







1.7jdk解压、改名
mkdir -p /export/server
解压jdk:
tar -zxvf /usr/local/jdk-8u401-linux-x64.tar.gz -C /export/server/
改名jdk:
mv /export/server/jdk1.8.0_401 /export/server/jdk
1.8配置并应用环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin

source /etc/profile
到此为止可以把这台虚拟机克隆两份了,分别叫node2和node3,注意要放到不同的文件夹下。
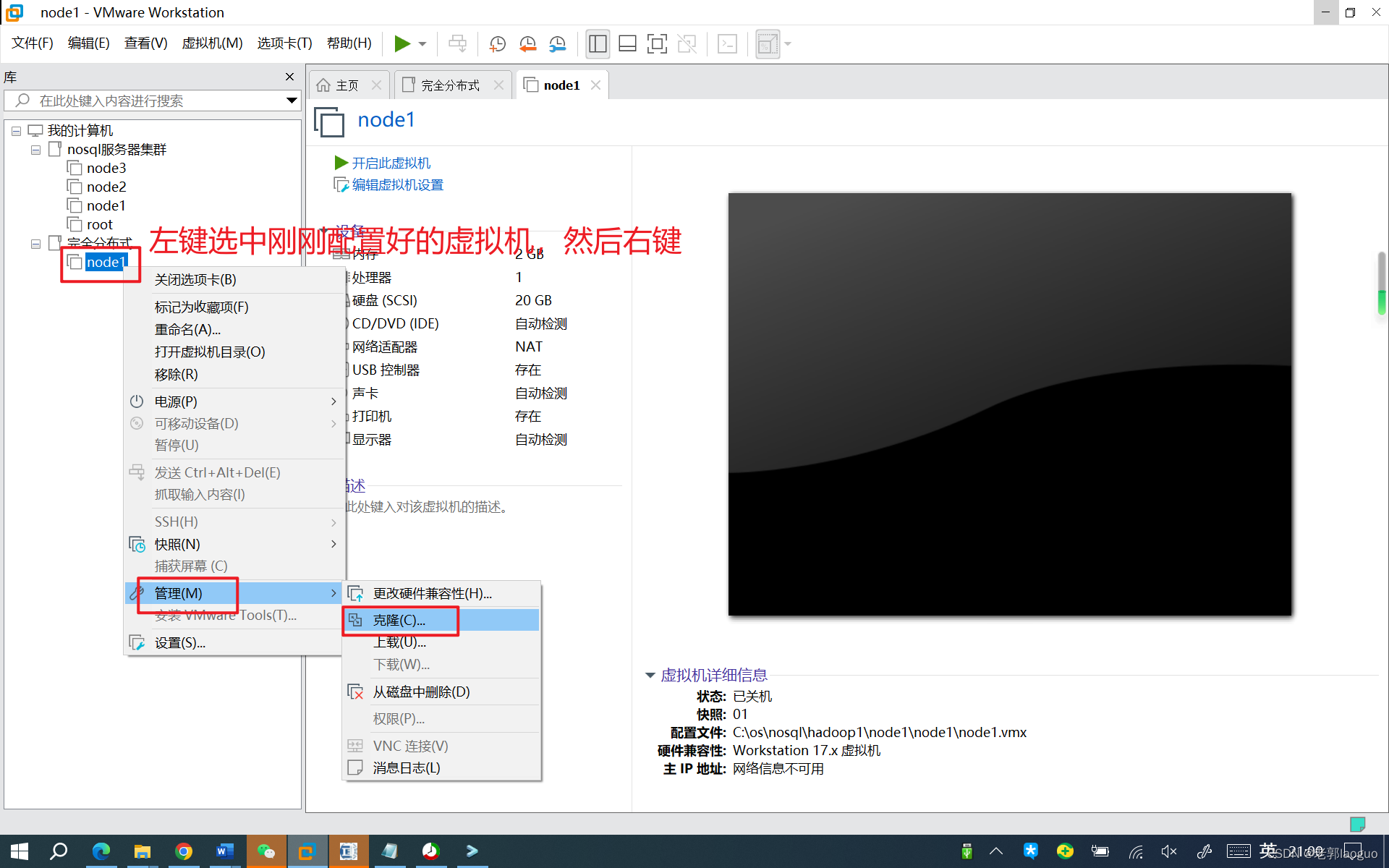

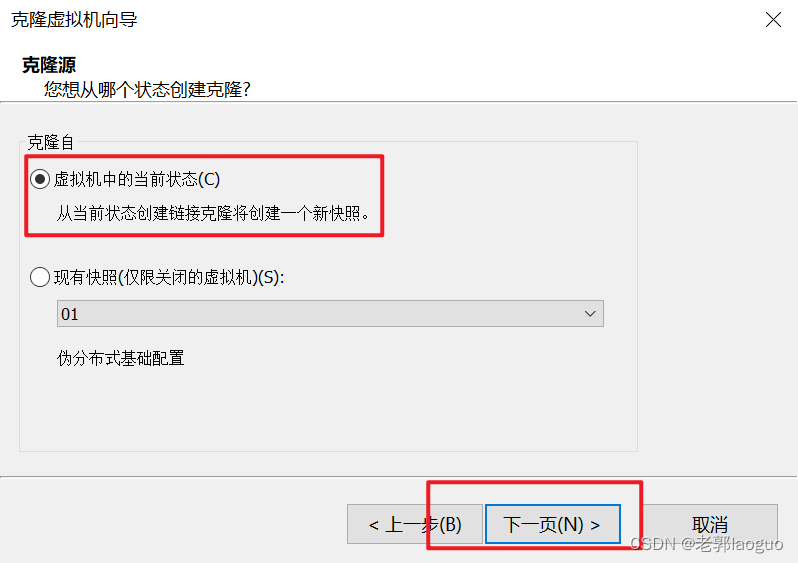
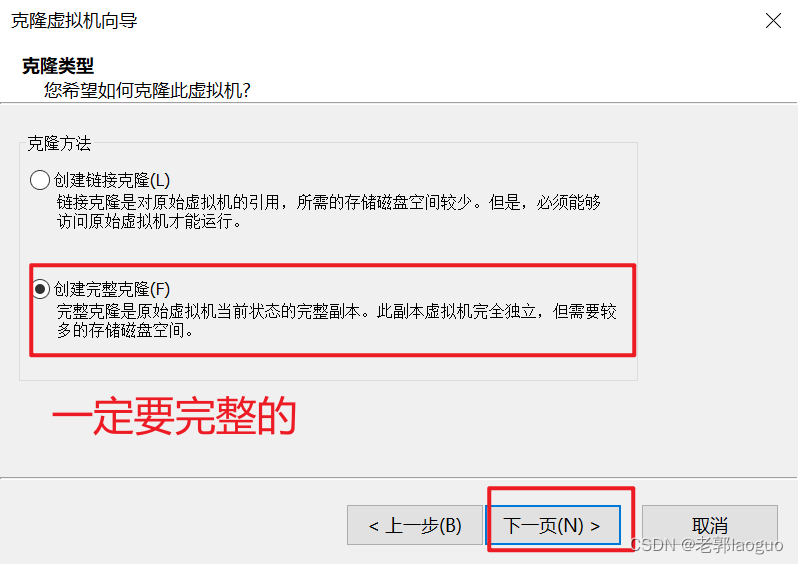
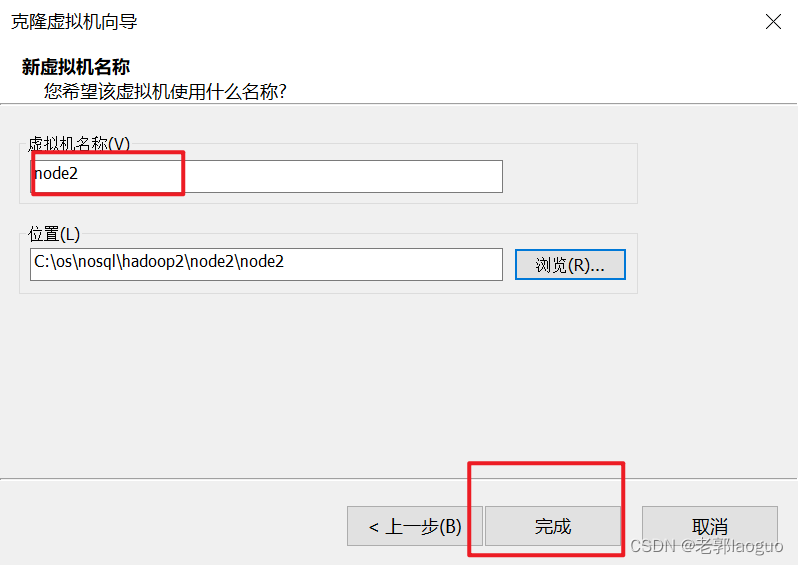
node3同理
2.克隆之后的修改(两台同时修改,不要弄混)
2.1改主机名(是几改几)
hostnamectl set-hostname node2
hostnamectl set-hostname node3
2.2修改静态ip
三台虚拟机的ip不能相同,最后一位改下就行,别忘了出来重启下网卡
vim /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
3.hadoop完全分布式配置
3.1解压、改名和配置、应用环境变量
解压hadoop:
tar -zxvf /usr/local/hadoop-2.7.7.tar.gz -C /usr/local/
改名hadoop:
mv /usr/local/hadoop-2.7.7 /usr/local/hadoop
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
3.2配置hadoop-env.sh
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
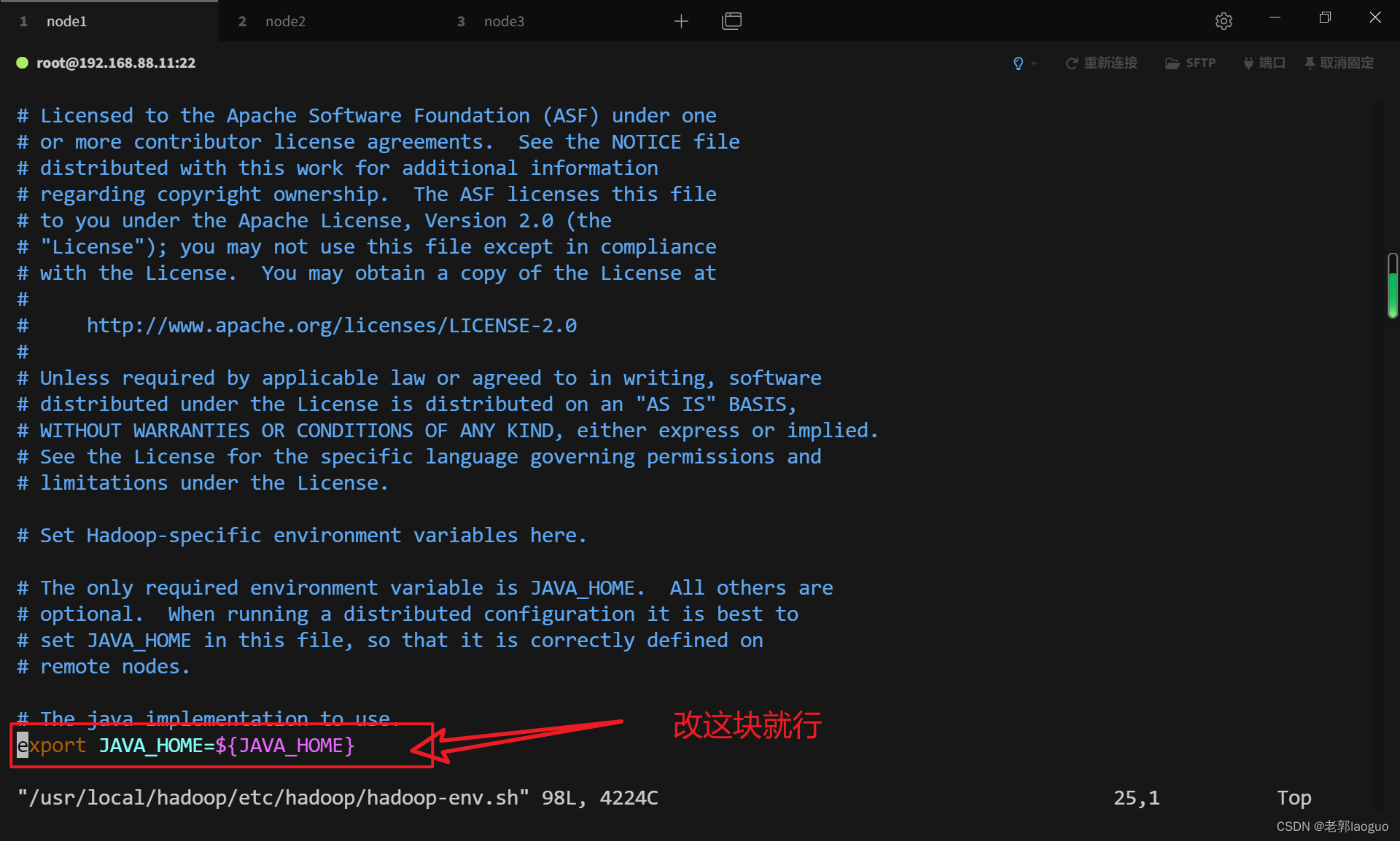
export JAVA_HOME=/export/server/jdk
3.3配置core-site.xml
vim /usr/local/hadoop/etc/hadoop/core-site.xml

<property>
<!--主机映射名-->
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
3.4配置hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml

<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!--主机映射名-->
<name>dfs.namenode.secondary.http-address</name>
<value>node3:50090</value>
</property>
3.5配置mapred-env.sh
vim /usr/local/hadoop/etc/hadoop/mapred-env.sh
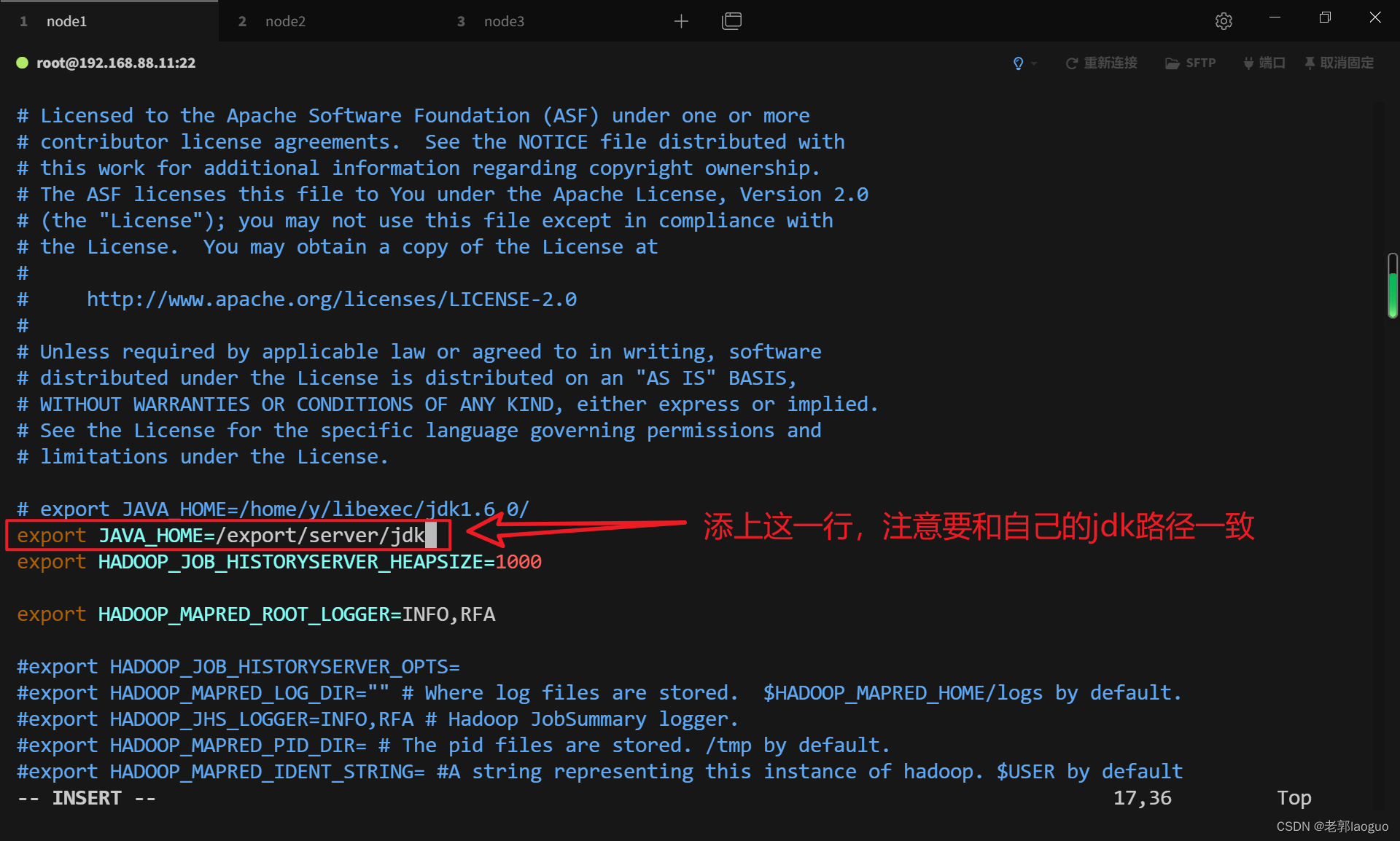
export JAVA_HOME=/export/server/jdk
3.6配置mapred-site.xml
配置前先复制一份(因为没有)
cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
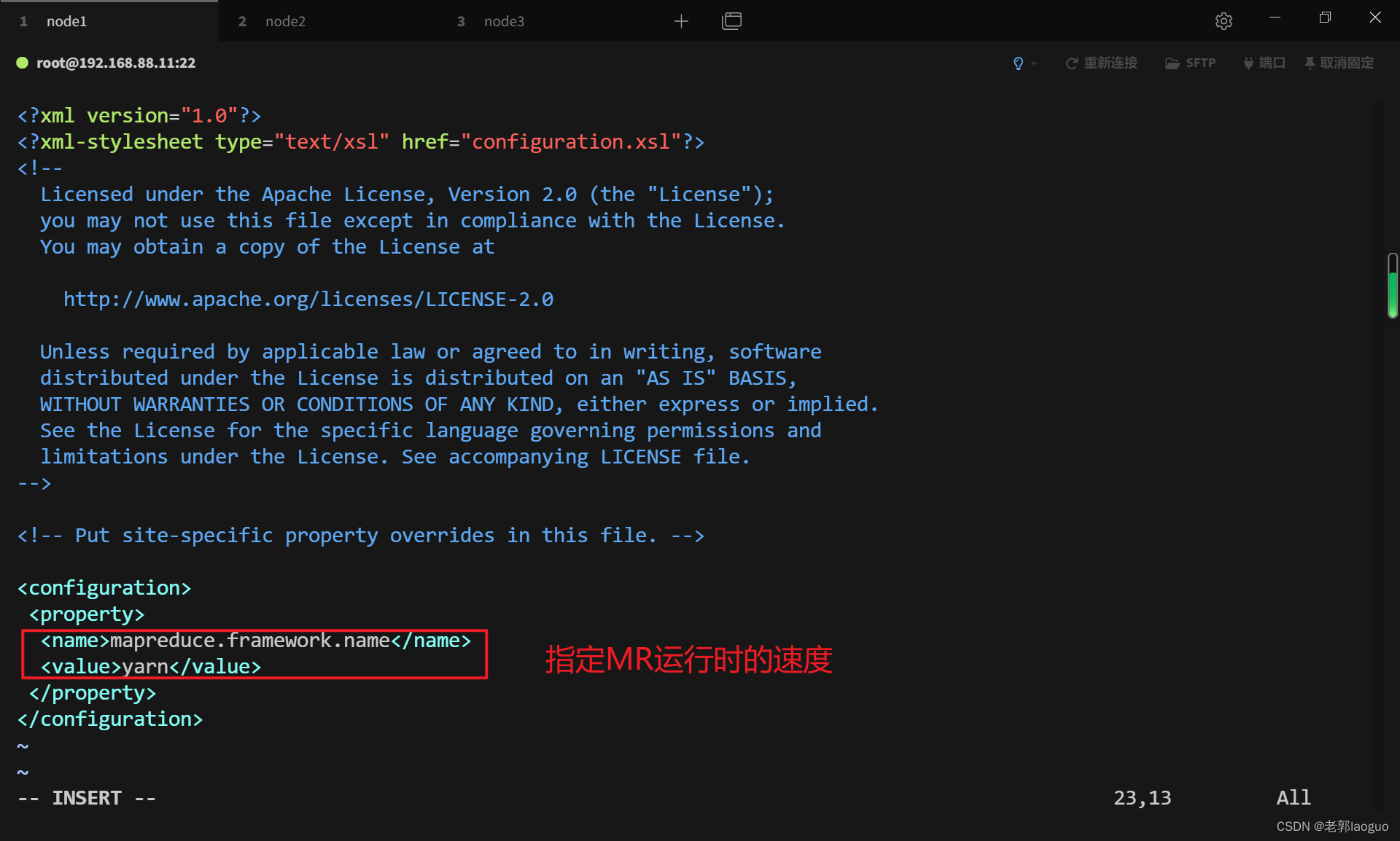
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.7配置yarn-env.sh
vim /usr/local/hadoop/etc/hadoop/yarn-env.sh

export JAVA_HOME=/export/server/jdk
3.8配置yarn-site.xml
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
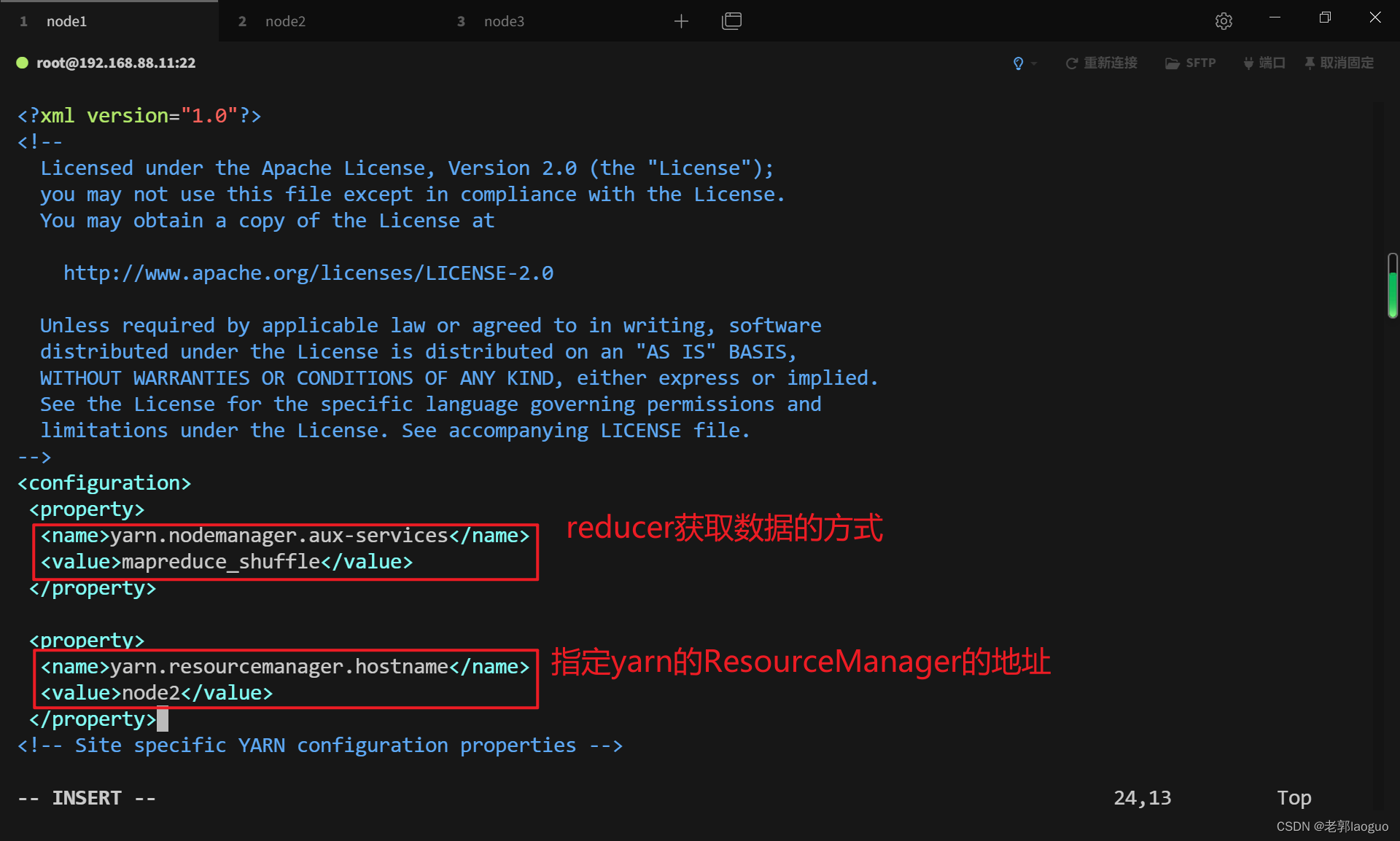
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
3.9配置slaves
vim /usr/local/hadoop/etc/hadoop/slaves

node1
node2
node3
3.10把主机上配好的内容分发到从机上
scp -r /usr/local/hadoop root@node2:/usr/local
scp -r /usr/local/hadoop root@node3:/usr/local
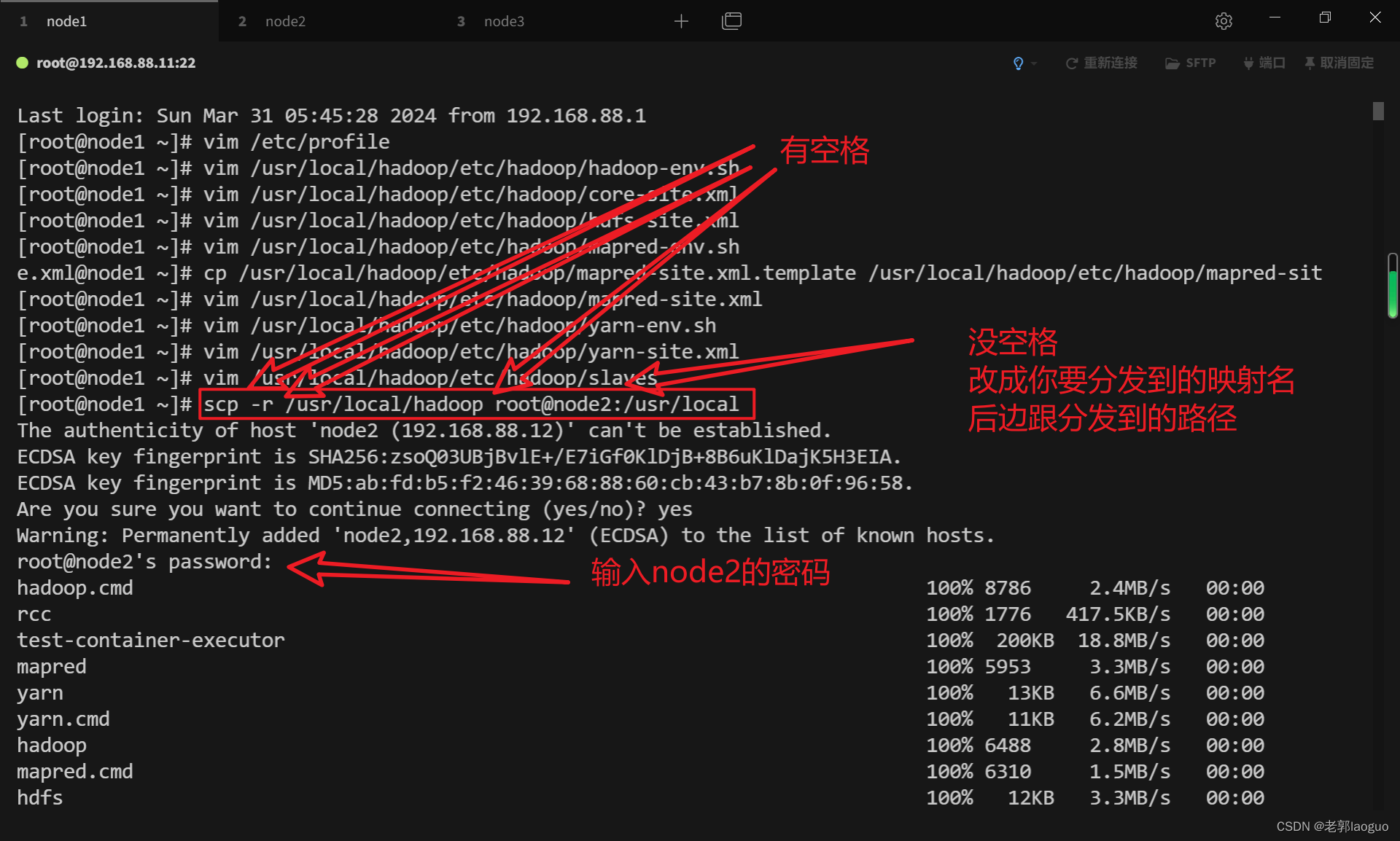
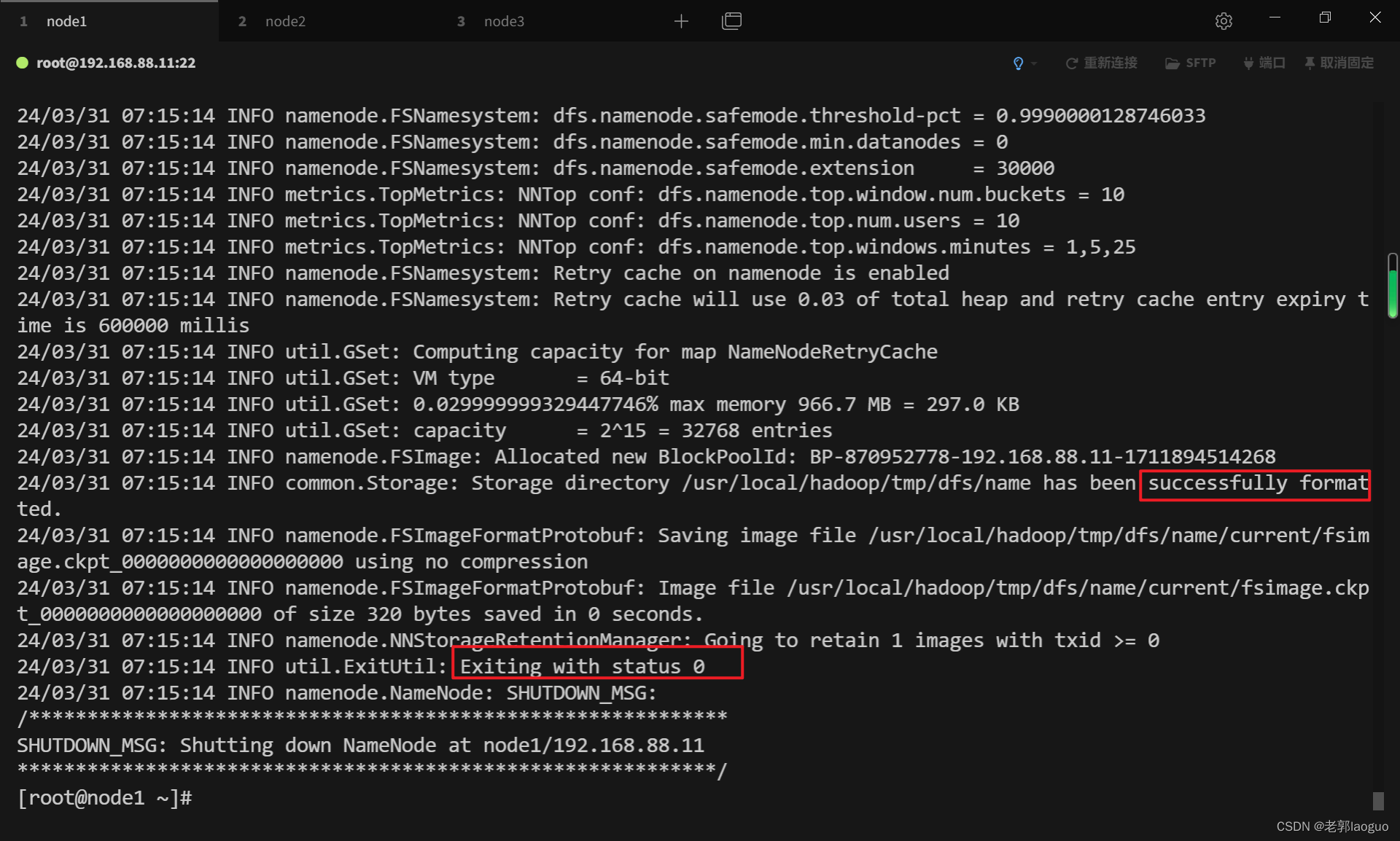
3.11格式化主机
只格式化主机node1,从机node2和node3不用格式化,格式化前可以打个快照保存一下,防止前面有地方配错了没查出来。
hadoop namenode -format

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
[外链图片转存中…(img-E1VtiC1E-1714702335485)]
[外链图片转存中…(img-kFEPDZva-1714702335486)]
[外链图片转存中…(img-1Kea6hZm-1714702335486)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1965
1965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









