








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
Packet是ClientCnxn的内部类,定义:
static class Packet {
RequestHeader requestHeader;
ReplyHeader replyHeader;
Record request;
Record response;
ByteBuffer bb;
String clientPath;
//server视角下的path,chroot不同
String serverPath;
boolean finished;
AsyncCallback cb;
Object ctx;
WatchRegistration watchRegistration;
public boolean readOnly;
WatchDeregistration watchDeregistration;
//并不是Packet中的所有字段都进行网络传输,在createBB方法中定义了用于网络传输的ByteBuffer bb字段的生成逻辑
//里面只用到了RequestHeader requestHeader,Record request,boolean readOnly 3个字段
public void createBB() {}
}
ClientCnxn的两个核心队列(都是Packet队列):
- outgoingQueue:客户端的请求发送队列,存储要发送到服务端的Packet集合
- pendingQueue:服务端响应的等待队列,存储已经从客户端发送到服务端但需要等待服务端响应的Packer集合
ClientCnxnSocket
ZK3.4之后ClientCnxnSocket从ClientCnxn中提取了出来,便于对底层Socket进行扩展(如使用Netty实现)
通过系统变量配合ClientCnxnSocket实现类的全类名:-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNIO
ClientCnxnSocketNIO是ClientCnxnSocket的Java NIO原生实现
会话Session
【分布式】Zookeeper会话 - leesf - 博客园
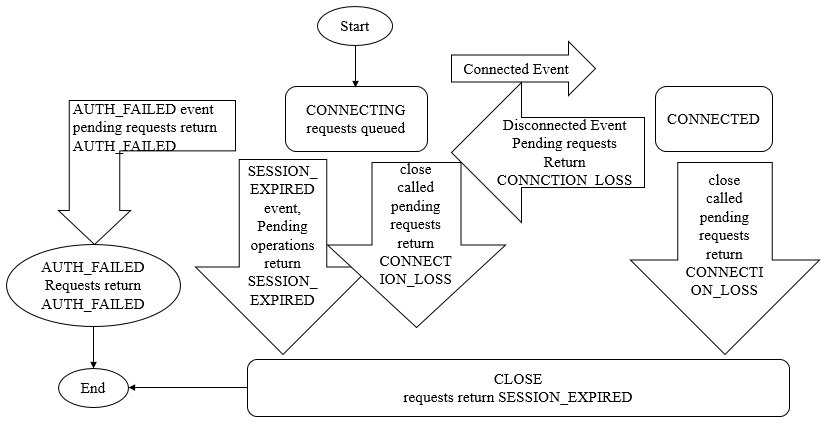
会话状态有:CONNECTING CONNECTED RECONNECTING RECONNECTED CLOSE
Session是ZK中的会话实体,代表一个客户端会话,包含以下4个基本属性:
- sessionID 唯一标识一个会话,每次客户端创建新会话时,ZK会为其分配一个全局唯一的sessionID
- timeout 会话超时时间,客户端构造ZK实例时会传入sessionTImeout指定会话的超时时间,客户端向服务器发送这个超时时间后,服务器会根据自己的超时限定确定会话的超时时间
- tickTime 下次会话超时时间点,这个参数用于会话管理的分桶策略执行。TickTIme是一个13位的long型(unix_timestamp)
- isClosing 服务端检测到一个会话失效后会标记其isClosing=true,这样就不再处理来自该会话的新请求了
sessionID的生成原理
代码位于 SessionTrackerImpl#initializeNextSession
//最终返回的sessionID:高8位是传入的id,剩下的56位最后16位被置零了,前面的40位是最高位截掉的timestamp(去掉数字1)
public static long initializeNextSessionId(long id) {
long nextSid;
// nanoTime/10^6 就是 currentTimeMillis 13位long型,long型占空间8B,共64位
//如 1657349408123 对应 44 位的二进制是 00011000000111110001101110010000010101111011
//左移24位后再右移8位后的结果:00000000(-8位)1000000111110001101110010000010101111011(16位-)0000000000000000
//注意这个右移8位是无符号右移,防止unixtimes第5位是1带来的负数问题
nextSid = (System.nanoTime() / 1000000 << 24) >>> 8;
//添加机器标识 sid 正好补在前面腾出的8位中
nextSid = nextSid | (id << 56);
if (nextSid == EphemeralType.CONTAINER_EPHEMERAL_OWNER) {
++nextSid; // this is an unlikely edge case, but check it just in case
}
return nextSid;
}
左移24位可以将高位的1去掉(unixTimestamp转二进制的44位数字开头总是0001),防止负数(负数右移8位后最高位的1不变),sid不能明确得出
SessionTracker
ZK服务端的会话管理器,负责会话的创建、管理和清理,使用3个数据结构管理Session:
- sessionsById:ConcurrentHashMap<Long, SessionImpl>类型,根据sessionID管理Session实体
- sessionsWithTimeout:ConcurrentMap<Long, Integer> 根据sessionID管理会话的超时时间,定期被持久化到快照文件中
- sessionSets:ExpiryQueue sessionExpiryQueue 服务于会话管理和超时检查,分桶策略会用到
Session管理 - 分桶策略
ZK的会话管理主要由SessionTracker负责,其采用了分桶策略:将理论上可以在同一时间点超时的会话放在同一区块中,便于进行会话的隔离处理和同一区块的统一管理。

对于一个会话的超时时间理论上就是客户端设置的超时时间之后,即图中的 ExpirationTime = CurrentTime + sessionTimeout(客户端进行设置),这样到达这个ExpirationTime检查各会话是否真的需要置超时状态
但是ZK服务端检查各区块的会话是否超时是有周期的,如每隔 ExpirationInterval 进行检查,这样实际的 ExpirationTime 是在原数值之后的最近一个周期上进行检查,这样
ExpirationTime_Adjust = ((CurrentTime + sessionTimeout) / ExpirationInterval + 1) * ExpirationInterval (单位均是ms)
如对于当前时间为4,,10 超时,检查周期为3,在15的时候才是第一个可能的超时时间。这样 ExpirationTime_Adjust 总是 ExpirationInterval 的整数倍。这样SessionTracker中的会话超时检查线程就可以在 ExpirationInterval 的整数倍的时间点上对会话进行批量清理(未及时移走的会话都是要被清理掉的,没有客户端触发会话激活)
会话激活
Leader服务器收到客户端的心跳消息PING后:
- 检查改会话是否是isClose
- 如果会话尚未关闭,则激活会话,计算出会话的下一次超时时间点 ExpirationTime_NEW
- 根据会话的旧超时时间点 ExpirationTime_Old 定位到会话所在的区块
- 迁移会话,将会话放入 ExpirationTime_NEW 对应的新区块中
触发会话激活的两种场景:
- 只要客户端向服务器发送请求(不论读/写)就会触发一次会话激活
- 客户端在sessionTimeout / 3 的时间间隔内没有向服务器发出任何请求,就会主动发起一次PING请求触发会话激活
会话清理的步骤
- 先将该会话的isClosing置为true,这样在会话清理期间再收到客户端的新请求就返回 Session_Expire,再标记会话状态为已关闭 - CLOSE
- 发起会话关闭 请求给 PrepRequestProcessor处理器进行处理
- 根据sessionID从内存数据库中找到对应的临时节点列表
- 将这些临时节点转换成 节点删除 请求,放入事务变更队列 outstandingChanges 中
- FinalRequestProcessor触发内存数据库,删除该会话对应的所有临时节点
- 节点删除后从SessionTracker中移除session(从sessionById sessionWithTimeout sessionExpiryQueue中移除对应session的信息)
- 从NIOServerCnxnFactory中找到会话对应的NIOServerCnxn进行关闭
重连机制
客户端与服务端网络连接断开时,ZK客户端会进行反复的重连
客户端经常看到的两种连接异常是:CONNECTION_LOSS 连接断开,SESSION_EXPIRE 会话过期;服务端可能看到的连接异常是SESSION_MOVED 会话转移
- CONNECTION_LOSS:客户端在发现连接断开时会逐个尝试连接 connectString 解析出的服务器地址,同时此时收到连接事件 None-Disconnected,同时抛出异常 KeeperException$ConnectionLossException,应用层应捕获住此异常并等待重连成功(收到None-SyncConnected事件)后进行重试
- SESSION_EXPIRE:通常发生在CONNECTION_LOSS,客户端重连成功后会话在服务端已过期被清理。应用层此时需要重新创建一个ZooKeeper实例进行初始化
- SESSION_MOVED:ZooKeeper在3.2.0版本后明确提出的概念,客户端 C 向服务端 S1发出的请求R1因网络抖动导致重连到S2,并重试请求R11,但后面R1成功到达S1,导致S1 S2 都执行了相同的请求。针对这一罕见场景,ZooKeeper提出的处理方案: 在处理客户端请求时检查此会话Owner是不是当前服务器,不是的话会抛出 SessionMovedException 异常,但C1因为已断开与S1的连接,看不到S1上的这个异常。在多个客户端使用相同的sessionId/pass连接不同服务端时才会看到这种异常
ZK服务端
ZK服务端架构
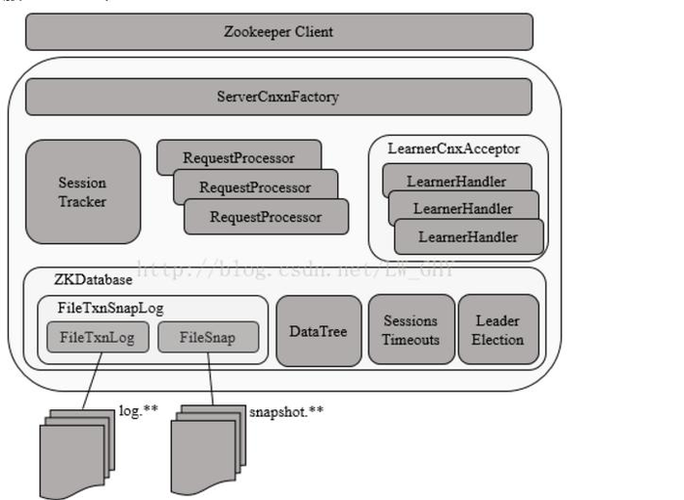
单机版ZK服务器的启动流程
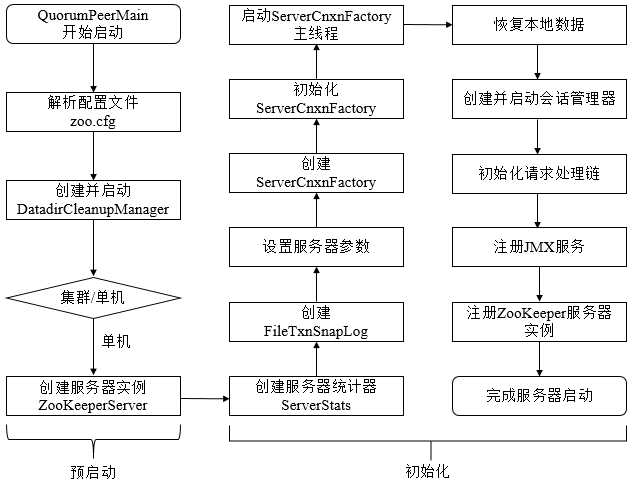
预启动
- 不论是单机还是集群模式,zkServer.cmd和zkServer.sh两个脚本中都配置了使用QuorumPeerMain 作为启动入口类
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain" - 解析配置文件 zoo.cfg
- 在QuorumPeerMain#initializeAndRun方法中创建并启动了文件清理器 DatadirCleanupManager,包括对事物日志和快照数据文件的定时清理
- 根据zoo.cfg配置文件的解析判断当前是单机还是集群模式启动,单机模式使用ZooKeeperServerMain启动
- 创建ZooKeeperServer实例并进行初始化,包括连接器、内存数据库和请求处理器等组件的初始化
初始化
-
创建服务器统计器ServerStats,包含下述基本运行时信息:
- packetsSent: 从服务启动或重置以来,服务端向客户端发送的响应包次数
- packetsReceived: … 服务端接收到的来自客户端的请求包次数
- maxLatency/minLatency/totalLatency: 服务端请求处理的最大延时、最小延时、总延时
- count: 服务端处理的客户端请求总次数
-
创建ZK数据管理器FileTxnSnapLog:FileTxnSnapLog是ZK上层服务器和底层数据存储之间的对接层,提供了一些列操作数据文件的接口,包括事务日志文件(TxnLog接口)和快照数据文件(SnapShot接口)。ZK根据zoo.cfg文件中解析出的快照数据目录dataDir和事务日志目录dataLogDir来创建FileTxnSnapLog。
-
设置服务端 tickTime 和 会话超时时间 限制
-
创建并初始化 ServerCnxnFactory , 通过属性 zookeeper.serverCnxnFactory 指定zookeeper使用 Java原生NIO还是Netty框架作为ZooKeeper服务端网络连接工厂
-
启动ServerCnxnFactory主线程(执行主逻辑所在的run方法)此时ZK的NIO服务器已经对外开放了端口,客户端可以访问到2181端口,但此时zk服务器还无法正常处理客户端请求
-
恢复本地数据:ZK启动时都会从本地快照文件和事务日志文件中进行数据恢复
-
创建并启动会话管理器SessionTracker,同时会设置 expirationInterval 计算 nextExpirationTime、sessionID ,初始化本地数据结构 sessionsWithTimeout(保存每个会话的超时时间)。之后ZK就会开始会话管理器的会话超时检查
-
初始化ZK的请求处理链,ZK服务端对于请求的初始方式是典型的责任链模式,单机版服务器的处理链主要包括:PrepRequestProcessor -> SyncRequestProcessor ->FinalRequestProcessor
-
注册JMX服务:ZK会将服务器运行时的一些状态信息以JMX的方式暴露出来
-
注册ZK服务器实例:此时ZK服务器初始化完毕,注册到ServerCnxnFactory之后就可以对外提供服务了,至此单机版的ZK服务器启动完毕
集群版ZK服务器的启动过程

预启动过程与单机版一致
初始化
- 创建并初始化 ServerCnxnFactory
- 创建ZooKeeper数据管理器 FileTxnSnapLog
- 创建QuorumPeer 实例:Quorum是集群模式下特有的对象,是ZooKeeper服务器实例ZooKeeperServer的托管者。从集群层面看QuorumPeer代表了ZooKeeper集群中的一台机器。在运行期间,Quorum会不断检测当前服务器实例的运行状态,同时根据情况发起Leader选举
- 创建内存数据库 ZKDatabase,管理ZooKeeper的所有会话记录以及DataTree 和事务日志的存储
- 初始化 QuorumPeer,将一些核心组件注册到QuorumPeer,包括 FileTxnSnapLog、ServerCnxnFactory、ZKDatabase,同时配置一些参数,包括服务器地址列表、Leader选举算法和会话超时时间限制等
- 恢复本地数据
- 启动 ServerCnxnFactory 主线程
Leader选举
- Leader选举初始化阶段:Leader选举是集群版启动流程与单机版最大的不同,ZK会根据SID(服务器分配的ID)、lastLoggedZxid(最新的ZXID)和当前的服务器epoch(currentEpoch)生成一个初始化的投票,初始化过程中每个服务器会为自己投票。 ZooKeeper会根据zoo.cfg中的配置(electionAlg),创建响应的Leader选举算法实现,3.4.0之前支持 LeaderElection\AuthFastLeaderElection\FastLeaderElection 三种算法实现,3.4.0之后只支持FastLeaderElection。 在初始化阶段,ZooKeeper会首先创建Leader选举所需的网络IO层 QuorumCnxManager,同时启动对Leader选举端口的监听,等待集群中的其他服务器创建连接
- 注册JMX服务
- 检测当前服务器状态:QuorumPeer不断检测当前服务器的状态做出相应的处理,正常情况下,ZK服务器的状态在LOOKING、LEADING和FOLLOWING/OBSERVING之间进行切换,。启动阶段QuorumPeer的状态是LOOKING,因此开始进行Leader选举
- Leader选举:投票选举产生Leader服务器,其他机器成为Follower或是Observer; Leader选举算法的原则:集群中的数据越新(根据每个服务器处理过的最大ZXID来确定数据是否比较新)越有可能成为Leader,ZXID相同时SID越大越有可能成为Leader。
Leader和Follower服务器启动期交互过程

- 完成Leader选举后,每个服务器根据自己的角色创建相应服务器实例,并开始进入各自角色主流程
- Leader服务器启动Follower接收器LearnerCnxAcceptor,负责接收所有非Leader服务器的连接请求
- Learner服务器根据投票选举结果找到当前集群中的Leader服务器,与其建立连接
- Leader接收来自其他机器的连接创建请求后,创建一个LearnerHandler实例。每个LearnerHandler实例都对应了一个Leader与Learner的服务器之间的连接,负责消息、数据同步
- Learner向Leader发起注册:将含有当前服务器SID和服务器处理的最新ZXID信息的LearnerInfo发送给Leader服务器
- Leader接收到注册信息后解析出SID和ZXID,根据ZXID解析出Learner对应的epoch_of_learner_parse,与自己的epoch_of_leader_self进行比较,如果epoch_of_learner_parse>epoch_of_leader_self,则更新 epoch_of_leader_self=epoch_of_learner_parse+1。LearnerHandler会进行等待,直到过半的Learner向Leader注册完毕,同时更新 epoch_of_leader 之后,Leader就可以确定当前集群的epoch
- Leader将最终的epoch以LEADERINFO消息的形式发送给Learner,同时等待Learner的响应
- Follower从LEADERINFO消息中解析出epoch和ZXID向Leader返回ACKEPOCH响应
- Leader收到反馈响应ACKEPOCH后与Follower进行数据同步
- 如果过半的Learner完成了数据同步,就启动Leader和Learner服务器实例
Leader和Follower启动
接上面步骤10,启动步骤如下:
- 创建并启动会话管理器
- 初始化ZooKeeper的请求处理链:根据服务器角色的不同生成不同的请求处理链
- 注册JMX服务
至此,集群版的ZK服务器启动完毕
Leader选举过程
Leader选举是ZooKeeper中最重要的技术之一,也是保证分布式数据一致性的关键
服务器启动时期的Leader选举
以3台机器组成的集群为例:Server1首先启动,此时无法完成Leader选举
-
Server2启动后,与Server1进行Leader选举,由于是初始化阶段,都会投票给自己,于是Server1投票内容 (myid, ZXID) 为 (1,0),Server2投票 (2,0),各自将这个投票发送给集群中的其他所有机器
-
每个服务器接收来自其他各服务器的投票,并判断投票的有效性:检查是否是本轮投票,是否来自LOOKING状态的服务器
-
收到其他服务器的投票后与自己的投票进行PK,PK规则有:
- 优先检查ZXID,ZXID较大的服务器优先作为Leader
- ZXID相同时比较myid,myid较大的作为Leader
此时Server1收到Server2的投票(2,0),ZXID相同,但myid较小,会更新自己的投票为 (2,0) 并发出。Server2发现自己的myid较大,无需更新投票信息,只是再次向集群中所有机器发出上一次投票信息
- 统计投票:每次投票后服务器会统计所有投票,判断是否有过半(> n/2 + 1)的机器接收到相同的投票信息来决定Leader服务器 此时3台服务器已有 2台(Server1 Server2)达成一致,超过半数,将选举出Leader - Server2
- 改变服务器状态:确定了Leader后服务器需要更新自己的状态,Follower变更为FOLLOWING,Leader会变更为 LEADING 状态
服务器运行期间的Leader选举
Leader服务器宕机后进入新一轮的Leader选举
- 变更状态:Leader宕机后剩下的非Observer服务器都会将自己的状态变更为LOOKING,开始进入Leader选举流程
- 每个Server发出一个投票:生成投票信息(myid, ZXID)在第一轮投票中,每个服务器都会投自己,后续的判断过程与服务器启动时期的Leader选举相同
Leader选举算法 - FastLeaderElection
ZooKeeper提供了3种Leader选举算法:LeaderElection、UDP版本的FastLeaderElection、TCP版本的FastLeaderElection。
术语解释:
SID - 服务器ID,唯一标识ZooKeeper集群中的机器的数字,与myid一致
ZXID - 事务ID,用于唯一标识一次服务器状态的变更,某一时刻,集群中的每台服务器的ZXID不一定完全一致
Vote - 投票
Quorum - 过半机器数,quorum = n/2 + 1
ZooKeeper集群中服务器出现下述两种情况之一就会进入Leader选举:集群初始化启动阶段;Leader宕机/断网
而一台机器进入Leader选举流程时,当前集群也可能会处于两种状态:
- 集群中本来就存在Leader,此时试图发起选举会被告知当前服务器的Leader信息,直接与Leader建立连接并同步状态
- 集群中不存在Leader:所有机器进入LOOKING状态进行投票选举Leader
【选举案例】集群有5台机器,SID分别为 1 2 3 4 5,ZXID分别为 9 9 9 8 8,在某一时刻SID为 1 2 的机器宕机退出,集群此时开始进行Leader选举
第一次投票时,由于还无法检测到集群中其他机器的状态信息,每台机器都将投自己,于是SID为 3 4 5的机器分别投票(SID,ZXID) (3,9) (4,8) (5,8)
每台机器发出自己的投票后也会收到来自集群中其他机器的投票,每台机器都会对比收到的投票,决定是否替换。假设机器自己的投票是 (self_sid, self_zxid) 接收到的投票是 (vote_sid, vote_zxid),对比的规则是:
- 如果 vote_zxid > self_zxid 则认可当前投票,并再次将更新后的投票发送出去
- 如果 vote_zxid < self_zxid 则不作变更
- 如果 vote_zxid = self_zxid && vote_sid > self_sid,就认可当前接收到的投票,并改为 (vote_sid, vote_zxid) 投递出去
- 如果 vote_zxid = self_zxid && vote_sid < self_sid,则不作变更
SID为 3 4 5的机器对投票进行对比,会统一更新为投票 (3,9) ,此时quorum = 3 >= (5/2 + 1) 超过半数,选举服务器3作为Leader
ZXID越大的机器,数据也就越新,这样可以保证数据的恢复(更少的数据丢失),所以适合作为Leader服务器
Leader选举的实现细节
在QuorumPeer.ServerState 类中定义了4种服务器状态
public enum ServerState {
LOOKING, // 寻找Leader状态,当前集群中没有Leader,需要进入Leader选举流程
FOLLOWING, // 当前服务器的角色是Follower
LEADING, // 当前服务器角色是Leader
OBSERVING // 当前服务器角色是 Observer
}
org.apache.zookeeper.server.quorum.Vote 数据结构的定义
public class Vote {
private final int version;
private final long id; // 选举的Leader的SID
private final long zxid;
//逻辑时钟,用于判断多个投票是否在同一轮选举周期中。该值在服务端是一个自增序列,每次进入新一轮投票后,都会对该值+1
private final long electionEpoch;// 被推举的Leader的epoch
private final long peerEpoch;//当前服务器的状态
QuorumCnxManager 网络IO
每个服务器启动时会启动一个QuorumCnxManager,负责各服务器的底层Leader选举过程中的网络通信。
QuorumCnxManager内部维护了一系列按SID分组的消息队列:
recvQueue:消息接收队列,存放从其他服务器接收到的消息
queueSendMap:消息发送队列,保存待发送的消息。此Map的key是SID,分别为集群中的每台机器分配了一个单独队列,从而保证各台机器之间的消息发送互不影响
senderWorkerMap:发送器集合,同样按SID分组,每个SenderWorker消息发送器对应一台远程ZooKeeper服务器
lastMessageSent:最近发送过的消息,为每个SID记录最近发送过的消息
选举时集群中的机器是如何建立连接的:
为了能够进行互相投票,ZooKeeper集群中的机器需要两两建立网络连接。
QuorumCnxManager启动时会创建一个ServerSocket监听Leader选举的通信端口(默认3888),接收其他服务器的TCP连接请求并交给receiveConnection函数来处理。为了避免两台机器之间重复创建TCP连接,ZooKeeper设计一种建立TCP连接的规则:只允许SID大的服务器主动和其他服务器建立连接,否则断开连接。如果服务器收到TCP连接请求发现比自己的SID值小,会断开这个连接并主动与发起连接的远程服务器建立连接。
建立连接后就会根据外部服务器的SID创建对应的消息发送器 SendWorker 和 消息接收器RecvWorker 并启动
FastLeaderElection选举算法的核心
ZooKeeper对于选票的管理
- sendqueue:选票发送队列,保存待发送的选票
- recvqueue:选票接收队列,保存接收到的外部选票
- FastLeaderElection.Messenger.WorkerReceiver:选票接收器,不断从QuorumCnxManager中取出其他服务器发出的选举消息,并转成Vote,保存到recvqueueu。如果接收到的外部投票选举轮次小于当前服务器(validVoter方法返回false),直接忽略改选票同时发出自己的投票。如果当前的服务器并不是LOOKING状态(if (self.getPeerState() == QuorumPeer.ServerState.LOOKING)),就将Leader信息以投票的形式发出。 选票接收器接收到的消息如果来自Observer就会忽略该消息,并将自己当前的投票发送出去
- WorkerSender 选票发送器,会不断从sendqueue队列中获取待发送的选票,并将其传递到底层QuorumCnxManager中
FastLeaderElection#lookForLeader方法中揭示了选举算法的流程,该方法在服务器状态变成LOOKING时触发
选举算法流程
-
自增选举轮次 logicalclock ++ FastLeaderElection中的 AtomicLong logicalclock 字段标记当前Leader的选举轮次,ZooKeeper在开始新一轮投票时,会首先对logicalclock进行自增操作
-
初始化选票 初始化选票Vote的属性:将自己推荐为Leader(id=服务器自身SID,zxid=当前服务器最新ZXID,electionEpoch=当前服务器的选举轮次,peerEpoch=被推举的服务器的选举轮次,state=LOOKING)
-
将初始化好的选票放入sendqueue中,由WorkerSender负责发出
-
服务器不断从 recvqueue 接收外部投票,如果服务器发现无法获取到任何投票会检查与其他服务器的连接,修复连接后重新发出
-
处理外部投票,根据选举轮次判断进行不同的处理:
- 外部投票选举轮次 > 内部轮次:立即更新自己的选举轮次logicalclock,清空所有已收到的投票,使用初始化的投票进行PK以确定是否变更内部投票,最终将内部投票发送出去
- 外部投票选举轮次 < 内部轮次:忽略外部投票,返回步骤4
- 两边一致,绝大多数场景,选举轮次一致时开始进行选票PK
-
选票PK:收到其他服务器有效的外部投票后,进行选票PK,执行FastLeaderElection.totalOrderPredicate方法,选票PK的目的是确定当前服务器是否需要变更投票,主要从 logicalclock、ZXID、SID三个维度判断,符合下述任意一个条件就进行投票变更:
- 外部投票推举的Leader服务器的 logicalclock > 内部投票的,需要进行内部投票变更
- logicalclock一致的,对比两者的ZXID,外部投票ZXID > 内部的,进行内部投票变更
- 两者的ZXID一致就对比SID,外部的大就进行投票变更
-
变更投票:如果需要变更投票就使用外部投票的选票信息覆盖内部投票,变更完成后再将这个变更后的内部投票发出去
-
选票归档:无论是否进行了投票变更,外部投票都会存入recvset中进行归档,recvset中按照服务器对应的SID来区分{(1,vote1),(2,vote2),…}
-
统计投票:统计集群中是否已经有过半的机器认可了当前的内部投票,否则返回步骤4
-
更新服务器状态:如果此时已经确定可以终止投票,就更新服务器状态:根据过半机器认可的投票对应的服务器是否是自己确定是否成为Leader,并将状态切换为LEADING/FOLLOWING/OBSERVING
上述10个步骤就是FastLeaderElection的选举流程,步骤4~9会经过几轮循环,直到Leader选举产生。在步骤9如果已经有过半服务器认可了当前选票,此时ZooKeeper并不会立即进入步骤10,而是等待一段时间(默认200ms)来确定是否有新的更优的投票。
服务器角色介绍
Leader
工作内容:事务请求的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各服务器的调度者;
ZooKeeper使用责任链模式来处理客户端请求

-
PrepRequestProcessor是Leader服务器的请求预处理器,在ZK中,将创建删除节点/更新数据/创建会话等会改变服务器状态的请求称为事务请求,对于事务请求,预处理器会进行一系列预处理,如创建请求事务头、事务体、会话检查、ACL检查和版本检查
-
ProposalRequestProcessor Leader的事务投票处理器,也是Leader服务器事务处理流程的发起者。
- 对于非事务请求:直接将请求流转到CommitProcessor,不作其他处理
- 对于事务请求:除了交给CommitProcessor,还会根据对应请求类型创建对应的Proposal,并发送给所有Follower服务器发起一次集群内的事务投票。ProposalRequestProcessor还会将事务请求交给SyncRequestProcessor进行事务日志的记录
-
SyncRequestProcessor 事务日志处理器,将事务请求记录到事务日志文件中,触发ZooKeeper进行数据快照
-
AckRequestProcessor 是Leader特有的处理器,负责在SyncRequestProcessor处理器完成事务日志记录后向Proposal的投票收集器发送ACK反馈,通知投票收集器当前服务器已完成对该Proposal的事务日志记录
-
CommitProcessor 事务提交处理器
-
ToBeCommitProcessor 该处理类中有一个toBeApplied队列(ConcurrentLinkedQueue toBeApplied)存储被CommitProcessor处理过的可被提交的Proposal,等待FinalRequestProcessor处理完提交的请求后从队列中移除
-
FinalRequestProcessor 进行客户端请求返回前的收尾工作:创建客户端请求的响应、将事务应用到内存数据库
LearnerHandler:Leader服务器会与每一个Follower/Observer服务器建立一个TCP长链接,同时为每个Follower/Observer服务器创建LearnerHandler。LearnerHandler是ZK集群中的Learner服务器的管理器,负责Follower/Observer服务器和Leader服务器之间的网络通信:数据同步、请求转发、Proposal提议的投票。
Follower
Follower的职责:处理客户端非事务请求,转发事务请求给Leader服务器;参与事务请求Proposal的投票;参与Leader选举投票;
Follower不需要负责事务请求的投票处理(所以不需要ProposalRequestProcessor),所以其请求处理链简单一些

- FollowerRequestProcessor 识别出当前请求是否是事务请求,如果是事务请求,Follower就会将请求转发给Leader服务器,Leader服务器收到请求后提交给请求处理器链,按正常事务请求进行处理
- SendAckRequestProcessor Follower服务器上另一个和Leader服务器有差异的请求处理器,与Leader服务器上的AckRequestProcessor类似,SendAckRequestProcessor同样承担了事务日志记录反馈的角色,在完成事务日志记录后,会向Leader服务器发送ACK消息表明自身完成了事务日志的记录工作。两者的一个区别是:AckRequestProcessor在Leader服务器上,因此ACK反馈是一个本地操作,而SendAckRequestProcessor在Follower上,需要通过ACK消息的形式向Leader服务器进行反馈。
Observer
观察ZooKeeper集群的最新状态并将这些状态变更同步过来,Observer服务器在工作原理上与Follower基本一致,对于非事务请求可以进行独立的处理,对于事务请求同样需要转发到Leader服。与Follower的一大区别是:Observer不参与任何形式的投票,包括Leader选举和事务请求Proposal的投票。
集群内消息通信
ZK集群各服务器间消息类型分为4类:数据同步型、服务器初始化型、请求处理型、会话管理型
数据同步消息
Learner与Leader进行数据同步使用的消息,分为4种(消息类型定义在Leader.java中,使用常量数字标记):
- DIFF, 13 Leader发送给Learner,通知Learner进行DIFF方式的数据同步
- TRUNC, 14 Leader --> Learner 触发Learner服务器进行内存数据库的回滚操作
- SNAP, 15 Leader --> Learner 通知Learner,Leader即将与其进行全量数据同步
- UPTODATE, 12 Leader --> Learner 通知Learner完成了数据同步,可以对外提供服务
服务器初始化型消息
整个集群或某些机器初始化时,Leader与Learner之间相互通信所使用的消息类型:
- OBSERVERINFO,16: Observer在启动时发送消息给Leader,用于向Leader注册Observer身份,消息中包含当前Observer服务器的SID和已经处理的最新ZXID
- FOLLOWERINFO,11:Follower启动时发送包含SID和已处理的最新ZXID的注册消息到Leader
- LEADERINFO,17:上述两种情形下,Leader服务器会返回包含最新EPOCH值的LeaderInfo返回给Observer或Follower
- ACKEPOCH,18:Learner在收到LEADERINFO消息时会将自己的最新ZXID和EPOCH以ACKEPOCH消息的形式发送给Leader
- NEWLEADER,10:足够多的Follower连接上Leader服务器,或是Leader服务器完成数据同步后,Leader向Learner发送的阶段性标识信息,包含当前最新ZXID
请求处理型
请求处理过程中Leader和Learner之间互相通信所使用的消息:
- REQUEST,1:Learner收到事务请求时需要将请求转发给Leader,该请求使用REQUEST消息的形式进行转发
- PROPOSAL,2:在处理事务请求时,Leader服务器会将事务请求以PROPOSAL消息的形式创建投票发送给集群中的所有的Follower进行事务日志的记录
- ACK,3:Follower完成事务日志的记录后会以ACK消息的形式反馈给Leader
- COMMIT,4:Leader通知集群中的所有Follower,可以进行事务请求的提交了,Leader在收到过半Follower发来的ACK消息后,进入事务请求的最终提交流程——生成COMMIT消息,告知所有Follower进行事务请求的提交,这是一个2PC的过程
- INFORM,8:Leader发起事务投票并通知提交事务,只需要PROPOSAL和COMMIT消息给Follower就可以了,而Observer不参与事务投票,无法接收COMMIT消息,但需要知道事务提交的内容,所以ZK设计了INFORM消息发给Observer,消息中会携带事务请求的内容
- SYNC,7:Leader通知Learner服务器已完成Sync操作
会话管理型
ZK服务器在进行会话管理过程中,与Learner服务器之间通信所使用的消息:
- PING,5:ZK客户端随机选择一个服务器进行连接,所以Leader服务器无法直接收到所有客户端的心跳检测,所以需要委托Learner维护所有客户端的心跳检测。Leader定时向Learner发送PING消息就是要求Learner将一段时间内保持心跳检测的客户端列表同样以PING消息的形式返回给Leader,这样Leader就能获取到全部客户端的活跃状态并进行会话激活了。
- REVALIDATE,6:客户端发生重连后(可能切换了服务器)新连接的服务器需要向Leader发送REVALIDATE消息以确定客户端会话是否已经超时。
客户端请求的处理
会话创建请求
ZK服务端对于会话创建的处理,可以分为请求接收、会话创建、预处理、事务处理、事务应用和会话响应。
zookeeper源码分析(3)— 一次会话的创建过程 - 简书— 一次会话的创建过程 - 简书")

请求接收
- IO层接收来自客户端的请求,NIOServerCnxn实例维护每一个客户端连接,负责客户端与服务端通信,并将请求内容从底层网络IO中读取出来
- 判断是否是客户端“会话创建”请求:检查当前请求对应的NIOServerCnxn实体是否已经初始化,未初始化时第一个请求必定是会话创建请求
- 反序列化ConnectRequest请求,确定是会话创建请求后就可以反序列化得到一个ConnectRequest请求实体
- 判断是否是ReadOnly客户端,如果ZK服务器是以ReadOnly模式启动,所有来自非ReadOnly型客户端的请求将无法处理。所以服务端需要从ConnectRequest中检查是否是ReadOnly客户端,以此来决定是否接受此“会话创建”请求
- 检查客户端ZXID:出现客户端ZXID比服务端还大这种反常情形时,服务端不接受此会话创建请求
- 协商sessionTimeout:客户端有自己设置的sessionTimeout值,传到服务端后,服务端要根据自身配置进行检查限定,通常的规则是 2 * ticketTime ~ 20 * tickerTime 之间
- 判断是否需要重新创建会话:解析客户端传入的sessionID进行判断
会话创建
- 为客户端生成sessionID:每个ZK服务器启动时都会初始化一个会话管理器SessionTracker,同时初始化一个基准sessionID,这个基准sessionID的生成需要保证后续客户端在此基础上不断+1能够全局唯一。sessionID生成算法见客户端介绍:会话Session > sesssionID的生成原理。
- 注册会话:将会话信息保存到SessionTracker的本地字段中:ConcurrentHashMap<Long, SessionImpl> sessionsById、ConcurrentMap<Long, Integer> sessionsWithTimeout
- 会话激活:服务端根据配置的ticketTime和会话超时时间比对计算下一次会话超时时间(使用了分桶策略)sessionsWithTimeout
- 生成会话密码:随机数,生成代码见 ZooKeeperServer#generatePasswd
预处理
- PrepRequestProcessor处理请求(责任链模式)
- 创建请求事务头:对于事务请求,ZK会为其创建请求事务头,后续请求处理器都是基于该请求头标识当前请求是否是事务请求,请求事务头包含:clientId(唯一标识请求所属客户端)cxid(客户端操作序列号)zxid(事务请求对应的zxid)time(服务端开始处理事务请求的时间)type(事务请求的类型:ZooDefs.OpCode.create、delete、setData和createSession等)
- 创建请求事务体CreateSessionTxn
- 注册与激活会话:额外处理非Leader转发的会话创建请求
事务处理

-
ProposalRequestProcessor处理请求:PrepRequestProcessor将请求交给下一级处理器,提案Proposal是ZK中对因事务请求展开的投票流程中的事务操作的包装,该处理器就是处理提案的,处理流程有:
-
Sync流程:SyncRequestProcessor处理器记录事务日志。完成事务日志记录后,每个Follower都会向Leader发送ACK消息,表明自身完成了事务日志的记录,以便Leader服务器统计每个事务请求的投票情况
-
Proposal流程:ZK的实现中,每个事务请求都需要集群中过半机器投票认可才能真正应用到ZK的内存数据库中,这个投票与统计的过程就叫 Proposal流程:
- 发起投票:对于事务请求,Leader服务器会发起一轮事务投票,发起事务投票之前会检查服务端ZXID是否可用,如果不可用会抛出XidRolloverException
- 生成提议Proposal:如果服务端ZXID可用,就可以开始事务投票了,ZK会将之前创建的请求头和事务体,以及ZXID和请求本身序列化到Proposal对象中
- 广播提议:Leader服务器会以ZXID作为key,将提议放入投票箱ConcurrentMap<Long, Proposal> outstandingProposals中,同时将该提议广播给所有Follower服务器
- 收集投票:Follower服务器接收到Leader发来的提议后,会进入Sync流程进行事务日志的记录,执行完后发送ACK消息给Leader,Leader根据ACK消息统计Proposal的投票情况。当过半机器通过时,就进入Proposal的Commit阶段
- Commit Proposal前将请求放入 toBeApplied 队列中
- 广播COMMIT消息:Leader会向Observer广播包含Proposal内容的INFORM消息,而对于Follower服务器则需只发送ZXID(上文有介绍)
-
Commit流程:
- 将请求交给CommitProcessor.java处理器,放入 LinkedBlockingQueue queuedRequests 中,独立线程会取出处理
- 标记topPending:如果是事务请求(write类型),就会将topPending标记为当前请求,用于确保事务请求的顺序性,便于CommitProcessor检测当前集群中是否正在进行事务请求的投票
- 等待Proposal投票:Commit流程处理时,Leader根据当前事务请求生成Proposal广播给所有Follower,此时Commit流程需要等待
- 投票通过,提议获得过半机器认可,ZK会将请求放入committedRequests队列中,同时唤醒Commit流程
- 提交请求:将请求放入toProcess队列中,交给FinalRequestProcessor处理
-
事务应用
- FinalRequestProcessor检查outstandingChanges队列中请求的有效性,如果队列中的请求落后于当前正在处理的请求,则从队列中移除
- 之前的请求处理逻辑中仅仅是将事务请求记录到了事务日志中,内存数据库中的状态尚未变更。因此需要将事务变更应用到内存数据库中。对于会话创建这种“事务请求”,只需向SessionTracker进行会话注册
- 完成内容应用后将事务请求放入队列 commitProposal,这个队列保存最近被提交的事务请求,以便集群间机器进行数据的快速同步
会话响应
此时客户端请求在ZK服务端已经完成了所有链路的处理
- 统计处理:计算请求在服务器端处理所花费的时间,统计客户端连接的一些基本信息:lastZxid-最新的ZXID;lastOp-最后一次和服务端的操作;lastLatency-最后一次请求处理所花费的时间;
- 创建响应ConnectResponse 会话创建成功后的响应,包含:当前客户端与服务端之间的通信协议版本号;会话超时时间;sessionID;会话密码;
- 序列化 ConnectResponse
- IO层发送响应给客户端
SetData请求的处理

预处理
- IO层接收来自客户端的请求
- 判断是否是客户端会话创建类请求,setData请求到来时已完成了会话创建
- PrepRequestProcessor处理器进行处理
- 创建请求事务头
- 检查会话是否超时,超时向客户端抛出SessionExpiredException
- 反序列化请求,创建ChangeRecord记录。ZK对于客户端请求,反序列化生成特定SetDataRequest请求,请求中包含数据节点path、更新数据内容data、期望的数据节点版本version。
- ACL权限检查,没有权限会抛出NoAuthException
- 数据版本检查(乐观锁)
- 创建事务请求体SetDataTxn
- 保存事务操作到outstandingChanges队列中
事务处理:无论对于会话创建还是SetData请求,事务处理流程都是一致的:由ProposalRequestProcessor处理器发起,通过Sync、Proposal、Commit 3个子流程相互协作完成
事务应用
- FinalRequestProcessor处理
- ZK将请求事务头和事务体交给内存数据库 ZKDatabase进行事务应用,返回ProcessTxnResult,包含了数据节点内容更新后的stat
- 将事务请求放入 commitProposal 队列
请求响应
- 统计处理
- 创建响应体SetDataResponse,包含当前数据节点的最新状态stat
- 创建响应头,方便客户端对响应进行解析,包括当前响应对应的事务ZXID和请求处理是否成功的标识err
- 序列化响应
- IO层发送响应给客户端
事务请求转发
所有非Leader服务器如果收到了来自客户端的事务请求,必须将其转发给Leader服务器处理。Follower或Observer服务器中,第一个请求处理器分别是FollowerRequestProcessor和ObserverRequestProcessor,都会检查当前请求是否是事务请求,对于事务请求会议REQUEST消息的形式转发给Leader,Leader解析出原始请求后提交到自己的请求处理链中。
GetData请求

预处理:
IO层接收来自客户端的请求;判断是否是客户端会话创建请求;PrepRequestProcessor处理;会话检查;
由于GetData请求是非事务请求,因此不需要事务预处理逻辑:创建请求事务头、ChangeRecord、事务体、数据节点版本的检查;
非事务处理:
反序列化GetDataReqeuest(得到path和watcher注册情况);获取数据节点(ZK从内存数据库中获取节点及ACL信息);ACL检查;获取数据内容和stat,注册watcher;
请求响应:
创建响应体GetDataResponse,获取数据成功后的响应,包含当前数据节点内容和状态stat;创建响应头;统计处理;序列化响应;IO层发送响应给客户端;
ZK底层数据与存储
内存数据库存储了ZK树结构的数据,包括节点路径、节点数据和ACL信息,ZK会定时将这些数据存储到磁盘上
DataTree类
org.apache.zookeeper.server.DataTree维护了树形结构数据,内部没有任何网络或客户端连接逻辑,所以可以单独进行调试。
DataNode是数据存储的最小单元,内含数据节点内容 byte[] data、ACL列表对应的map key Long acl、节点状态对象StatPersisted stat、子节点列表Set children、父节点parent的引用?
DataTree维护了两个数据结构:path与DataNode组成的ConcurrentHashMap<String, DataNode> nodes、DataNode树;
另外为方便及时访问和清理临时节点,额外维护字段 Map<Long, HashSet> ephemerals = new ConcurrentHashMap<Long, HashSet>()
ZKDatabase
ZooKeeper的内存数据库,管理ZK的所有会话、DataTree存储和事务日志。ZKDatabase会定时向磁盘dump快照数据,ZK服务器启动时会通过磁盘上的事务日志和快照文件进行恢复
事务日志
zoo.cfg配置文件中的dataDir目录默认用于存储事务日志文件,dataLogDir可以配置为事务日志单独分配一个文件存储目录。
如果配置了 dataLogDir = /home/admin/zkData/zk_log,ZK运行时会在该目录下创建 version-2 子目录,该目录的命名跟随ZK的事务日志版本号。这样运行一段时间后在 /home/admin/zkData/zk_log/version-2 出现了日志文件
-rw-rw-r-- 1 admin admin 67108880 02-23 16:10 log.2c01631713
-rw-rw-r-- 1 admin admin 67108880 02-23 17:07 log.2c0164334d
-rw-rw-r-- 1 admin admin 67108880 02-23 18:19 log.2d01654af8
-rw-rw-r-- 1 admin admin 67108880 02-23 19:28 log.2d0166a224
- 这些日志文件大小固定都是64MB
- 文件后缀名是十六进制数字,即ZXID - 64位数字,前32位表示ecpoch,这些日志文件只有两个epoch:2c、2d;后32位是操作序列号。每个日志文件达到设定的大小后,创建新日志文件并以当时的ZXID为文件名,这样方便根据日志文件后缀名寻找ZXID的存储位置
- 事务日志文件内容的解析命令
java LogFormatter log.2d0166a224
# 事务日志文件头信息,输出事务日志的DBID和日志版本号
ZooKeeper Transactional Log File with dbid 0 txnlog format version 2
# 客户端会话创建的事务操作日志,分别记录了 事务操作时间、客户端会话ID、CXID客户端操作序列号、ZXID、操作类型和会话超时时间
...11:07:41 session 0x1446994y6273434 cxid 0x0 zxid 0x300000002 createSession 30000
# 节点创建的事务操作日志,记录了操作类型、节点路径、节点数据内容、节点ACL信息、是否是临时节点(F表示永久节点,T表示临时节点)、节点版本号
...11:08:40 session 0x1446995520000 cxid 0x2 zxid 0x3000003 create '/test_log,#7631,v{s{31,s{'world,'anyone}}},F,2
- 事务日志文件不会记录读操作
FileTxnLog类
在其public synchronized boolean append(TxnHeader hdr, Record txn, TxnDigest digest)方法中进行了日志的写入,会传递事务头TxnHeader和事务体Record,日志写入步骤:
- 判断FileTxnLog是否已关联上一个可写的事务日志文件,如果没有关联上,就会用与事务操作关联的ZXID作为后缀创建一个事务日志文件,同时构建事务日志文件头信息(包含魔数magic、事务日志格式版本version、dbid)并写入日志文件。改日志文件的文件流会放入 Queue streamsToFlush = new ArrayDeque<>() 中
- 对日志文件进行磁盘空间预分配(日志文件不断追加写入会触发底层磁盘空白块的Seek,为提高IO效率,所以预分配磁盘空间),通常一个日志文件预分配64MB,已分配空间不足4KB时会再次分配,预分配的文件使用0填充,预分配的文件大小使用 zookeeper.preAllocSize 进行设置
- 事务序列化,包括事务头TxnHeader和事务体Record的序列化,事务体又分为会话创建事务CreateSessionTxn、节点创建事务CreateTxn、节点删除事务DeleteTxn、节点数据更新事务SetDataTxn
- 为保证事务日志文件的完整性和准确性,ZK在将事务日志写入文件前,会根据序列化步骤产生的字节数组计算checksum,ZK默认使用Adler32算法计算checksum
- 将序列化后的事务头、事务体和checksum写入文件流,由于ZK使用的是BufferedOutputStream,写入的数据并没有立刻到达磁盘
- 事务日志刷入磁盘:将缓冲数据输入磁盘,从streamToFlush 中获取文件流,调FileChannel.force(bool metadata) 进行磁盘文件的强制写入,该方法基于底层的fsync接口,通过 zookeeper.forceSync 来设置
TRUNC日志截断
在运行过程中如果出现非Leader服务器的ZXID(peerLastZxid)大于Leader服务器的,此时Leader服务器会发出TRUNC给这台服务器,清除掉所有包含或大于peerLastZxid的事务日志,保持与Leader服务器的同步
Sanpshot数据快照
记录ZK服务器上某一时刻全量内存数据内容,写入到指定磁盘文件中,同样位于指定的dataDir目录下。与事务日志文件不同的是,快照文件没有采用预分配的方式,所以快照文件的大小就可以反映当前ZK服务器内存中的全量数据大小。
快照数据的解析可使用命令 java SnapshotFormatter snapshot.30000000007
快照文件记录的是数据节点的元信息,不包含节点的数据内容
FileSnap类
ZK定期将内存数据库全量Dump到本地文件,这个文件就是Snapshot,通过snapCount配置在事务日志记录多少次后进行快照写入。数据快照的流程是

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
etadata) 进行磁盘文件的强制写入,该方法基于底层的fsync接口,通过 zookeeper.forceSync 来设置
TRUNC日志截断
在运行过程中如果出现非Leader服务器的ZXID(peerLastZxid)大于Leader服务器的,此时Leader服务器会发出TRUNC给这台服务器,清除掉所有包含或大于peerLastZxid的事务日志,保持与Leader服务器的同步
Sanpshot数据快照
记录ZK服务器上某一时刻全量内存数据内容,写入到指定磁盘文件中,同样位于指定的dataDir目录下。与事务日志文件不同的是,快照文件没有采用预分配的方式,所以快照文件的大小就可以反映当前ZK服务器内存中的全量数据大小。
快照数据的解析可使用命令 java SnapshotFormatter snapshot.30000000007
快照文件记录的是数据节点的元信息,不包含节点的数据内容
FileSnap类
ZK定期将内存数据库全量Dump到本地文件,这个文件就是Snapshot,通过snapCount配置在事务日志记录多少次后进行快照写入。数据快照的流程是
[外链图片转存中…(img-D6G46jdb-1715691284583)]
[外链图片转存中…(img-Ohn9HfiQ-1715691284583)]
[外链图片转存中…(img-XeyeXyi4-1715691284583)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 82
82











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









