








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
文章目录
3. DataFrame 的行列标签和行列位置编号
3.1 DataFrame 的行标签和列标签
1)如果所示,分别是 DataFrame 的行标签和列标签
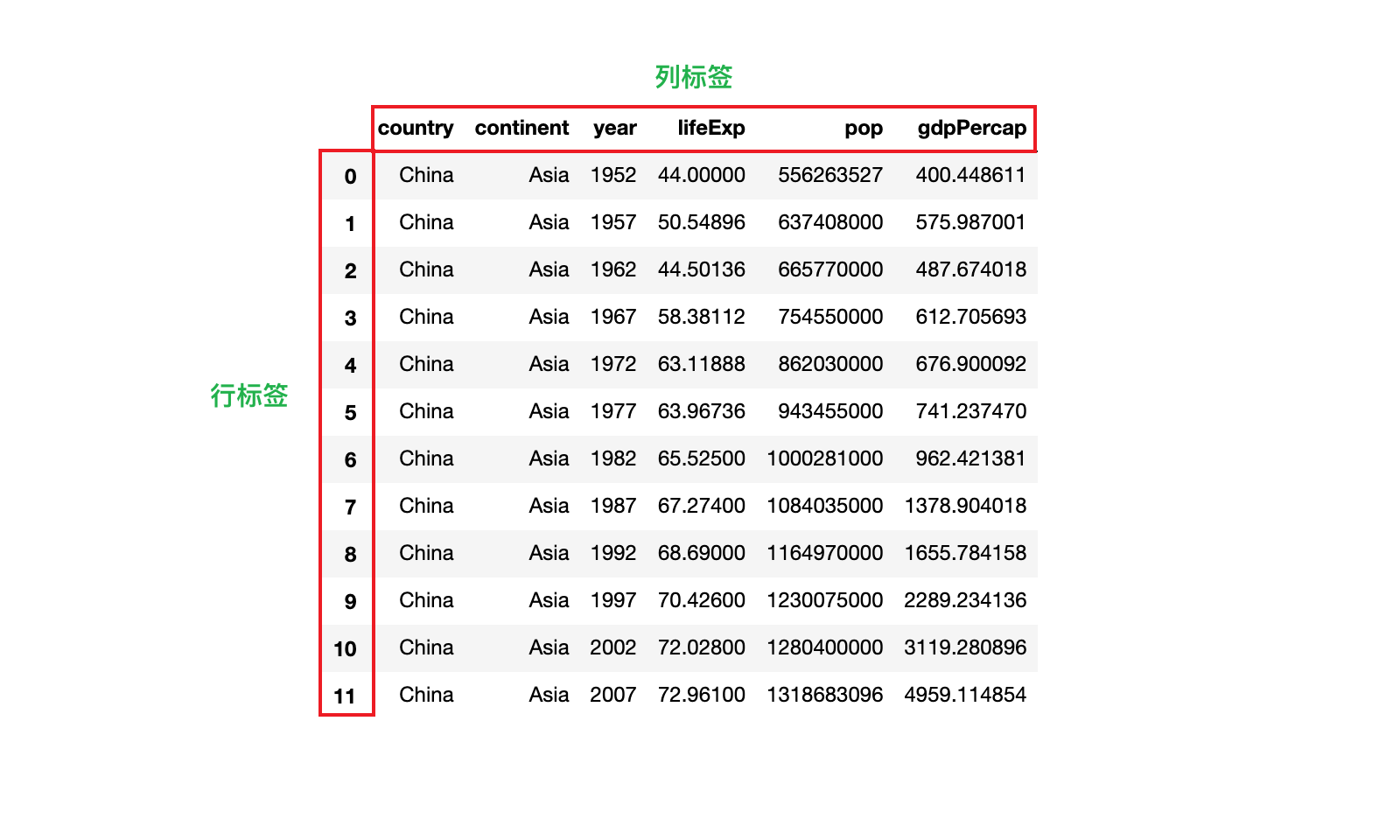
2)获取 DataFrame 的行标签
# 获取 DataFrame 的行标签
china.index

3)获取 DataFrame 的列标签
# 获取 DataFrame 的列标签
china.columns

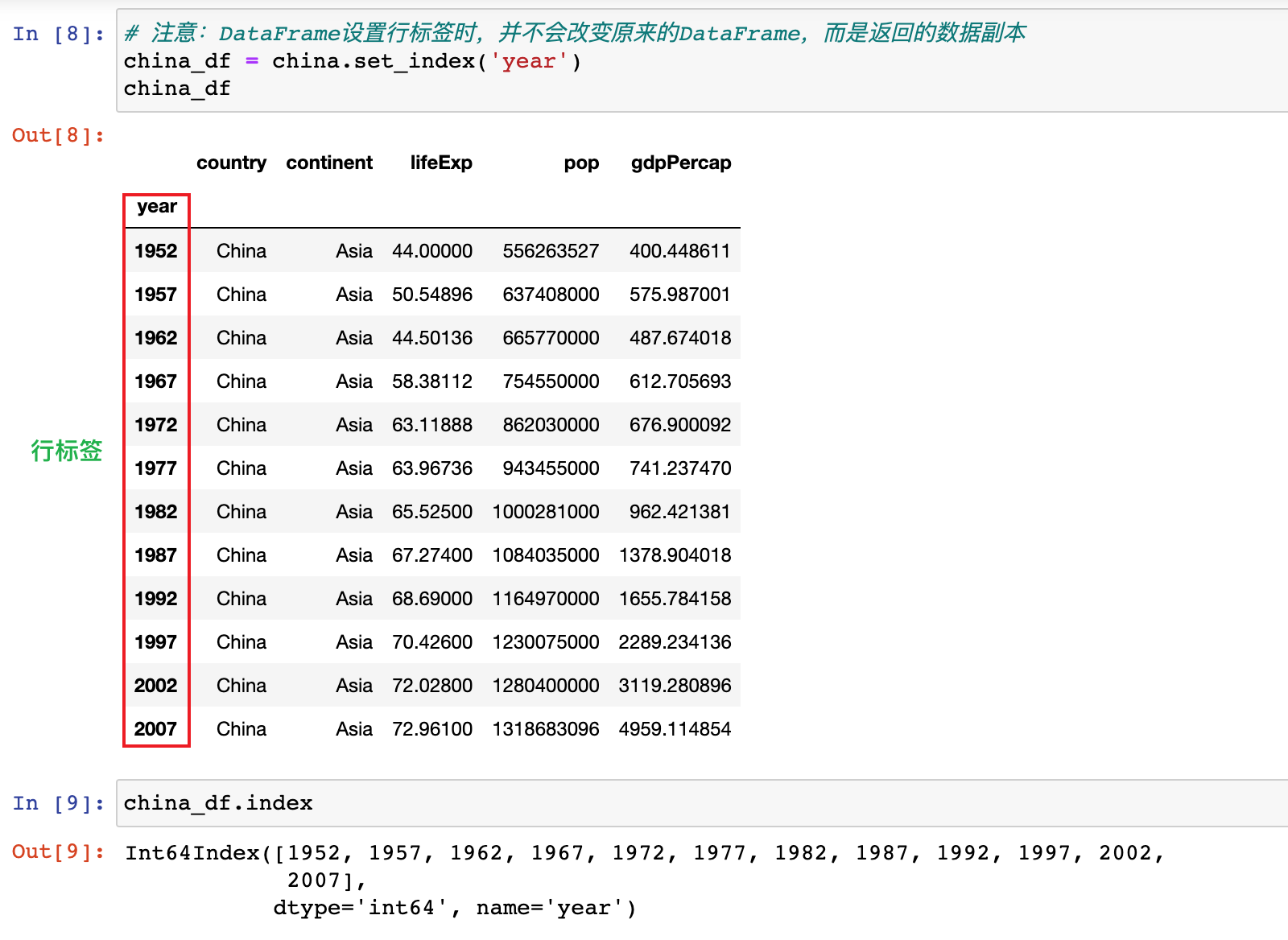
4)设置 DataFrame 的行标签
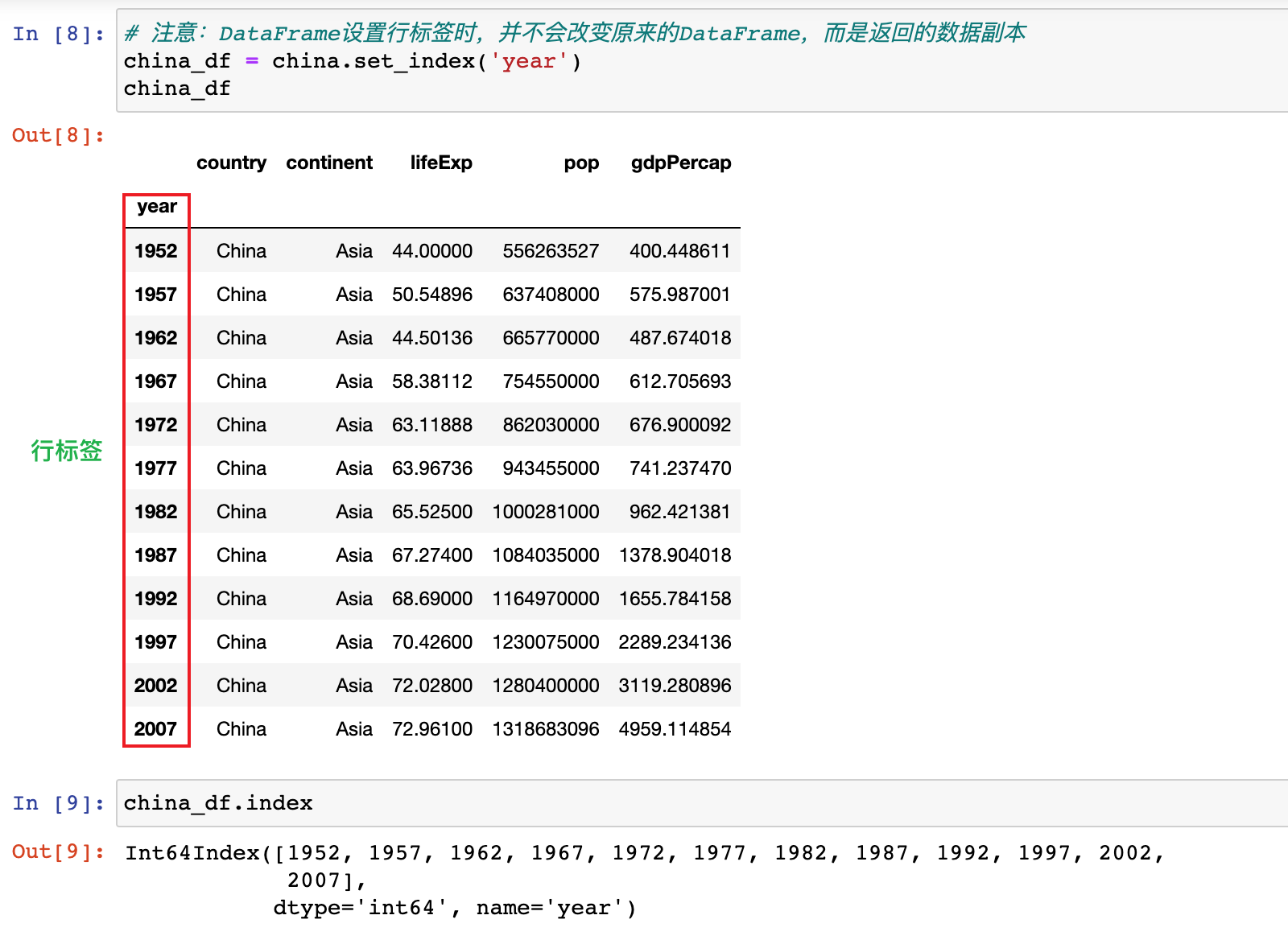
# 注意:DataFrame设置行标签时,并不会改变原来的DataFrame,而是返回的副本
china_df = china.set_index('year')
3.2 DataFrame 的行位置编号和列位置编号
DataFrame 除了行标签和列标签之外,还具有行列位置编号。
行位置编号:从上到下,第1行编号为0,第二行编号为1,…,第n行编号为n-1
列位置编号:从左到右,第1列编号为0,第二列编号为1,…,第n列编号为n-1
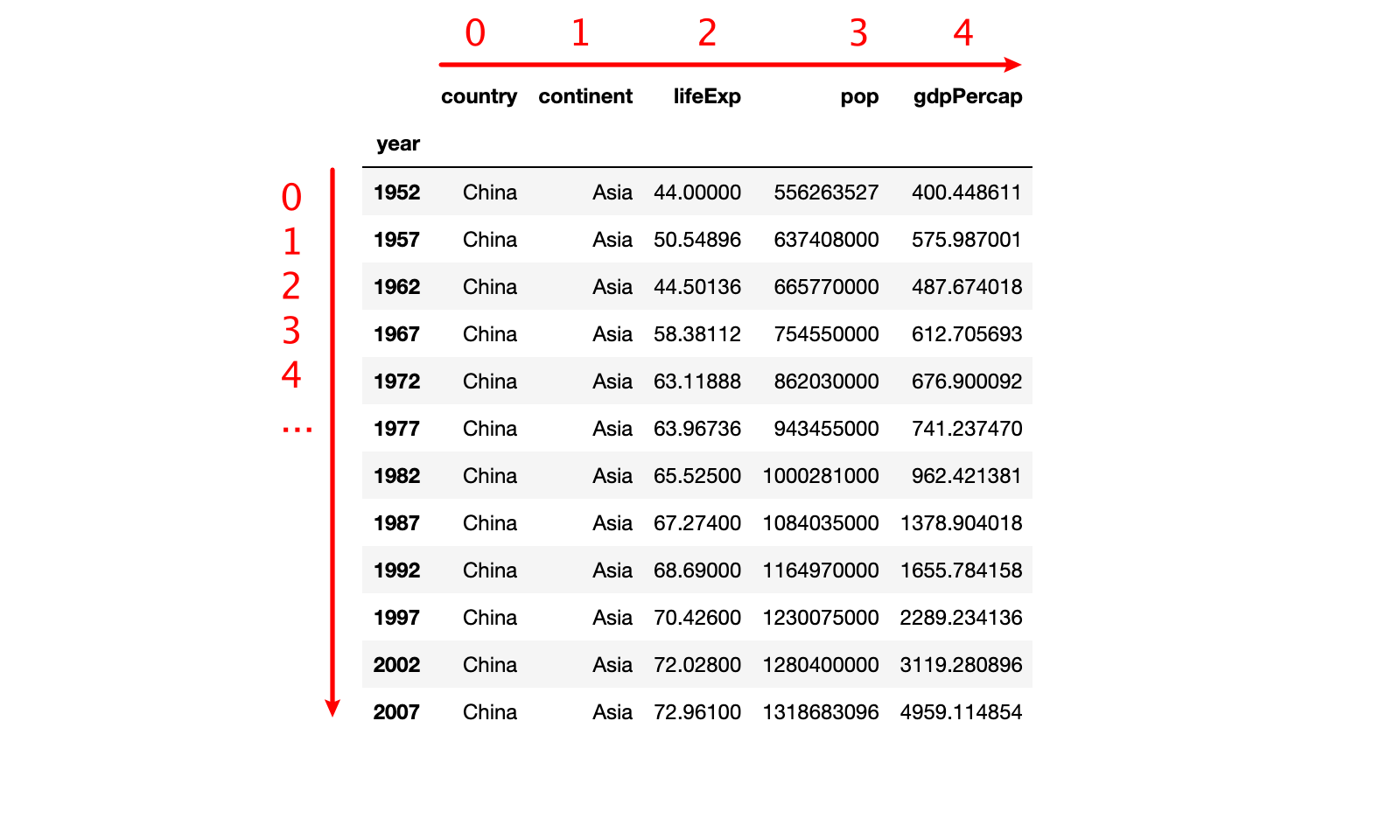
注意:默认情况下,行标签和行位置编号是一样的。
4. DataFrame 获取指定行列的数据
以下示例都使用加载的 gapminder.tsv 数据集进行操作,注意将 year 这一列设置为行标签。
4.1 loc函数获取指定行列的数据
基本格式:
| 语法 | 说明 |
|---|---|
df.loc[[行标签1, ...], [列标签1, ...]] | 根据行标签和列标签获取对应行的对应 列的数据,结果为:DataFrame |
df.loc[[行标签1, ...]] | 根据行标签获取对应行的所有列的数据 结果为:DataFrame |
df.loc[:, [列标签1, ...]] | 根据列标签获取所有行的对应列的数据 结果为:DataFrame |
df.loc[行标签] | 1)如果结果只有一行,结果为:Series 2)如果结果有多行,结果为:DataFrame |
df.loc[[行标签]] | 无论结果是一行还是多行,结果为DataFrame |
df.loc[[行标签], 列标签] | 1)如果结果只有一列,结果为:Series, 行标签作为 Series 的索引标签 2)如果结果有多列,结果为:DataFrame |
df.loc[行标签, [列标签]] | 1)如果结果只有一行,结果为:Series, 列标签作为 Series 的索引标签 2)如果结果有多行,结果为DataFrame |
df.loc[行标签, 列标签] | 1)如果结果只有一行一列,结果为单个值 2)如果结果有多行一列,结果为:Series, 行标签作为 Series 的索引标签 3)如果结果有一行多列,结果为:Series, 列标签作为 Series 的索引标签 4)如果结果有多行多列,结果为:DataFrame |
演示示例:
示例1:获取行标签为 1952, 1962, 1972 行的 country、pop、gdpPercap 列的数据
示例2:获取行标签为 1952, 1962, 1972 行的所有列的数据
示例3:获取所有行的 country、pop、gdpPercap 列的数据
示例4:获取行标签为 1957 行的所有列的数据
示例5:获取行标签为 1957 行的 lifeExp 列的数据
示例实现:
1)示例1:获取行标签为 1952, 1962, 1972 行的 country、pop、gdpPercap 列的数据
# 示例1:获取行标签为 1952, 1962, 1972 行的 country、pop、gdpPercap 列的数据
china_df.loc[[1952, 1962, 1972], ['country', 'pop', 'gdpPercap']]

2)示例2:获取行标签为 1952, 1962, 1972 行的所有列的数据
# 示例2:获取行标签为 1952, 1962, 1972 行的所有列的数据
china_df.loc[[1952, 1962, 1972]]

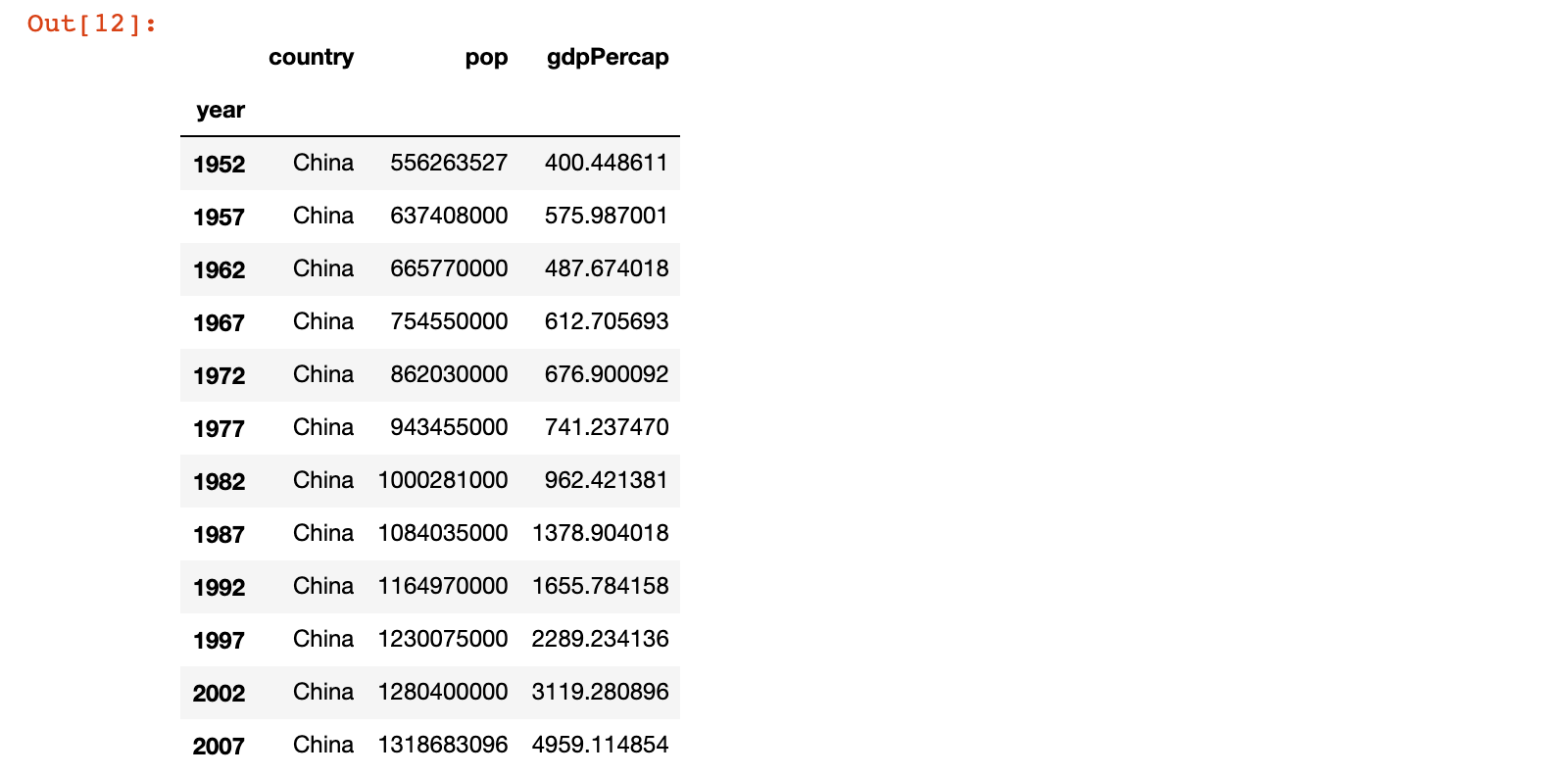
3)示例3:获取所有行的 country、pop、gdpPercap 列的数据
# 示例3:获取所有行的 country、pop、gdpPercap 列的数据
china_df.loc[:, ['country', 'pop', 'gdpPercap']]
4)示例4:获取行标签为 1957 行的所有列的数据
# 示例4:获取行标签为 1957 行的所有列的数据
china_df.loc[1957]

# 示例4:获取行标签为 1957 行的所有列的数据
china_df.loc[[1957]]

5)示例5:获取行标签为 1957 行的 lifeExp 列的数据
# 示例5:获取行标签为 1957 行的 lifeExp 列的数据
china_df.loc[[1957], 'lifeExp']
或
china_df.loc[1957, ['lifeExp']]
或
china_df.loc[1957, 'lifeExp']

4.2 iloc函数获取指定行列的数据
基本格式:
| 语法 | 说明 |
|---|---|
df.iloc[[行位置1, ...], [列位置1, ...]] | 根据行位置和列位置获取对应行的对应 列的数据,结果为:DataFrame |
df.iloc[[行位置1, ...]] | 根据行位置获取对应行的所有列的数据 结果为:DataFrame |
df.iloc[:, [列位置1, ...]] | 根据列位置获取所有行的对应列的数据 结果为:DataFrame |
df.iloc[行位置] | 结果只有一行,结果为:Series |
df.iloc[[行位置]] | 结果只有一行,结果为:DataFrame |
df.iloc[[行位置], 列位置] | 结果只有一行一列,结果为:Series, 行标签作为 Series 的索引标签 |
df.iloc[行位置, [行位置]] | 结果只有一行一列,结果为:Series, 列标签作为 Series 的索引标签 |
df.iloc[行位置, 行位置] | 结果只有一行一列,结果为单个值 |
演示示例:
示例1:获取行位置为 0, 2, 4 行的 0、1、2 列的数据
示例2:获取行位置为 0, 2, 4 行的所有列的数据
示例3:获取所有行的列位置为 0、1、2 列的数据
示例4:获取行位置为 1 行的所有列的数据
示例5:获取行位置为 1 行的列位置为 2 列的数据
示例实现:
1)示例1:获取行位置为 0, 2, 4 行的 0、1、2 列的数据
# 示例1:获取行位置为 0, 2, 4 行的 0、1、2 列的数据
china_df.iloc[[0, 2, 4], [0, 1, 2]]

2)示例2:获取行位置为 0, 2, 4 行的所有列的数据
# 示例2:获取行位置为 0, 2, 4 行的所有列的数据
china_df.iloc[[0, 2, 4]]

3)示例3:获取所有行的列位置为 0、1、2 列的数据
# 示例3:获取所有行的列位置为 0、1、2 列的数据
china_df.iloc[:, [0, 1, 2]]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
图片转存中...(img-Dc0lWXh1-1715036442566)]
[外链图片转存中...(img-6yVI81f8-1715036442567)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









