







is_pass_rule bigint,
is_obtain_qutoa bigint,
quota decimal(30,6), update_time string
) partitioned by (ds string comment ‘日期分区’);
–动态分区需要设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
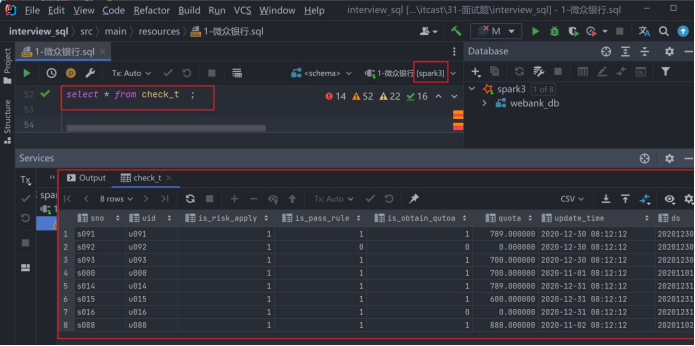
insert overwrite table check_t partition (ds) select sno,
uid, is_risk_apply, is_pass_rule, is_obtain_qutoa, quota,
update_time,
ds
from check_view;
– 创 建 借 据 表
create table debt(
duebill_id string comment ‘借据号’,
uid string, prod_type string,
putout_date string,
putout_amt decimal(30, 6),
balance decimal(30, 6),
is_buliang int,
overduedays int
)partitioned by (ds string comment ‘日期分区’);
–资料提供了一个34899条借据数据的文件
–下面补充如何将文件的数据导入到分区表中。需要一个中间普通表过度。
drop table if exists webank_db.debt_temp;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









