








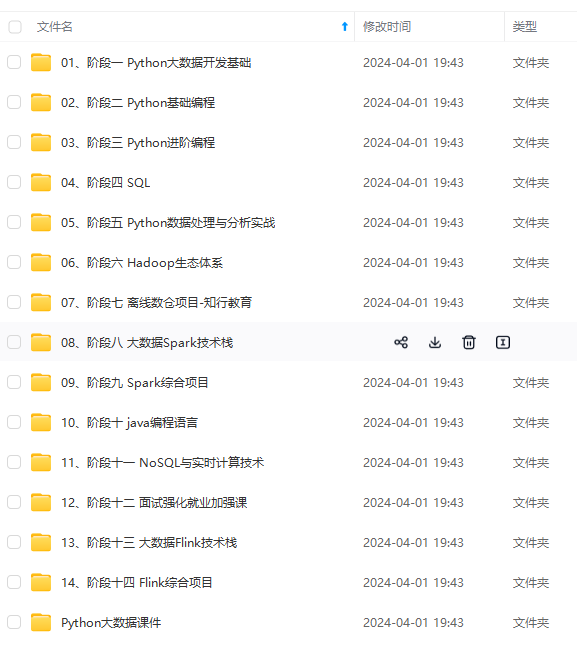
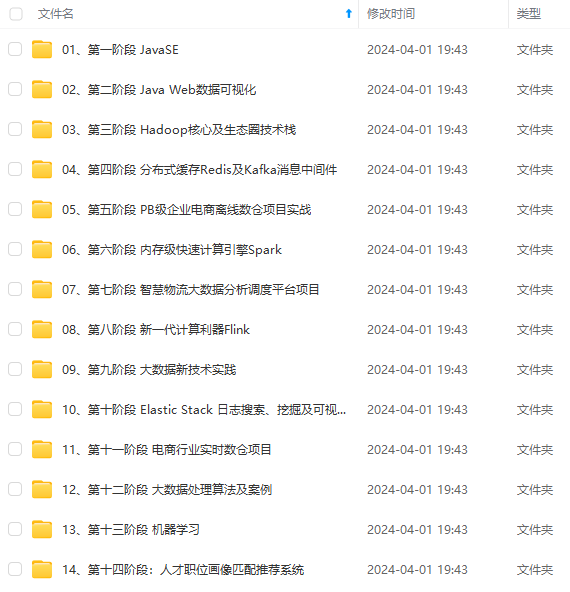
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
前言
Flink是一个分布式流处理引擎,可以处理实时数据流和批处理数据。它支持多种数据源和数据目的地,并且提供了丰富的流处理操作,如窗口化、聚合、过滤、连接和转换等。Flink还支持多种语言编写的应用程序,如Java、Scala和Python等。
Flink的核心特性包括:
- 高吞吐量和低延迟:Flink采用了基于内存的流处理方式,可以实现毫秒级别的低延迟和高吞吐量处理。
- 精确一次性处理(Exactly-once processing):Flink的流式处理引擎可以确保每条数据仅被处理一次,从而避免数据重复和丢失等问题。
- 支持多种数据源和数据目的地:Flink能够从多种数据源中读取数据,并将处理结果输出到多种数据目的地中,如Kafka、Hadoop、Cassandra、ElasticSearch等。
- 灵活的数据分析方式:Flink支持多种数据分析方式,包括流式处理、窗口化聚合、流式SQL查询和机器学习等。
Flink的架构由JobManager和TaskManager两个组件组成。JobManager负责接收和调度应用程序,并协调TaskManager的执行。TaskManager负责执行具体的任务,如数据处理、窗口化、聚合等。
Flink的优化包括优化数据倾斜、调整并行度、合并算子、使用状态后端、调整内存管理等。这些优化手段可以提高Flink的性能和稳定性,保证Flink的高吞吐量和低延迟处理。
什么是Flink
大数据
大数据(Big Data)是指规模庞大、结构多样且速度快速增长的数据集合。这些数据集合通常包含传统数据库管理系统无法有效处理的数据,具有高度的复杂性和挑战性。大数据的主要特点包括三个维度:三V,即Volume(数据量大)、Variety(数据多样性)、Velocity(数据速度)。
- 数据量大(Volume):大数据的最明显特征之一是其庞大的数据量。传统的数据处理方法和工具在处理这种规模的数据时可能会变得低效或不可行。
- 数据多样性(Variety):大数据不仅包括结构化数据(如表格数据),还包括半结构化数据(如JSON、XML)和非结构化数据(如文本、图像、音频、视频等)。这些数据可能来自不同的源头和不同的格式。
- 数据速度快(Velocity):大数据往往以高速率产生、流动和累积。这要求数据处理系统能够实时或近实时地处理数据,以便从中获取有价值的信息。
分布式计算
随着计算机技术的发展和数据规模的增大,单台计算机的处理能力和存储容量逐渐变得有限,无法满足大数据处理的要求。为了应对这一挑战,分布式计算应运而生,它利用多台计算机组成集群,将计算任务分割成多个子任务并在不同的计算节点上并行执行,从而提高计算效率和处理能力。
分布式计算的核心思想是将大问题划分为小问题,将任务分发给多个计算节点并行执行,最后将结果合并得到最终的解。这种方式有效地解决了单台计算机无法处理大规模数据和高并发计算的问题。同时,分布式计算还具有良好的可扩展性,可以根据数据量的增加灵活地扩展集群规模,以应对不断增长的数据挑战。
分布式计算的概念听起来很高深,其背后的思想却十分朴素,即分而治之,又称为分治法(Divide and Conquer)。分治法是一种解决问题的算法设计策略,它将一个问题分解成多个相同或相似的子问题,然后分别解决这些子问题,最后将子问题的解合并起来得到原问题的解。分治法常用于解决复杂问题,尤其是在大数据处理中,可以将大规模的数据集合分割成更小的部分,然后分别处理这些部分,最后合并结果。
在处理大数据问题时,可以使用分治法的思想来提高效率和可扩展性,以下是一些应用分治法处理大数据问题的示例:
- MapReduce 模式:分治法的经典应用是 MapReduce 模式,它将大规模的数据集合分为多个小块,每个小块由不同的计算节点进行处理,然后将结果合并。这种方法适用于批处理任务,如数据清洗、转换、聚合等。
- 并行计算:将大规模的计算任务分解成多个小任务,分配给不同的计算节点并行处理,最后合并结果。这适用于需要大量计算的问题,如数值模拟、图算法等。
- 分布式排序:将大规模数据集合分割成多个部分,每个部分在不同的计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









