









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
修改主机名

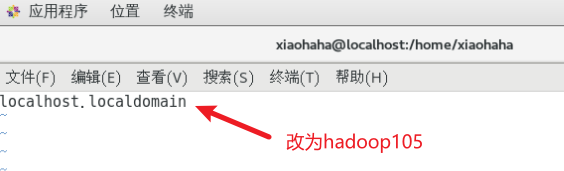
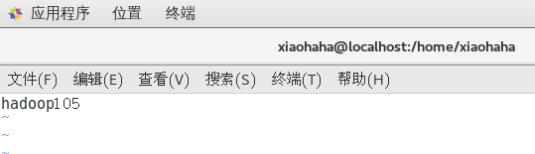
配置hosts映射文件

这里建议一次写入多个映射以便后面再次动态上线节点
注意,如果有修改的话应该在各个虚拟机上都将这个文件改一下,保持一致

可以了,重启一下hadoop105,因为我hosts只改了hadoop105的,所以如果你修改了所有虚拟机的hosts的话,也都需要重启

3. 关闭防火墙、设置时间同步、设置免密登录
在Xshell7上连接hadoop105,如果没有这个软件的话再虚拟机内的终端执行也是一样的

这样输入IP地址就行

这里输入你虚拟机一直在用的用户名和密码就行,如何点击连接

接受并保存
 如下
如下

关闭防火墙、关闭防火墙的开机自启(如果其他虚拟机都没有关闭的话也需要关闭)

时间同步:
关闭hadoop105d1 ntp 服务和自启动

配置hadoop105与hadoop102(也就是namenode所在的虚拟机)1分钟同步一次时间


wq退出后修改hadoop105的时间,一分钟后看看时间同步能否生效
一定要保证hadoop102虚拟机是开着的,否则时间无法同步

设置免密登录:生成公、私钥,然后把公钥分发给其他虚拟机,这样所有虚拟机间就可以免密登录了
 后面依次输入ssh-copy-id hadoop103/104/105 (也是需要拷贝给自己的)操作与拷贝给Hadoop102一致
后面依次输入ssh-copy-id hadoop103/104/105 (也是需要拷贝给自己的)操作与拷贝给Hadoop102一致
之后再hadoop105的root模式下重复上面的操作,因为有些文件是需要root权限才能访问的

也是依次输入ssh-copy-id hadoop102/103/104/105 (也是需要拷贝给自己的)
ok了,因为在开头链接中的教材第九节中已经配置好了hadoop102到104的两两间的免密登录(不管是普通用户还是root用户),而我们刚刚已经配置好了hadoop102/103/104/105访问hadoop105的免密登录,只差反方向的免密登录,也就是hadoop105访问hadoop102/103/104/105的免密登录,所以需要依次在hadoop102/103/104上做如下配置
 hadoop103/104只需要效仿hadoop102这样做即可
hadoop103/104只需要效仿hadoop102这样做即可
接下来验证一下能否在其他机器登入hadoop105(如下,无需密码,成功)

4. 获取JDK、hadoop文件
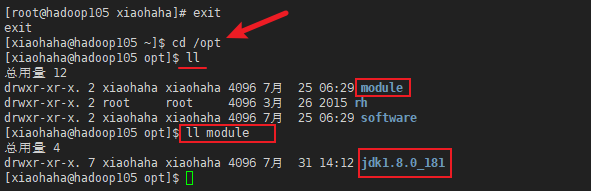
将hadoop102的jdk(是解压后的)拷贝到105上

在hadoop105上检查,jdk存在
(在这个过程中也是在实验我们免密登录成功与否,如果发送的同时无需输入密码,则是免密登录成功)
此时我们可以反过来,在hadoop105中使用scp命令向hadoop102“索要”文件看免密登录成功与否,我们正好需要hadoop,如下所示:(无需密码,免密登录成功)

在hadoop105上检查是否索要成功

5. 小插曲:因为我们后来的n多次配置是在hadoop102上写好,需要同步给hadoop103/104/105,所以我们在这写一个脚本专门用于分发配置文件,方便许多(如果你有按照文章开头的链接进行配置的话,这一步只需要稍微修改一下脚本内容即可)
在hadoop102下创建bin目录

编写脚本xsync

 文件内容在
文件内容在
https://blog.csdn.net/m0_46413065/article/details/115087025?spm=1001.2014.3001.5502
里面找

6. 配置java和hadoop
准备就绪,我们需要给hadoop105分发hadoop和java的配置文件
位于/etc/profile.d/my_env.sh下,之前已经在hadoop102配置好了,只需要分发给其他虚拟机即可

 用脚本分发后,可以在hadoop105上查看是否分发成功
用脚本分发后,可以在hadoop105上查看是否分发成功

接下来要让环境变量生效
 分发hadoop配置文件,配置文件的内容在开头链接中第十节已经详细配置好了
分发hadoop配置文件,配置文件的内容在开头链接中第十节已经详细配置好了
hadoop配置文件在/opt/module/hadoop-3.1.3/etc/hadoop/下
 配置workers:它的作用是启动dfs的时候可以按照里面的顺序来启动datanode
配置workers:它的作用是启动dfs的时候可以按照里面的顺序来启动datanode

 分发workers
分发workers
 好了!!!!!!!让咱来打开hadoop105的datanode
好了!!!!!!!让咱来打开hadoop105的datanode
 我们再多试一下,看看hadoop105的datanode能否跟随hadoop102的dfs开关命令而开关
我们再多试一下,看看hadoop105的datanode能否跟随hadoop102的dfs开关命令而开关
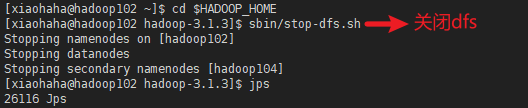
发现hadoop105的datanode也关闭了

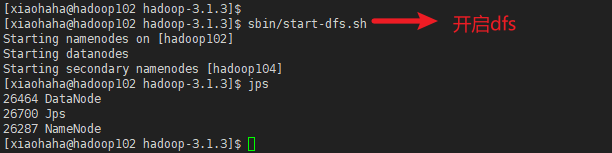 发现hadoop105的datanode也开启了
发现hadoop105的datanode也开启了
 一般来说,到这里就算成功了,在hdfsWeb上可以看到如下所示:
一般来说,到这里就算成功了,在hdfsWeb上可以看到如下所示:

7. 遇到的问题
我在完成上面6步后,web页面是这样的,我多次刷新,发现我所属hadoop102和hadoop105的datanode总是交替出现,但不同时出现,这就很奇怪了
 在网上搜了一下,原因是所属hadoop102和hadoop105的datanode的Uuid冲突,解决方法是删除current目录下的VERSION文件,然后重启dfs
在网上搜了一下,原因是所属hadoop102和hadoop105的datanode的Uuid冲突,解决方法是删除current目录下的VERSION文件,然后重启dfs
然后我就将hadoop105的VERSION给删除了,位置是 $HADOOP_HOME/data/dfs/data/current,然后我重启dfs,发现hadoop105的datanode并没有跟着dfs启动(所以刚刚删除VERSION的操作也不用试了,直接尝试下面的解决方法),那肯定是哪个地方出错了,于是我就查看了hadoop105的datanode日志(位于 $HADOOP_HOME/logs/下),发现了问题所在:
 翻译:目录/opt/module/hadoop-3.1.3/data/dfs/data处于不一致的状态:无法格式化存储目录,因为当前目录不是空的。
翻译:目录/opt/module/hadoop-3.1.3/data/dfs/data处于不一致的状态:无法格式化存储目录,因为当前目录不是空的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3884
3884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









