






 本文介绍了FastGPT,一个基于大语言模型的开源问答系统,支持数据处理和模型调用,通过工作流可视化进行应用编排。文章详细阐述了本地部署所需的资源、镜像大小、模型配置,以及如何使用FastGPT构建智能应用,如财务助手,并评估了其文本处理、嵌入和召回功能。
本文介绍了FastGPT,一个基于大语言模型的开源问答系统,支持数据处理和模型调用,通过工作流可视化进行应用编排。文章详细阐述了本地部署所需的资源、镜像大小、模型配置,以及如何使用FastGPT构建智能应用,如财务助手,并评估了其文本处理、嵌入和召回功能。
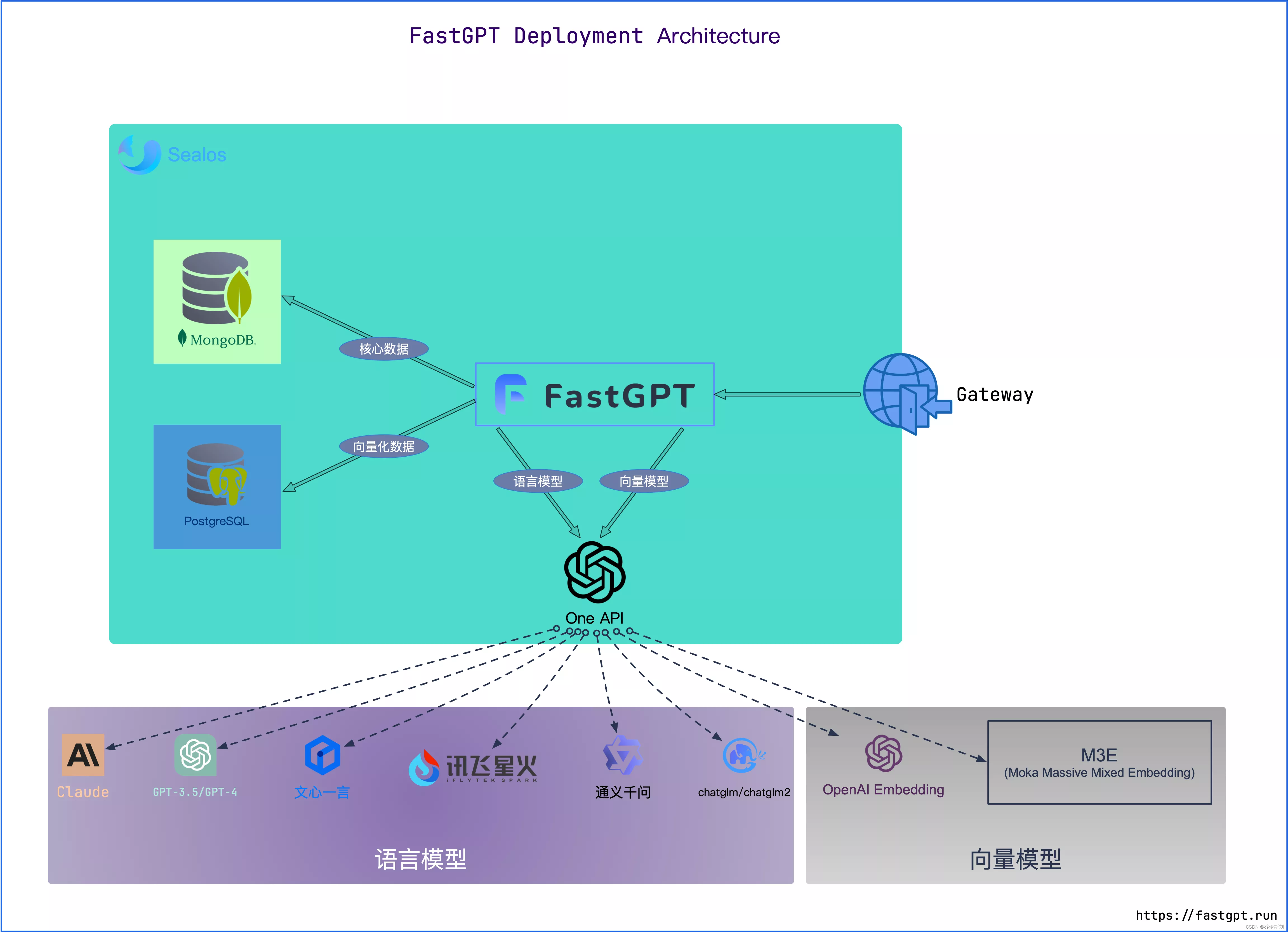
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过工作流可视化进行应用编排,从而实现复杂的问答场景和更好的模型体验。更赞的是,FastGPT 项目在 Apache License 2.0 许可下开源,是由环节云计算公司提供支持,具体情况可参考git官方说明。
1.本地安装资源情况
我们先来了解一下本地化部署fastgpt需要的镜像:
fastgpt:latest 镜像大小:349.65 MB
mongo:5.0.18 镜像大小:632.08 MB
one-api:latest 镜像大小:46.20 MB
pgvector:v0.5.0 镜像大小:394.77 MB
reranker:v0.1 模型镜像大小:7.65 GB(可选)
M3E模型镜像大小:6.95GB(可选)
上述镜像不包括本地化部署的大模型。根据以上的镜像大小情况,我们需要如下资源配置:
1.一台具备足够计算资源的服务器,建议安排8GB内存、4核CPU以及50GB以上存储的配置。
2.安装Docker和Docker Compose,以便在容器中运行FastGPT。
3.获取FastGPT的docker-compose.yml文件,该文件包含了部署FastGPT所需的所有配置信息,根据具体环境修改。
2.模型配置情况
新版 FastGPT 采用了 ConfigMap 的形式挂载配置文件,可以在 projects/app/data/config.json 看到默认的配置文件。配置文件中可以配置包括基模在内的基础大模型、embedding模型、reranker模型等,根据需要我们可以补充和调整。
默认情况下,FastGPT 只配置了 GPT 的模型,如果需要接入其他模型,需要部署和使用 One API,实现通义千问、文心一言、 ChatGLM 或本地模型的接入。
One API 是一个 OpenAI 接口管理 & 分发系统,可以通过标准的 OpenAI API 格式访问所有的大模型,开箱即用。
FastGPT 可以通过接入 One API 来实现对不同大模型的支持。
3.功能操作情况
我们仍以构建【智能财报分析助手】为例,展示fastGPT平台构建知识库时工具链的完整性、易用性,以进行各环节的技术能力和效果评估。
首先我们需要创建一个知识库。
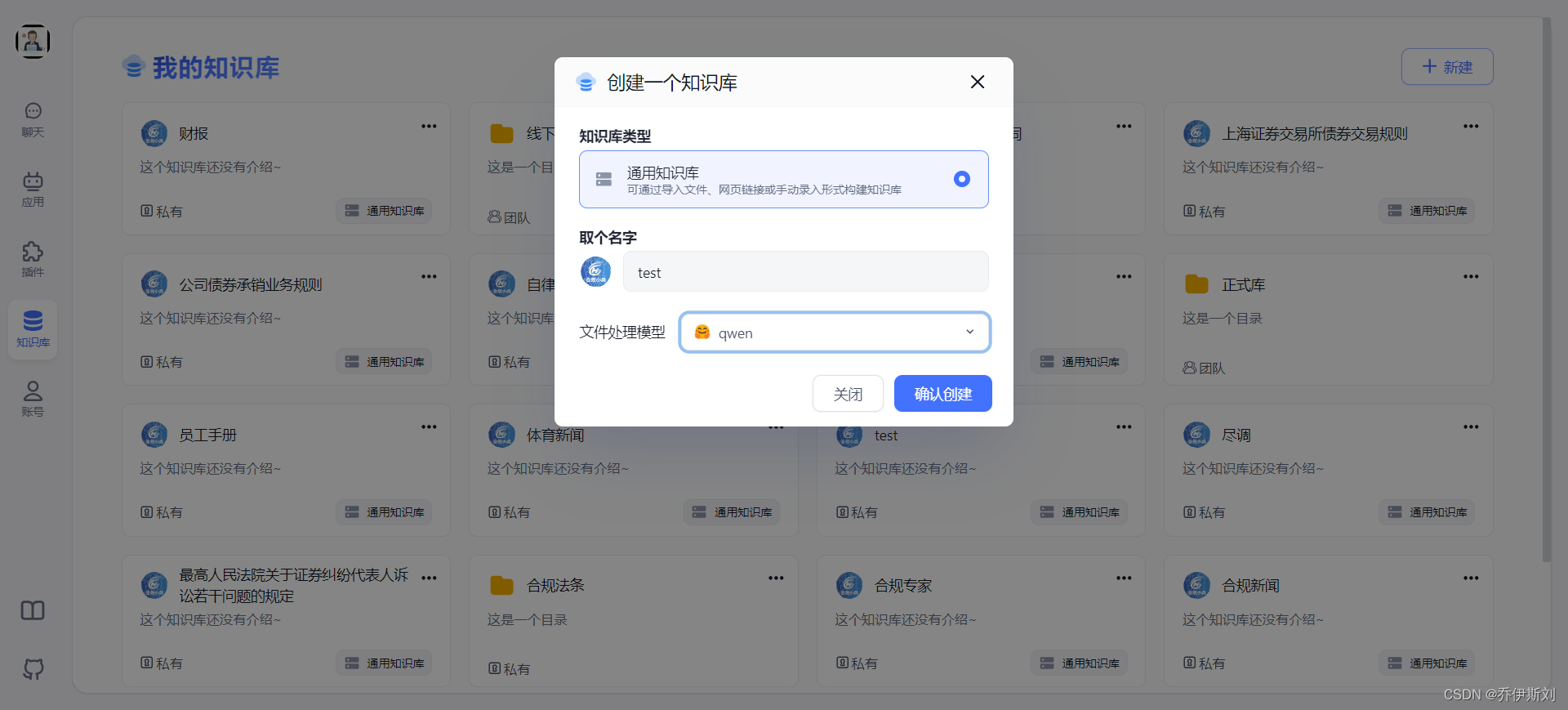
创建知识库时可以选择文件处理模型,这里的大模型作用是将文档智能拆分,辅助进行chunk和向量化存储。
知识库创建完之后我们需要上传一点内容。
上传内容这里有四种模式:
- 手动输入:手动输入问答对,是最精准的数据
- 文本数据集:选择文本文件,让AI自动生成问答对。文本数据集支持pdf\txt\docx等文件格式,也支持网页链接,也支持手动数据文本。
- 表格数据集:CSV 批量导入问答对。
这里,我们选择文本数据集,让大模型自动生成问答,若问答质量不高,可以后期手动修改。
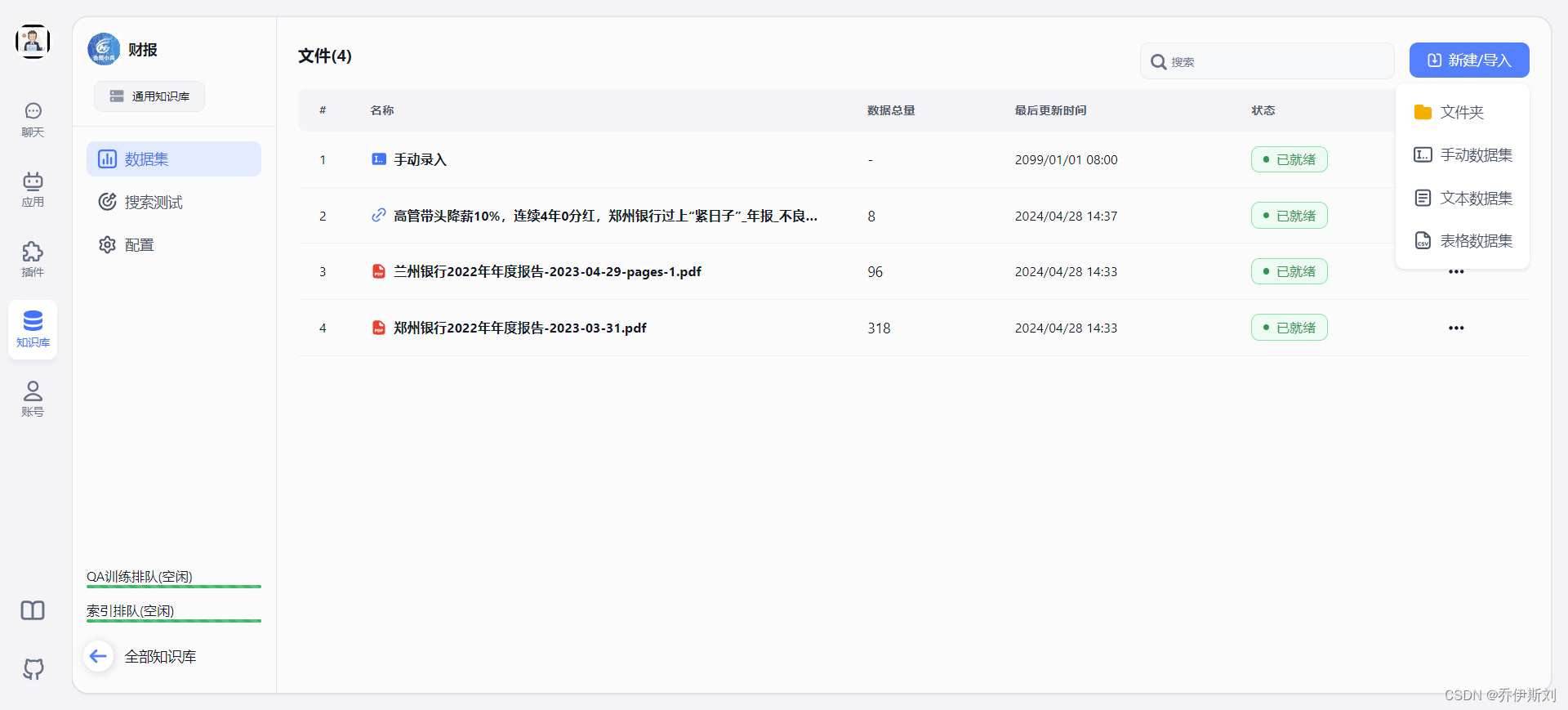
点击上传后我们需要等待数据处理完成,等到我们上传的文件状态为可用。
这时候fastGPT后台会调用模型资源进行文档chunk、简历索引、存储向量数据库等一系列操作。知识库左下角会展示文档处理所占用的资源及排队情况。
处理完成的文档,我们可以点开查看:
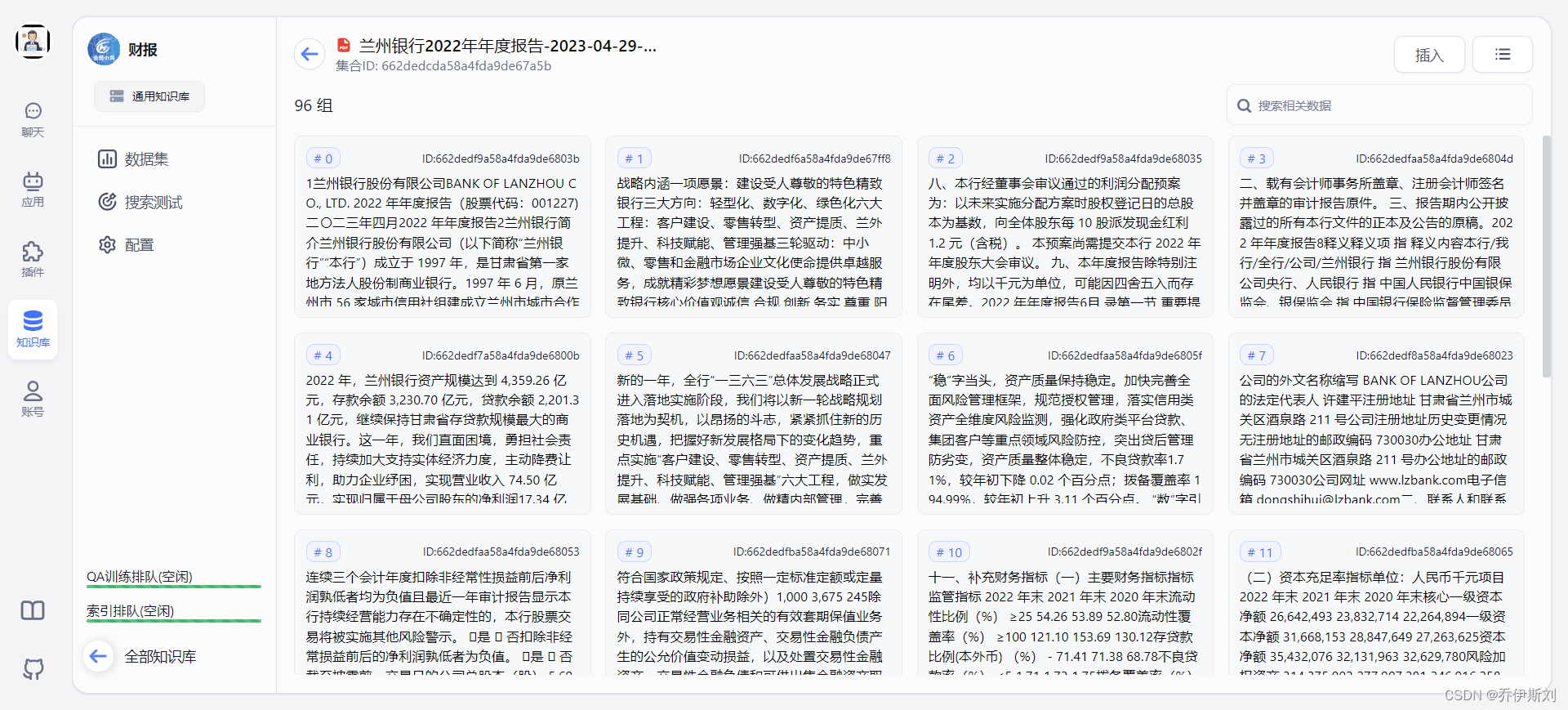
可以看到已分段,对于不满意的分款,点开每个文件块,可以自行修改。
接下来是创建应用。
点击「应用」按钮来新建一个应用,这里有四个模板,我们选择「知识库 + 对话引导」。
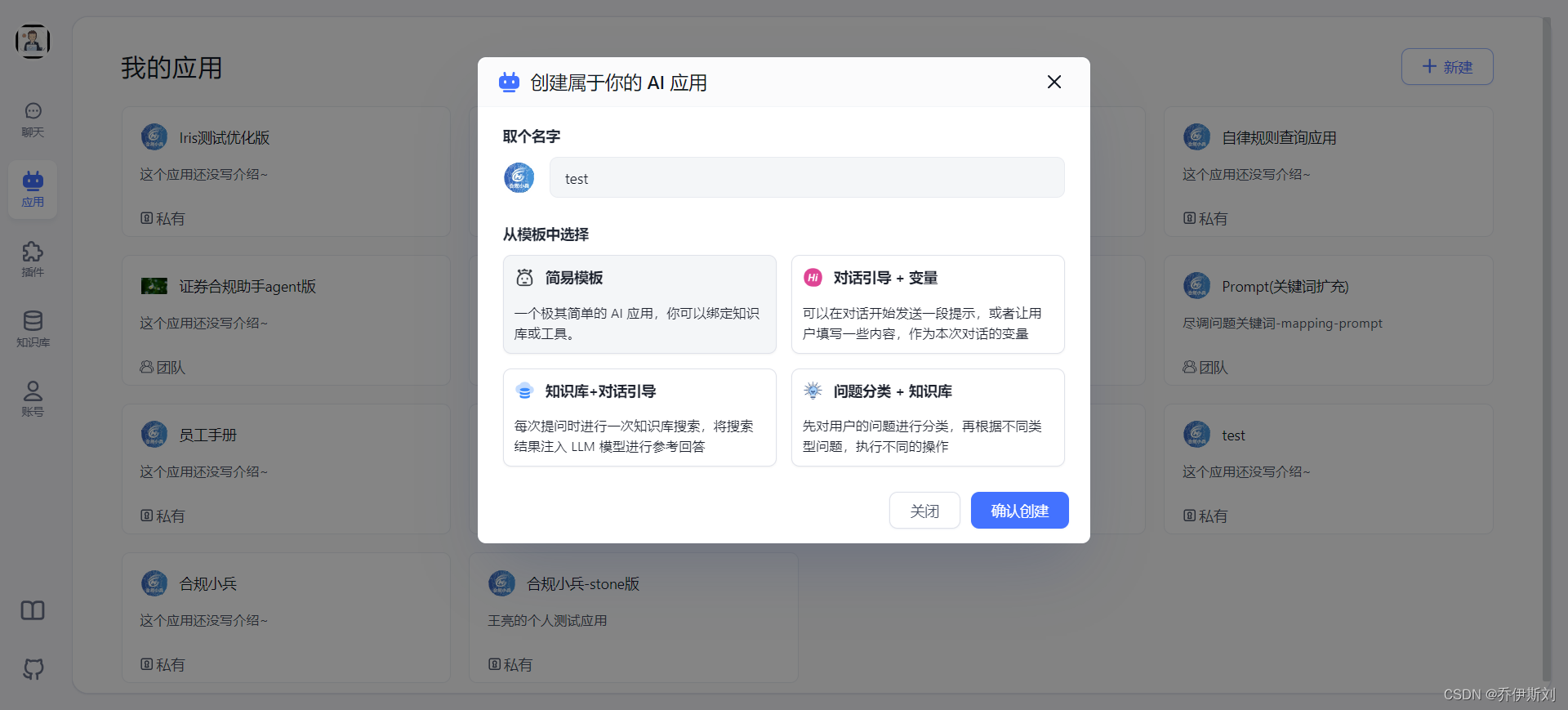
应用创建后来再应用详情页找到「知识库」模块,把我们刚刚创建的知识库添加进去。
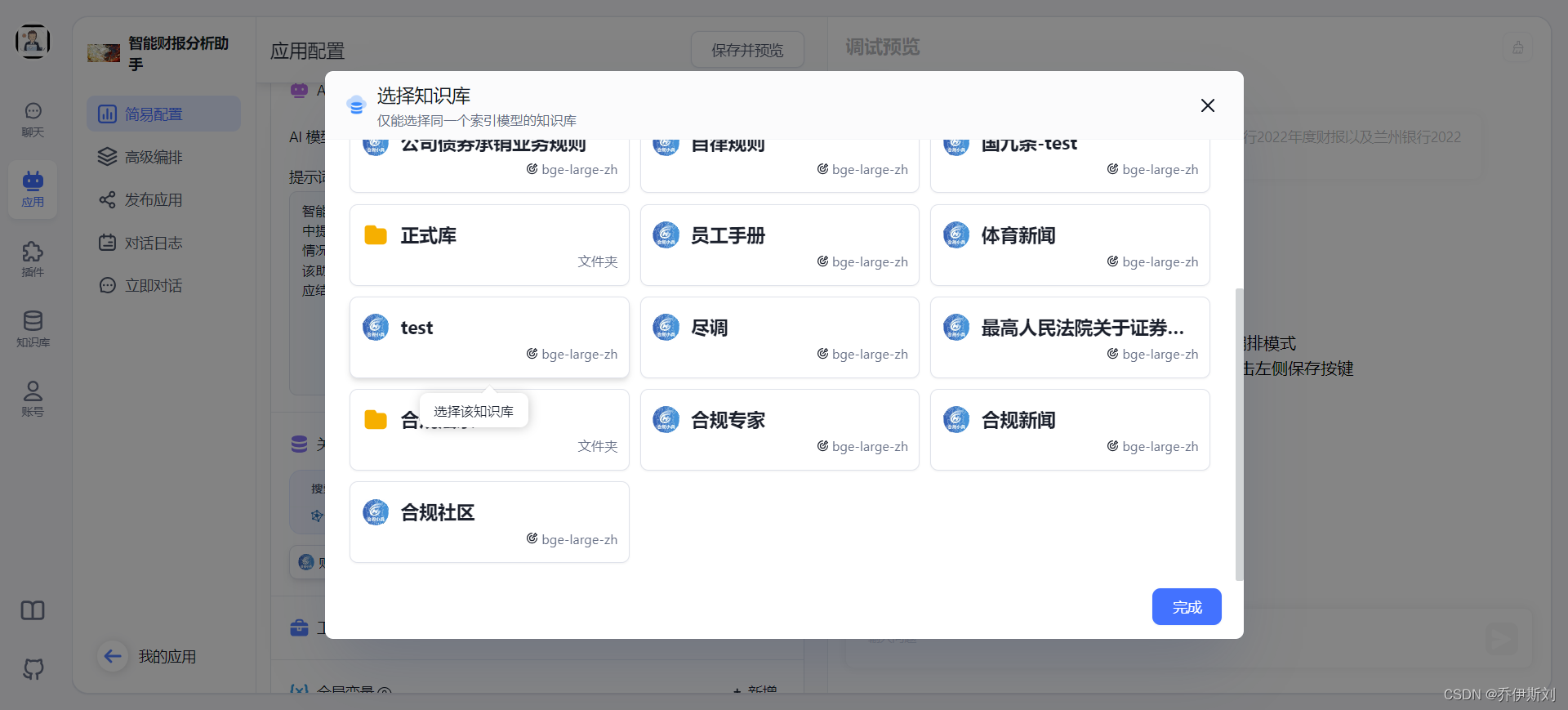
添加完知识库后记得点击「保存并预览」,这样我们的应用就和知识库关联起来了。
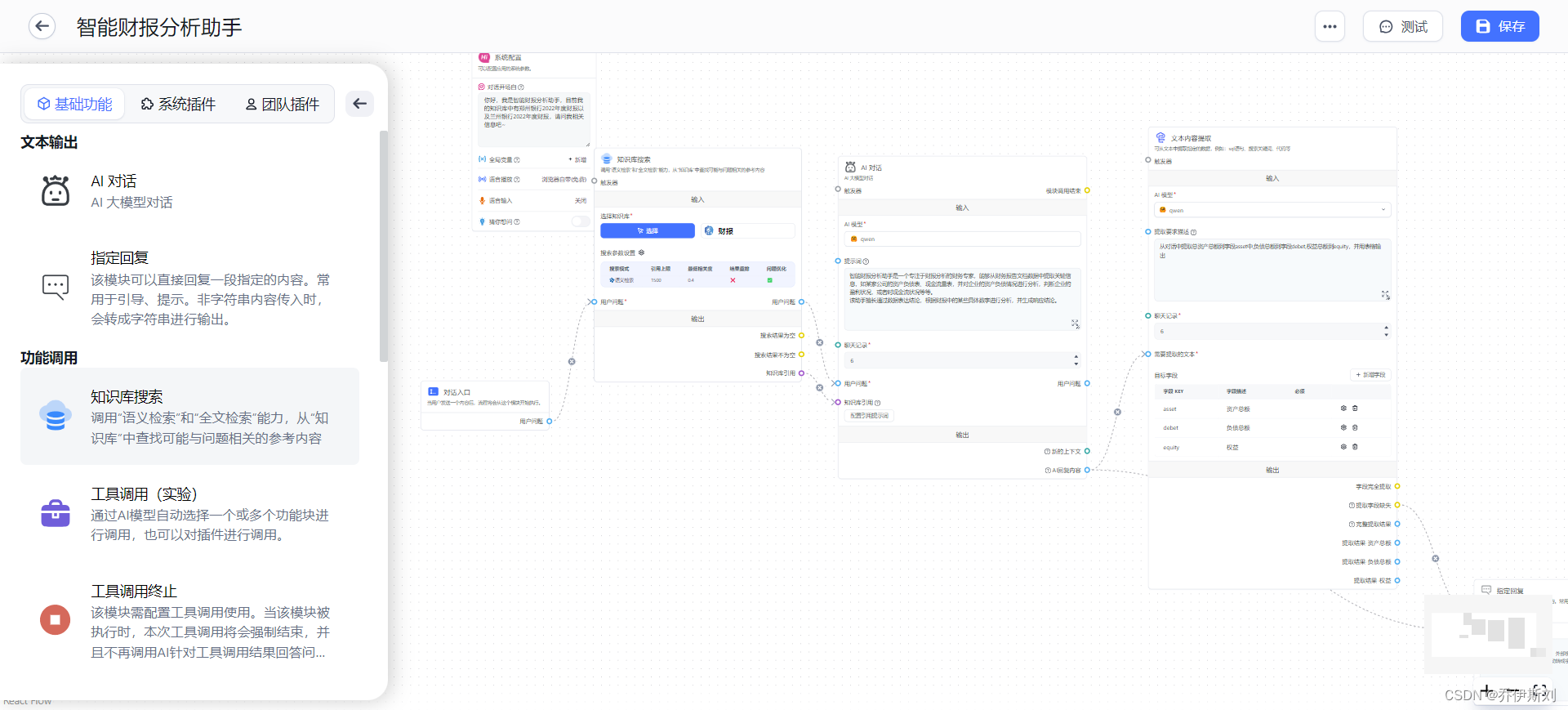
当然,我们还可以进行高级编排,让知识库变成agent应用。
目测比较有用的工具有http请求、问题分类、工具调用等,可以根据用户场景搭配使用。
值得一提的是,FastGPT支持web站点静态页面数据同步,即利用爬虫的技术,可以通过一个入口网站,自动捕获同域名下的所有网站,目前最多支持200个子页面。出于合规与安全角度FastGPT 仅支持静态站点的爬取,主要用于各个文档站点快速构建知识库。但是国内许多媒体站点基本不可用。 本次构建的是财务助手,可以将相关财务信息的站点url直接导入,利用fastgpt进行分段和索引。这种方式在知识库的数据更新上更具优势。
4.效果评价
1. 文本chunk:
在实验中,我们发现md5格式的文档更好的能被模型理解和解析,它清晰的段落和标题有助于文档切分。但目前系统中还没有自动将文档转为Md5格式的功能,需要系统外处理好再作为知识库上传。
2. embedding:
embedding效果主要取决于embedding模型的好坏,常用的中文embedding模型bge-large-zh,可以根据我们具体处理的任务进行进一步的微调,比如针对sql向量化处理的,针对金融专业词汇的,微调后的向量模型可以进一步提高后续召回的准确性。
3. 召回及重排序:
fastGPT提供语义检索(使用向量进行文本相关性查询)、全文检索(使用传统的全文检索,适合查找一些关键词和主调语特殊的数据)、混合检索(使用向量检索与全文检索的综合结果返回,使用RRF算法进行排序),最后还可以使用重排模型(reranker模型)来进行二次排序,可增强综合排名。reranker常用的有bge-rerank-v2-m3,同样也可以根据场景进行相应的微调。
4. prompt优化:
fastGPT提供“问题优化”功能,开启该功能后,在进行知识库搜索时,会根据对话记录,利用大模型补全问题,优化描述。该步骤本质上也是通过提示工程来优化问题。另外,在进行知识库引用传给大模型时,提供了多个模板,适用于不同类型的知识结构。如标准提示词,用于结构不固定的知识库,用标签引用知识库内容,并根据内容回答, 如果不清楚问题需要澄清等等。另外比如问答模板,适合 QA 问答结构的知识库,可以让大模型较为严格的按预设内容回答。
整体来看,fast GPT在知识库的快速构建中提供了完善的工具链,逻辑清晰,插件易用。开放开源的能力也可以使开发者根据具体场景微调相关逻辑,优化召回效果。最重要的是,fastGPT支持本地化部署,对企业的私有化知识提供了保护。支持本地大模型和外部商用大模型,灵活边界,使开发者可以根据费用情况灵活安排。总而言之,fastGPT值得一试。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









