







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- [提高向量搜索精度的方法](#_35)
+ [FastGPT 构建知识库方案](#FastGPT__43)
+ - [导入数据方案1 - 直接分段导入](#1___51)
- [导入数据方案2 - QA导入](#2__QA_59)
- [导入数据方案3 - 手动录入](#3___67)
- [导入数据方案4 - CSV录入](#4__CSV_75)
- [导入数据方案5 - API导入](#5__API_81)
+ [QA的组合与引用提示词构建](#QA_85)
FastGPT知识库结构讲解
本节会详细介绍 FastGPT 知识库结构设计,理解其 QA 的存储格式和多向量映射,以便更好的构建知识库。这篇介绍主要以使用为主,详细原理不多介绍。
理解向量
FastGPT 采用了 RAG 中的 Embedding 方案构建知识库,要使用好 FastGPT 需要简单的理解Embedding向量是如何工作的及其特点。
人类的文字、图片、视频等媒介是无法直接被计算机理解的,要想让计算机理解两段文字是否有相似性、相关性,通常需要将它们转成计算机可以理解的语言,向量是其中的一种方式。
向量可以简单理解为一个数字数组,两个向量之间可以通过数学公式得出一个距离,距离越小代表两个向量的相似度越大。从而映射到文字、图片、视频等媒介上,可以用来判断两个媒介之间的相似度。向量搜索便是利用了这个原理。
而由于文字是有多种类型,并且拥有成千上万种组合方式,因此在转成向量进行相似度匹配时,很难保障其精确性。在向量方案构建的知识库中,通常使用topk召回的方式,也就是查找前k个最相似的内容,丢给大模型去做更进一步的语义判断、逻辑推理和归纳总结,从而实现知识库问答。因此,在知识库问答中,向量搜索的环节是最为重要的。
影响向量搜索精度的因素非常多,主要包括:向量模型的质量、数据的质量(长度,完整性,多样性)、检索器的精度(速度与精度之间的取舍)。与数据质量对应的就是检索词的质量。
检索器的精度比较容易解决,向量模型的训练略复杂,因此数据和检索词质量优化成了一个重要的环节。
FastGPT 中向量的结构设计
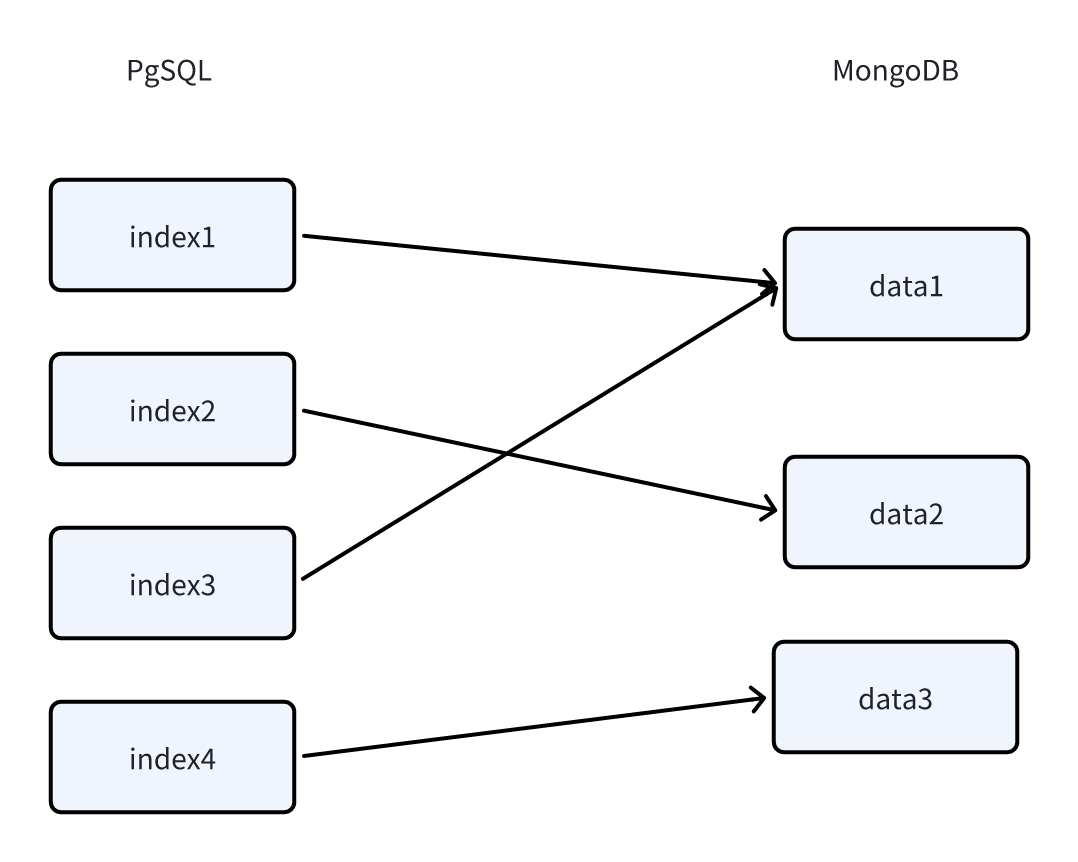
FastGPT 采用了 PostgresSQL 的 PG Vector 插件作为向量检索器,索引为HNSW。且PostgresSQL仅用于向量检索,MongoDB用于其他数据的存取。
在MongoDB的dataset.datas表中,会存储向量原数据的信息,同时有一个indexes字段,会记录其对应的向量ID,这是一个数组,也就是说,一组向量可以对应多组数据。
在PostgresSQL的表中,设置一个 index 字段用于存储向量。在检索时,会先召回向量,再根据向量的ID,去MongoDB中寻找原数据内容,如果对应了同一组原数据,则进行合并,向量得分取最高得分。
多向量的目的和使用方式
在一组向量中,内容的长度和语义的丰富度通常是矛盾的,无法兼得。因此,FastGPT 采用了多向量映射的方式,将一组数据映射到多组向量中,从而保障数据的完整性和语义的丰富度。
你可以为一组较长的文本,添加多组向量,从而在检索时,只要其中一组向量被检索到,该数据也将被召回。
提高向量搜索精度的方法
- 更好分词分段:当一段话的结构和语义是完整的,并且是单一的,精度也会提高。因此,许多系统都会优化分词器,尽可能的保障每组数据的完整性。
- 精简
index的内容,减少向量内容的长度:当index的内容更少,更准确时,检索精度自然会提高。但与此同时,会牺牲一定的检索范围,适合答案较为严格的场景。 - 丰富
index的数量,可以为同一个chunk内容增加多组index。 - 优化检索词:在实际使用过程中,用户的问题通常是模糊的或是缺失的,并不一定是完整清晰的问题。因此优化用户的问题(检索词)很大程度上也可以提高精度。
- 微调向量模型:由于市面上直接使用的向量模型都是通用型模型,在特定领域的检索精度并不高,因此微调向量模型可以很大程度上提高专业领域的检索效果。
FastGPT 构建知识库方案
在 FastGPT 中,整个知识库由库、集合和数据 3 部分组成。集合可以简单理解为一个文件。一个库中可以包含多个集合,一个集合中可以包含多组数据。最小的搜索单位是库,也就是说,知识库搜索时,是对整个库进行搜索,而集合仅是为了对数据进行分类管理,与搜索效果无关。(起码目前还是)
| 库 | 集合 | 数据 |
|---|---|---|
| img | img | img |
导入数据方案1 - 直接分段导入
选择文件导入时,可以选择直接分段方案。直接分段会利用句子分词器对文本进行一定长度拆分,最终分割中多组的q。如果使用了直接分段方案,我们建议在应用设置引用提示词时,使用通用模板即可,无需选择问答模板。
| 交互 | 结果 |
|---|---|
| img | img |
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
/618545628)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 7148
7148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









