保持稳定数量,然后开始下降;pv、uv变化符合大众工作作息时间,侧面证明数据是真是有效的。
2、不同购物行为在不同时间维度下的变化情况
plt.figure(figsize=(10, 4))
sns.lineplot(data=d_pv_h, lw=3)
plt.show()

plt.figure(figsize=(10, 4))
sns.lineplot(data=d_pv_h.iloc[:, 1:], lw=3)
plt.show()

虽然大体上各波动趋势相同,但是加购物车数远高于收藏数。
每个UV的平均访问深度=总流量/独立访客数
round(data[‘user_id’].shape[0]/data[‘user_id’].nunique(),2)
##=1225.69
每个UV的日平均访问深度
round(data[‘user_id’].shape[0]/data[‘user_id’].nunique()/data[‘date’].nunique(),2)
##=39.54
分析期间,每个UV的平均PV量是1225.69,每个UV的平均访问深度是39.54
3 、用户转化行为漏斗模型分析
计算每一个行为环节用户的访问量
view = data.groupby([‘behavior_type’])[‘user_id’].count().reset_index().rename(columns={‘user_id’:‘pv’})
view.head
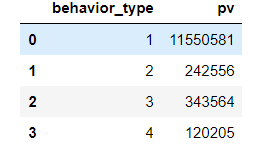
其中:
| beihavior_type | - |
| 1 | 点击 |
| 2 | 收藏 |
| 3 | 加购物车 |
| 4 | 支付 |
#计算各个环节的流失率

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
“text-align:center;width:211px;”>4支付
#计算各个环节的流失率
[外链图片转存中…(img-0WRFDW6H-1714911061917)]
[外链图片转存中…(img-GVkOp1Xg-1714911061917)]
[外链图片转存中…(img-xHVZU1Km-1714911061918)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









