







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
xedit hadoop-env.sh
export JAVA\_HOME=/opt/module/jdk
export HADOOP\_HOME=/opt/module/hadoop
export HADOOP\_CONF\_DIR=$HADOOP\_HOME/etc/hadoop
export HADOOP\_LOG\_DIR=$HADOOP\_HOME/logs
环境变量
#HADOOP\_HOME
export HADOOP\_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP\_HOME/bin
export PATH=$PATH:$HADOOP\_HOME/sbin
分发环境
xsync /etc/proifle
分发hadoop
xsync hadoop/
检查java
检查hadoop

格式化
cd /opt/module/hadoop/
bin/hdfs namenode -format
启动脚本
vim hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
给权限
chmod 777 hdp.sh
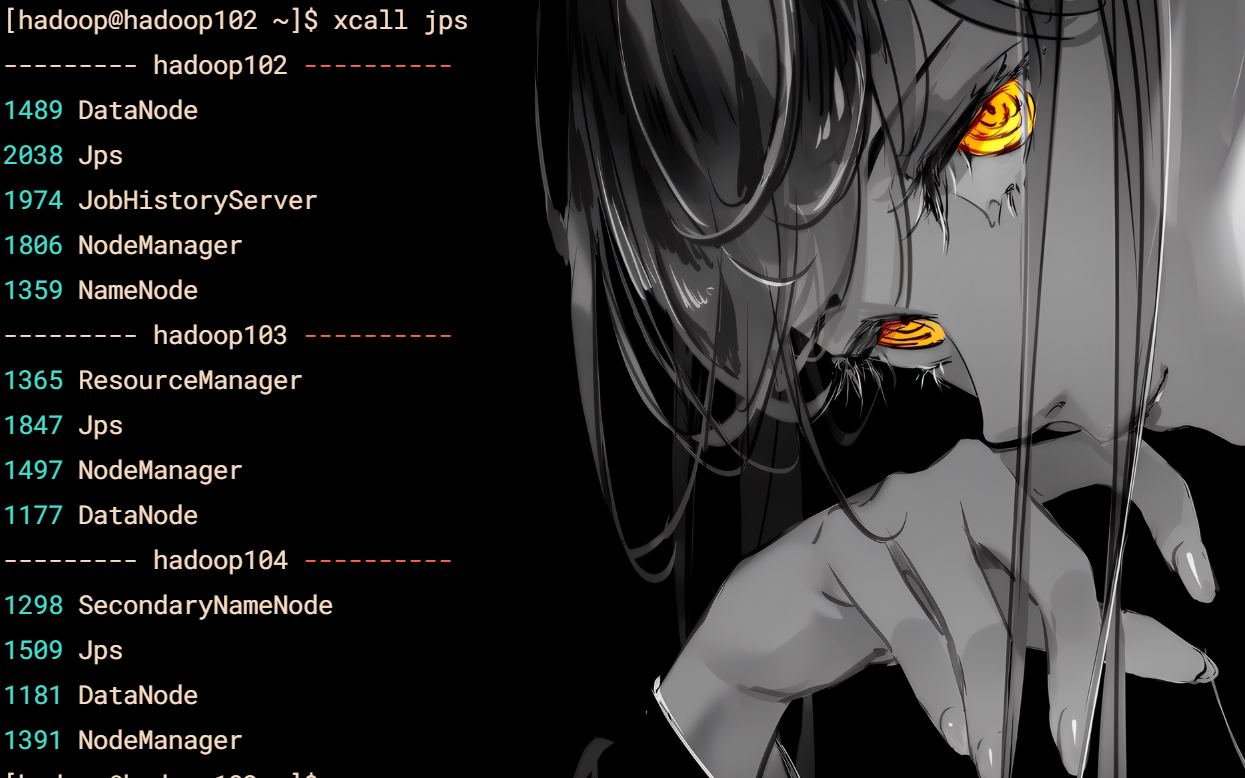
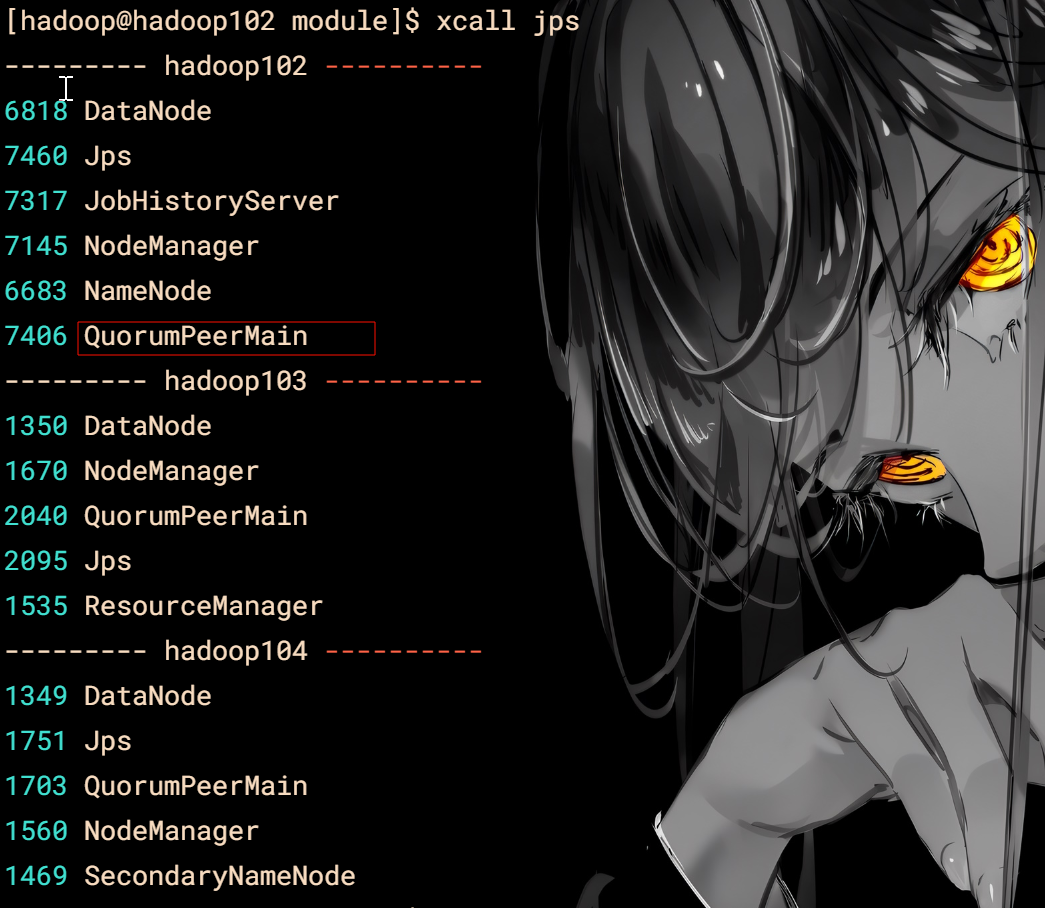
jps查看脚本
vim xcall
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "/opt/module/jdk/bin/jps $$\*"
done
chmod 777
启动与关闭
hdp.sh start
hdp.sh stop
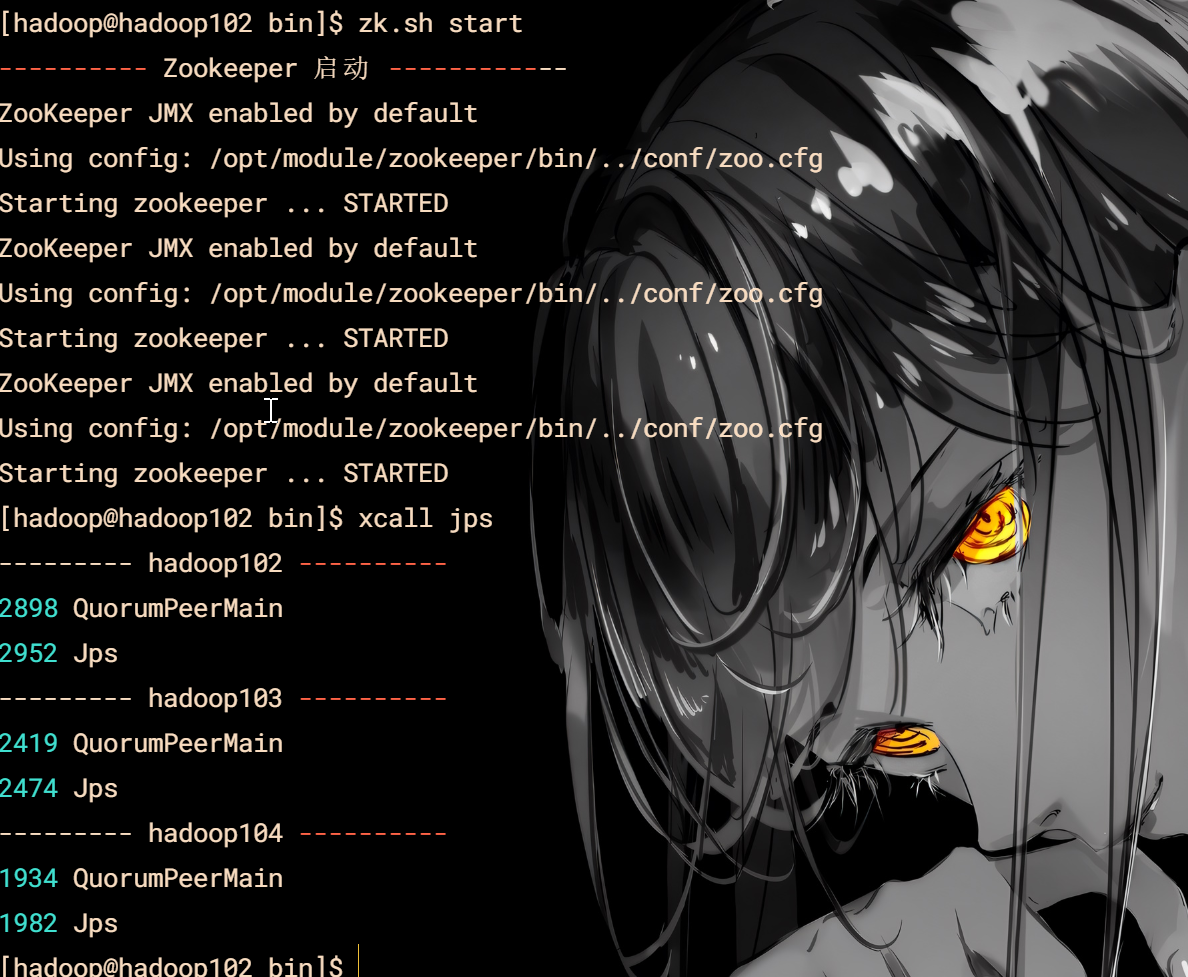
Zookeeper
解压修改名字
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
mv apache-zookeeper-3.7.1-bin/ zookeeper
配置
配置服务器编号
cd zookeeper/
mkdir zkData
cd zkData/
vim myid
2
注意编号是2
修改配置文件
cd conf/
mv zoo_sample.cfg zoo.cfg
xedit zoo.cfg
dataDir=/opt/module/zookeeper/zkData
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
或者替换配置文件内容
分发
cd /opt/moudle
xsync zookeeper/
修改hadoop103,hadoop104的myid配置
hadoop103 对应3
hadoop104 对应4
脚本
cd /home/hadoop/bin
vim zk.sh
#!/bin/bash
# 设置JAVA\_HOME和更新PATH环境变量
export JAVA\_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA\_HOME/bin
# 检查输入参数
if [ $# -ne 1 ]; then
echo "用法: $0 {start|stop|status}"
exit 1
fi
# 执行操作
case "$1" in
start)
echo "---------- Zookeeper 启动 ------------"
/opt/module/zookeeper/bin/zkServer.sh start
ssh hadoop103 "export JAVA\_HOME=/opt/module/jdk; export PATH=\$PATH:\$JAVA\_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh start"
ssh hadoop104 "export JAVA\_HOME=/opt/module/jdk; export PATH=\$PATH:\$JAVA\_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh start"
;;
stop)
echo "---------- Zookeeper 停止 ------------"
/opt/module/zookeeper/bin/zkServer.sh stop
ssh hadoop103 "export JAVA\_HOME=/opt/module/jdk; export PATH=\$PATH:\$JAVA\_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh stop"
ssh hadoop104 "export JAVA\_HOME=/opt/module/jdk; export PATH=\$PATH:\$JAVA\_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh stop"
;;
status)
echo "---------- Zookeeper 状态 ------------"
/opt/module/zookeeper/bin/zkServer.sh status
ssh hadoop103 "export JAVA\_HOME=/opt/module/jdk; export PATH=\$PATH:\$JAVA\_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh status"
ssh hadoop104 "export JAVA\_HOME=/opt/module/jdk; export PATH=\$PATH:\$JAVA\_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh status"
;;
*)
echo "未知命令: $1"
echo "用法: $0 {start|stop|status}"
exit 2
;;
esac
kafka
解压和修改名
tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/module/
mv kafka_2.12-3.3.1/ kafka
配置
xedit server.properties
添加
advertised.listeners=PLAINTEXT://hadoop102:9092
修改
log.dirs=/opt/module/kafka/datas
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
环境变量
#KAFKA\_HOME
export KAFKA\_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA\_HOME/bin
记得刷新
分发
xsync kafka/
修改hadoop103/104的配置文件
[hadoop@hadoop103 module]$ vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop103:9092
[hadoop@hadoop104 module]$ vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop104:9092
脚本
请记住kakfa是在zookeeper启动下才能成功启动
vim kf.sh
#!/bin/bash
# Kafka和Zookeeper的配置
KAFKA\_HOME=/opt/module/kafka
ZOOKEEPER\_HOME=/opt/module/zookeeper
JAVA\_HOME=/opt/module/jdk
# 定义启动Kafka的函数
start\_kafka() {
echo "Starting Kafka on hadoop102..."
$KAFKA\_HOME/bin/kafka-server-start.sh -daemon $KAFKA\_HOME/config/server.properties
echo "Starting Kafka on hadoop104..."
ssh hadoop104 "export JAVA\_HOME=$JAVA\_HOME; export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-start.sh -daemon $KAFKA\_HOME/config/server.properties"
echo "Starting Kafka on hadoop103..."
ssh hadoop103 "export JAVA\_HOME=$JAVA\_HOME; export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-start.sh -daemon $KAFKA\_HOME/config/server.properties"
}
# 定义停止Kafka的函数
stop\_kafka() {
echo "Stopping Kafka on hadoop102..."
$KAFKA\_HOME/bin/kafka-server-stop.sh
echo "Stopping Kafka on hadoop104..."
ssh hadoop104 "export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-stop.sh"
echo "Stopping Kafka on hadoop103..."
ssh hadoop103 "export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-stop.sh"
}
# 定义检查Kafka状态的函数
check\_status() {
echo "Checking Kafka status on hadoop102..."
ssh hadoop102 "jps | grep -i kafka"
echo "Checking Kafka status on hadoop104..."
ssh hadoop104 "jps | grep -i kafka"
echo "Checking Kafka status on hadoop103..."
ssh hadoop103 "jps | grep -i kafka"
}
# 处理命令行参数
case "$1" in
start)
start_kafka
;;
stop)
stop_kafka
;;
status)
check_status
;;
*)
echo "Usage: $0 {start|stop|status}"
exit 1
esac
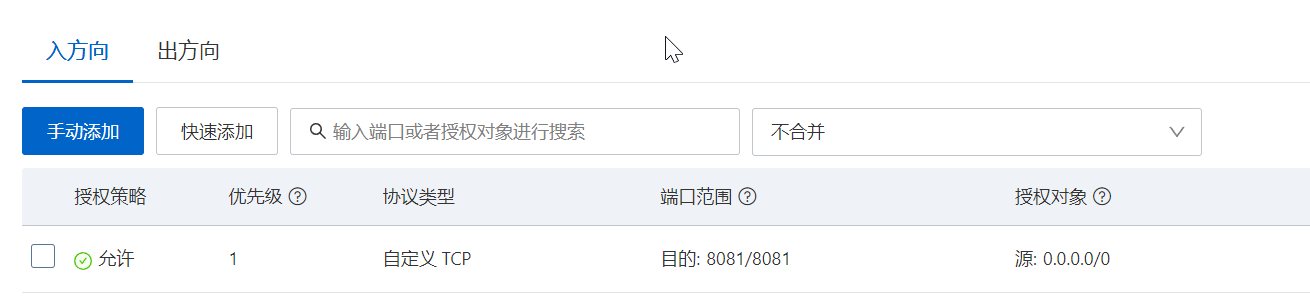
Flume
解压和修改名
tar -zxvf apache-flume-1.10.1-bin.tar.gz -C /opt/module/
mv apache-flume-1.10.1-bin/ flume
配置
vim log4j2.xml
修改
<Property name="LOG\_DIR">/opt/module/flume/log</Property>
添加
<Root level="INFO">
<AppenderRef ref="LogFile" />
<AppenderRef ref="Console" />
</Root>
分发
xsync flume/
MySQL
MySQL下载地址(推荐)
或者用上面的
解压下载的
上传MySQL和hive
安装MySQL
cd /opt/software/MySQL/
sh install_mysql.sh
root 密码是 000000
检查登录
mysql -root -p000000
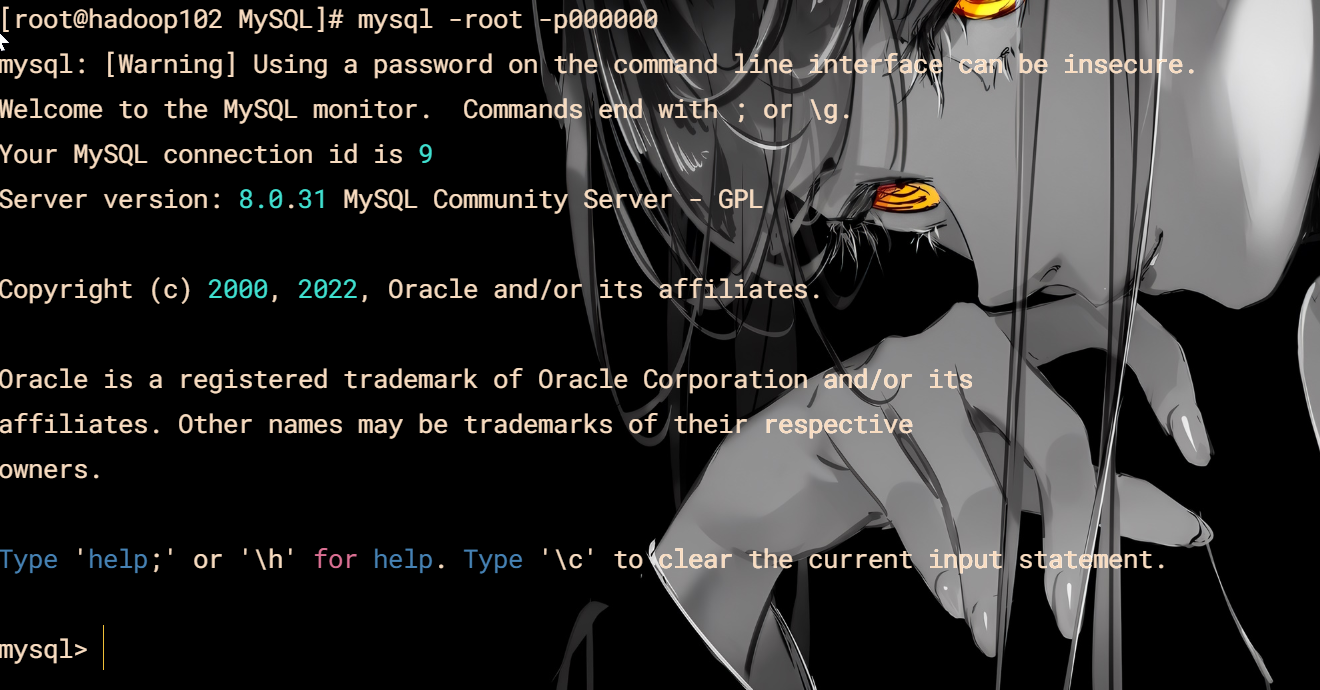
安装成功
Hive
解压和修改名
tar -zxvf hive-3.1.3.tar.gz -C /opt/module/
mv apache-hive-3.1.3-bin/ hive
配置
hive-env.sh
vim hive-env.sh
export HADOOP\_HOME=/opt/module/hadoop
export HIVE\_CONF\_DIR=/opt/module/hive/conf
export HIVE\_AUX\_JARS\_PATH=/opt/module/hive/lib
hive-site.xml
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--配置Hive保存元数据信息所需的 MySQL URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property>
<!--配置Hive连接MySQL的驱动全类名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--配置Hive连接MySQL的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置Hive连接MySQL的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
环境变量
#HIVE\_HOME
export HIVE\_HOME=/opt/module/hive
export PATH=$PATH:$HIVE\_HOME/bin
解决日志Jar包冲突
cd /opt/module/hive/lib/
mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak
将MySQL的JDBC驱动拷贝到Hive的lib目录
cp /opt/software/MySQL/mysql-connector-j-8.0.31.jar /opt/module/hive/lib/
检查
ll | grep mysql

配置元数据库
mysql操作
mysql -uroot -p000000
mysql> create database metastore;
mysql> quit;
hive操作
hdp.sh start
cd /opt/module/hive
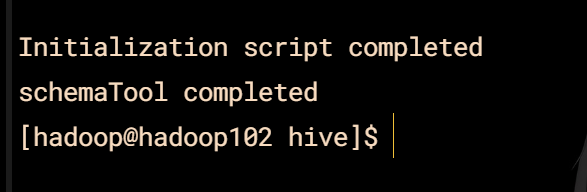
bin/schematool -initSchema -dbType mysql -verbos
修改元数据库字符集
use metastore;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
启动
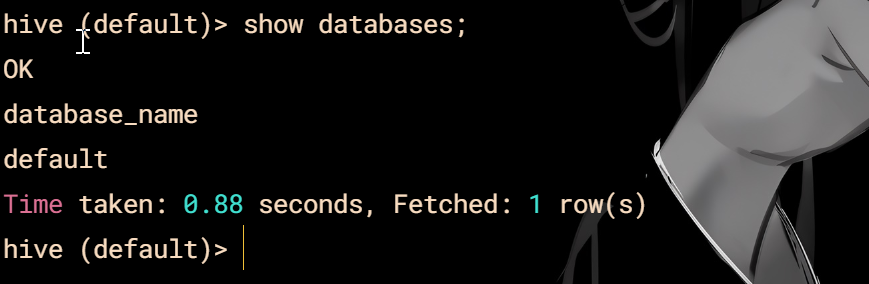
hive
show databases;
配置客户端
beeline
在hive目录创建logs文件夹
#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
bin/beeline
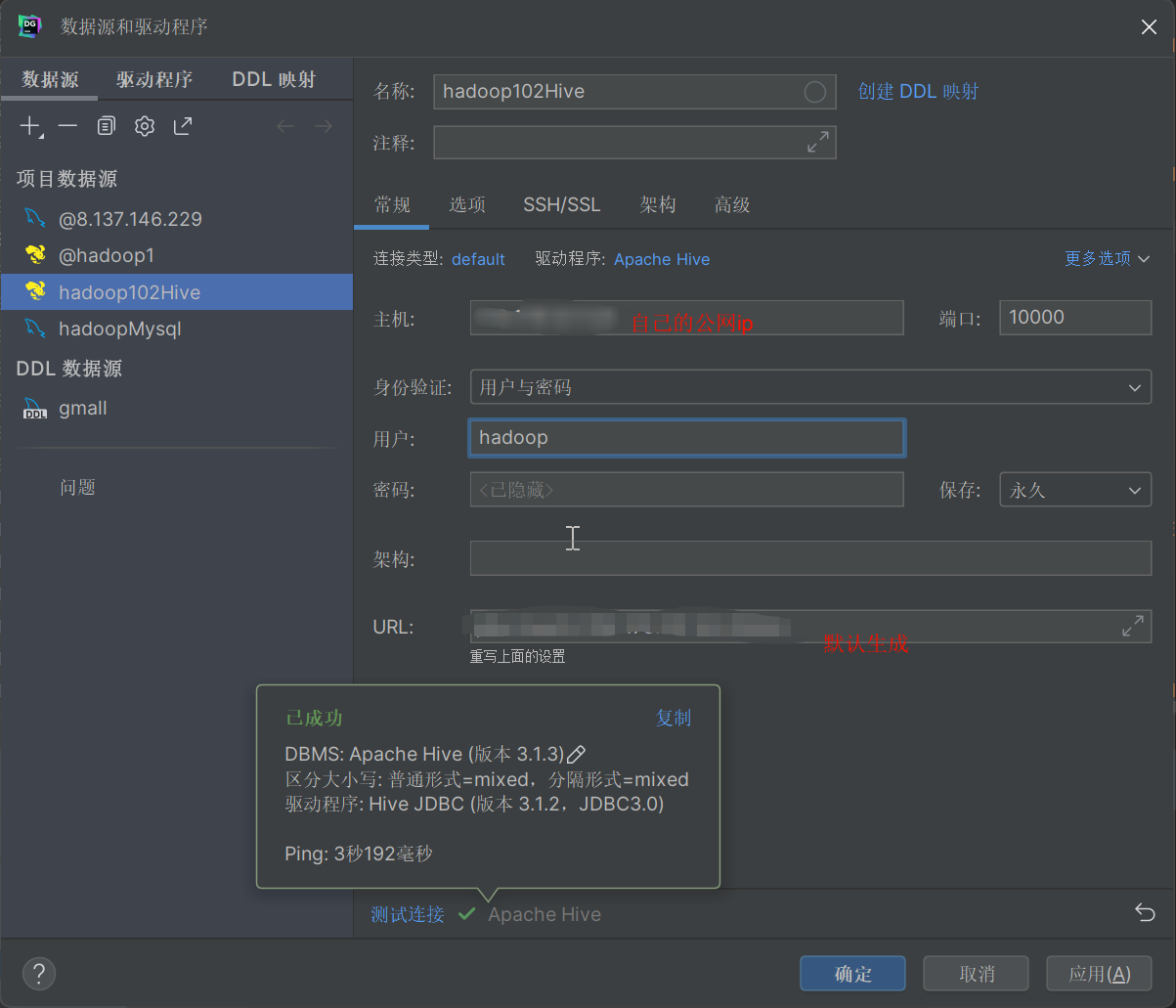
! connect jdbc:hive2://hadoop102:10000
hadoop
回车
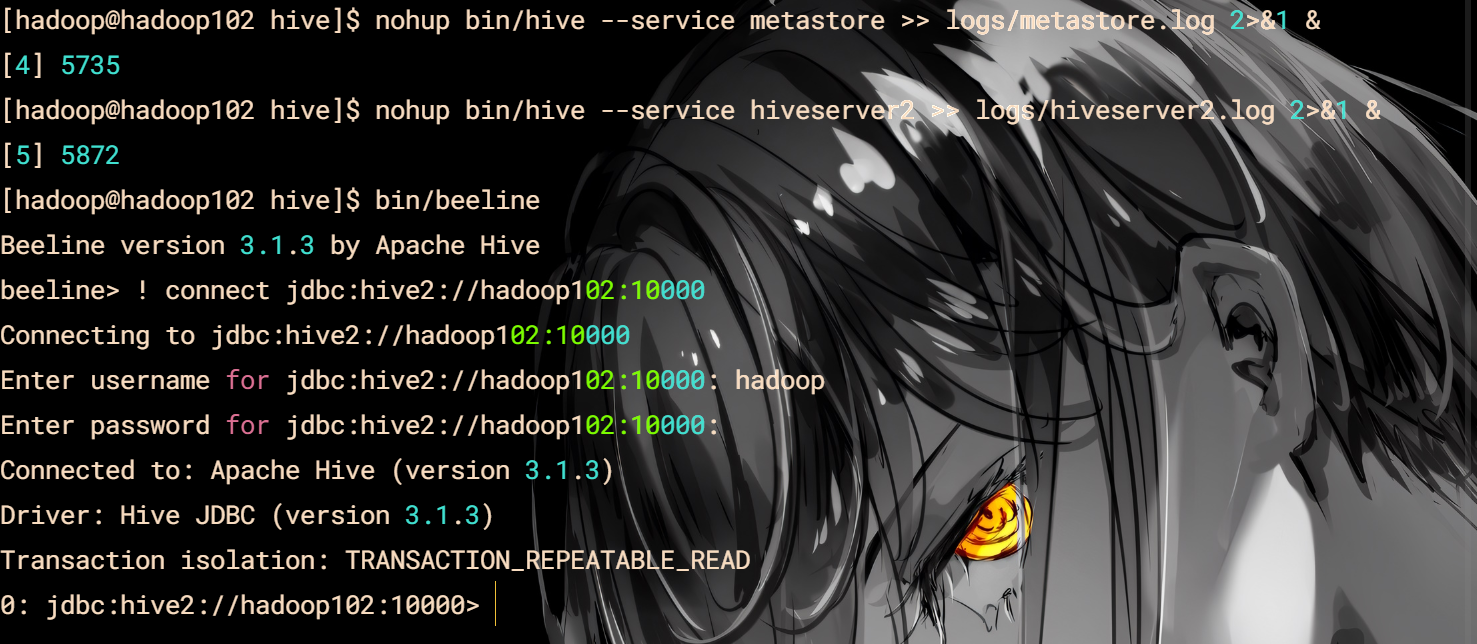
DG配置

HBase
安装前确保Hadoop集群和zk启动
解压和修改名
tar -zxvf hbase-2.4.11-bin.tar.gz -C /opt/module/
mv hbase-2.4.11/ hbase
配置
环境变量配置
#HBASE\_HOME
export HBASE\_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE\_HOME/bin
记得分发和刷新一下
hbase-env.sh
export HBASE\_MANAGES\_ZK=false
hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
regionservers
hadoop102
hadoop103
hadoop104
解决HBase和Hadoop的log4j兼容性问题
cd /opt/module/hbase/lib/client-facing-thirdparty/
mv slf4j-reload4j-1.7.33.jar slf4j-reload4j-1.7.33.jar.bak
分发和启动
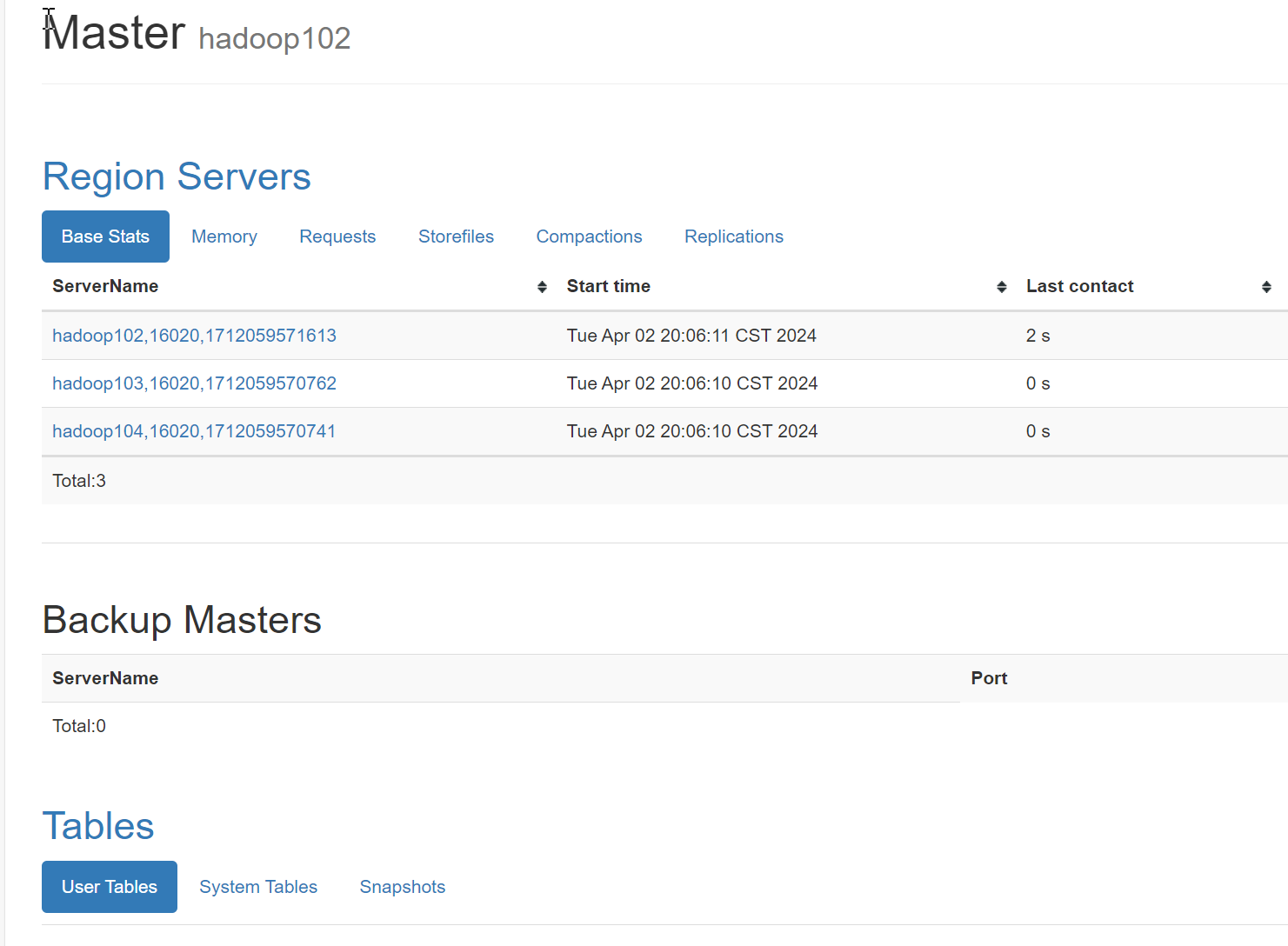
成功图,端口号16010
如果说找不到jdk
自动在hbase-env.sh添加jdk路径
高可用
touch conf/backup-masters
echo hadoop103 > conf/backup-masters
最后分发就行
Flink
解压和修改名
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
hbase.wal.provider
filesystem
**regionservers**
hadoop102
hadoop103
hadoop104
解决HBase和Hadoop的log4j兼容性问题
cd /opt/module/hbase/lib/client-facing-thirdparty/
mv slf4j-reload4j-1.7.33.jar slf4j-reload4j-1.7.33.jar.bak
#### 分发和启动
成功图,端口号16010

如果说找不到jdk
自动在hbase-env.sh添加jdk路径
#### 高可用
touch conf/backup-masters
echo hadoop103 > conf/backup-masters
最后分发就行
### Flink
解压和修改名
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-QarRs2O5-1713210008269)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









