







函数的调用
a = multiply(5) # 5到底是y呢,还是x,无法解释
a
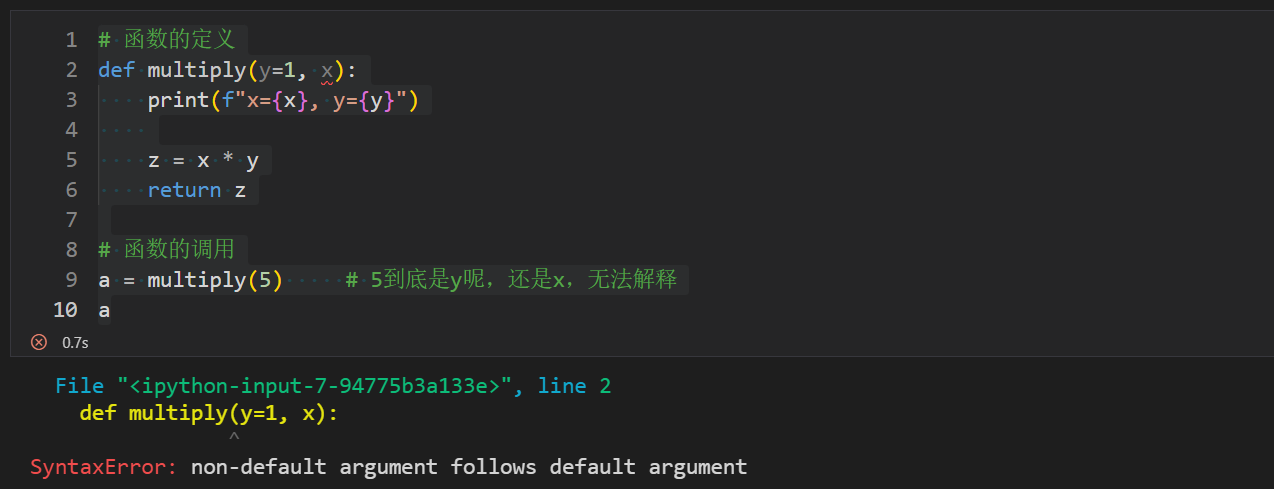
提示错误为:默认参数后跟着非默认参数。
* 默认参数定义时一定要使用不可变数据类型,否则结果可能会超出预期;
函数的定义
def list_add(x=[]):
“”"
参数x为默认参数,目的是没有参数传入时,返回一个[0]
“”"
print(f"x={x}")
x.append(0)
return x
函数的调用
a = list_add()
print(“return:”, a)
a = list_add()
print(“return:”, a)
a = list_add()
print(“return:”, a)
输出
x=[]
return: [0]
x=[0]
return: [0, 0]
x=[0, 0]
return: [0, 0, 0]
可以看到x的输入值发生了变化,第一次被调用时,x增加了一个[0],第二次作为输入时,已经不是[]了。
出现这种问题的原因是什么呢?
首先来看一下变量参数传递的机制:首先变量作为参数传递到函数中时,函数会产生一个变量的副本,在函数中对参数的操作,其实都是针对变量的副本的操作,举例说明:
函数的定义
def echo(x):
print(f"2.x = {x}, id(x):{id(x)}")
x的值在函数中已经发生了变化
x = 6
print(f"3.x = {x}, id(x):{id(x)}")
return x
k = 5
print(f"1.k = {k}, id(k):{id(k)}")
函数的调用
a = echo(x = k)
在函数外打印k的值,发现k的值没有发生变化
print(f"4.k = {k}, id(k):{id(k)}")
1.k = 5, id(k):140721390874496 # k原始值和直接引用的对象地址
2.x = 5, id(x):140721390874496 # k作为参数传递给函数后,其值及直接引用的对象地址,发现没有变化
3.x = 6, id(x):140721390874528 # 在函数中修改参数,其值及直接引用的对象地址,发生了变化
4.k = 5, id(k):140721390874496 # 出函数后,发现k值没有发生变化
从上面的结果可以看到,以不可变类型作为参数传递,其在函数内操作的其实是另外一个变量,在函数内对参数的修改不会影响到它的值。
而可变数据类型为参数传递时,虽然变量作为参数传递到函数中也会产生一个变量的副本,但是其是间接引用的,它们会间接引用到内存堆中同一个列表/字典对象,因此在函数中对可变数据类型的操作都会反馈到函数外的可变数据变量上。
如何避免这种情况呢,默认参数使用不可变数据类型.
函数的定义
def list_add(x=None):
“”"
参数x为默认参数,目的是没有参数传入时,返回一个[0]
“”"
print(f"x={x}")
if x == None:
x = [0]
return x
函数的调用
a = list_add()
print(“return:”, a)
a = list_add()
print(“return:”, a)
a = list_add()
print(“return:”, a)
输出
x=None
return: [0]
x=None
return: [0]
x=None
return: [0]
#### 3.2.3 命名关键参数
命名关键参数主要体现在函数调用的时候:函数调用的时候,指定参数名的参数
调用函数时,命名关键参数可以和位置参数一起用,但是命名关键参数必须在位置参数的后面
另外在函数定义阶段,在关键字参数前增加一个”\*”,表明后续的参数都是命名关键字参数,强制性必须按照命名关键字参数的用法使用,不可省略。
命名关键参数
def multiply(x, *, y): # *号后面的是命名关键字参数,
z = x * y
return z
函数的调用
a = multiply(5, y=6)
a
输出
30
错误用法示例:命名关键参数在位置参数的前面
命名关键参数-错误用法
def multiply(x, y):
z = x * y
return z
函数的调用
a = multiply(y=6, 5)
a
File “”, line 8
a = multiply(y=6, 5)
^
SyntaxError: positional argument follows keyword argument
提示语法错误:命名关键参数在位置参数的前面
#### 3.2.4 可变参数
Python函数提供了可变参数,来方便进行参数个数未知时的调用。可变参数将以tuple形式传递。
**格式: `*参数` (即在参数前加\*号)**
def getsum(*num):
sum = 0
for n in num:
sum += n
return sum
list = [2, 3, 4]
print(getsum(1, 2, 3))
print(getsum(*list))
#结果:6 9
序列的打包:当定义函数的时候,在函数参数的前面加 \* ,将元素打包成元组的形式
序列的拆包:当函数执行的时候,在实际参数的前面加 \* ,将序列进行拆包
def getsum(*num): # 参数序列的拆包
print(num)
sum = 0
for n in num:
sum += n
return sum
list = [2, 3, 4]
print(getsum(1, 2, 3))
print(getsum(*list)) # 参数序列的打包
#结果:6 9
输出
(1, 2, 3)
6
(2, 3, 4) # 对列表整个打包成元组作为参数传递进来
9
#### 3.2.5 关键参数
Python的可变参数以tuple形式传递,而关键字参数则是以dict形式传递。 即可变参数传递的是参数值,关键字参数传递的是参数名:参数值键值对。
形式:`**kw` 这是惯用写法,建议使用,容易被理解
def personinfo(name, age, **kw):
print(‘name:’, name, ‘age:’, age, ‘ps:’, kw)
personinfo(‘Steve’, 22)
personinfo(‘Lily’, 23, city = ‘Shanghai’)
personinfo(‘Leo’, 23, gender = ‘male’,city = ‘Shanghai’)
#### 3.2.6 各种参数之间组合
一次函数调用可以传递以上所述任何一种参数或者多种参数的组合,当然也可以没有任何参数。正如默认参数必须在最右端一样,使用多种参数时也对顺序有严格要求,也是为了解释器可以正确识别到每一个参数。
顺序:位置参数、默认参数、可变参数、命名关键字参数和关键字参数。
def function(a, b, c=0, *, d, **kw):
print(f’a = {a}, b ={b}, c = {c}, d = {d}, kw = {kw}')
function(5, 6, d=36, e=99, f=27)
a = 5, b =6, c = 0, d = 36, kw = {‘e’: 99, ‘f’: 27}
## 4. 函数的注释
举个例子:
函数的定义
def multiply(x, y):
“”"函数注释:乘法的实现
Args:
x (_type_): 乘数
y (_type_): 被乘数
Returns:
_type_: 乘积
“”"
z = x * y
return z
函数的调用
a = multiply(5, 6)
a
输出
30
## 5. 匿名函数
当函数体非常简单,可以使用lambda来定义匿名函数,而不用def来定义函数
### 5.1 语法
lambda [arg1 [,arg2,…argn]]:expression
### 5.2 def函数和lambda表达式的区别
| | def函数 | lambda表达式 |
| --- | --- | --- |
| 函数名 | 必须命名 | 匿名,无函数名 |
| 主体 | 代码块组合 | 仅支持一个返回值表达式 |
| 参数 | 位置、默认、命名关键、可变、关键参数 | 和def函数支持的一致 |
| 返回值 | 按需选择 | 函数对象,执行时返回表达式的值 |
| 使用场景 | 全场景 | 功能非常简单时,且仅少量调用的场景;可作为输入配合高阶函数使用 |
| 内存机制 | 建立函数时需要进行栈分配 | 无需变量,直接传递对象(也就是说无变量引用过程),用过即销毁 |
| 变量作用域 | 可以访问全局变量,函数内、外变量 | 仅可访问参数列表中的变量 |
举个例子:
* 函数def的实现
函数的定义
def multiply(x, y):
“”"函数注释:乘法的实现
Args:
x (_type_): 乘数
y (_type_): 被乘数
Returns:
_type_: 乘积
"""
z = x * y
return z
函数的调用
a = multiply(5, 6)
a
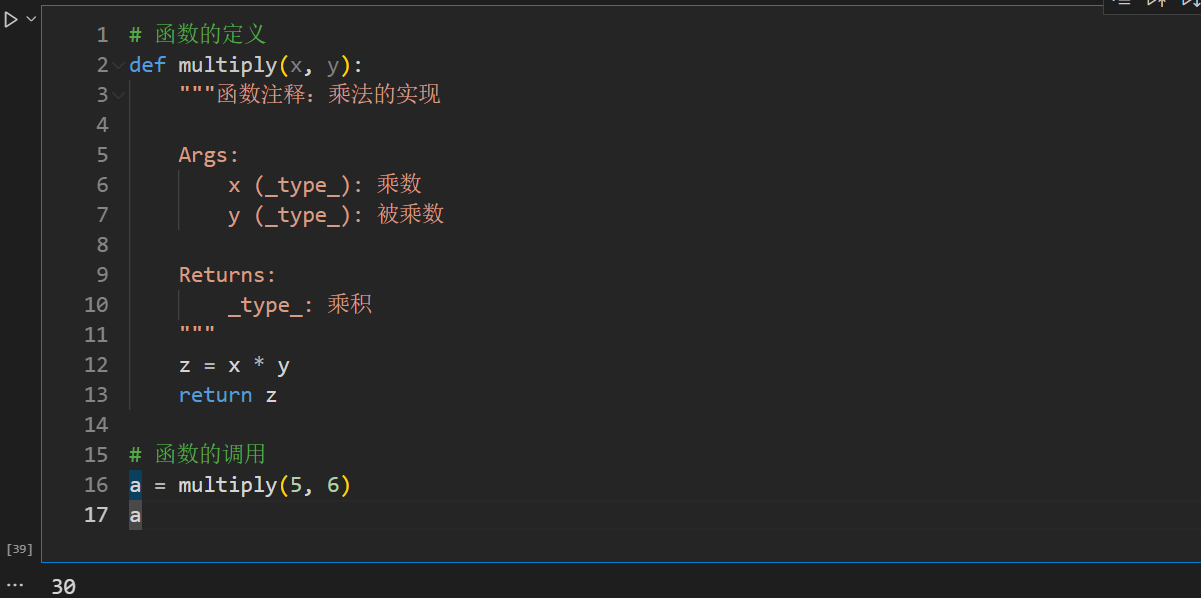
* lambda表达式的实现
f = lambda x, y: x*y
f(5, 6)

## 6. 递归函数
To Iterate is Human, to Recurse, Divine.
——人类擅长迭代,而神掌控递归!有兴趣的可以看一下分形理论,你会发现世界惊人的相似。
递归是一种重要的思想,**它将复杂问题不断地分成更小的相似的子问题,直到子问题可以用普通的方法解决,然后在子问题解决的基础上逐步解决上层的复杂问题**。
递归就是有去(递去)有回(归来),从复杂问题出发,到达可解决的子问题(停止条件),然后再从停止条件返回解决上层复杂问题。
递归算法有三个重要的原则:
* 递归算法必须有停止条件(否则会无限循环)
* 递归算法必须改变其状态并向停止条件靠近(数据规模在减小)
* 递归算法必须递归地调用自己,找到函数的等价关系式
def mySum(n):
# 结束条件:如果不加结束条件就会无限循环
if n == 1: # 函数的结束条件
print(f"mySum({n}) = {n}")
return 1
# 继续递归
print(f"mySum({n}) = {n} + mySum({n-1})")
return n + mySum(n-1) # 函数的等价关系式:mySum(n) = n + mySum(n-1)
递归函数的调用
mySum(100)
>
> mySum(100) = 100 + mySum(99)
> mySum(99) = 99 + mySum(98)
> …
> mySum(4) = 4 + mySum(3)
> mySum(3) = 3 + mySum(2)
> mySum(2) = 2 + mySum(1)
> mySum(1) = 1
> 5050
>
>
>
**参考文章:**
* [详解递归思想:https://wenku.baidu.com/view/4d3f014cbb4ae45c3b3567ec102de2bd9605de1d.html](https://bbs.csdn.net/topics/618545628)
## 7. 高阶函数
### 7.1 高阶函数定义
一个函数可以作为参数传给另外一个函数,或者一个函数的返回值为另外一个函数(若返回值为该函数本身,则为递归),满足其一则为高阶函数。
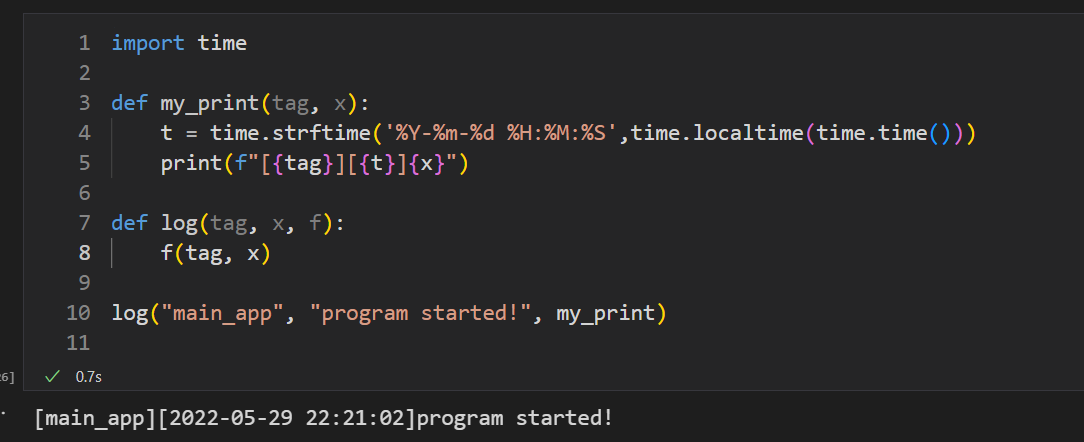
import time
def my_print(tag, x): # 自定义打印函数
t = time.strftime(‘%Y-%m-%d %H:%M:%S’,time.localtime(time.time()))
print(f"[{tag}][{t}]{x}")
def log(tag, x, f): # 日志函数
f(tag, x)
调用日志函数:my_print函数作为参数传递给log函数使用,log函数就是高阶函数
log(“main_app”, “program started!”, my_print)
7.2 常用的高阶函数
* map
将迭代对象中的每一个元素都应用一下func,得到返回值,形成新的迭代对象
* filter
过滤函数,按照函数将迭代对象中每一个元素都调用一次func方法,会得到True/False,如果True留下,如果是False丢弃
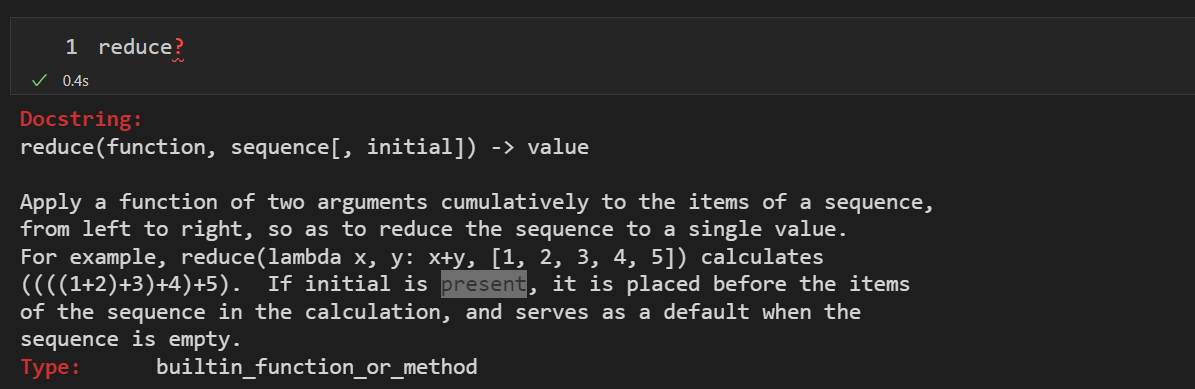
* reduce
接收两个参数,把一个函数作用在一个序列上,reduce会把结果继续和序列的下一个元素做累计计算
* sortby
如果指定了key,那么会根据key指定函数名,对每个元素使用函数,得到返回值,再根据返回值排序
#### 7.2.1 map
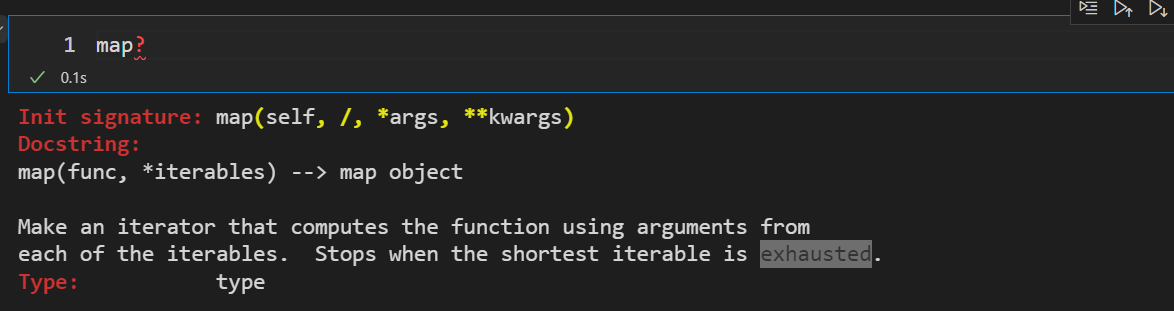
map函数有2个参数:函数和迭代对象,返回值为map对象,其功能为将迭代对象中的每一个元素都应用一下func,得到返回值,形成新的迭代对象
举例:
假如国家发钱促进消费,每人发放1万元数字人民币。这里有张三、李斯、龙川三人的账户余额分别为10000,300,3210,那么实现代码为
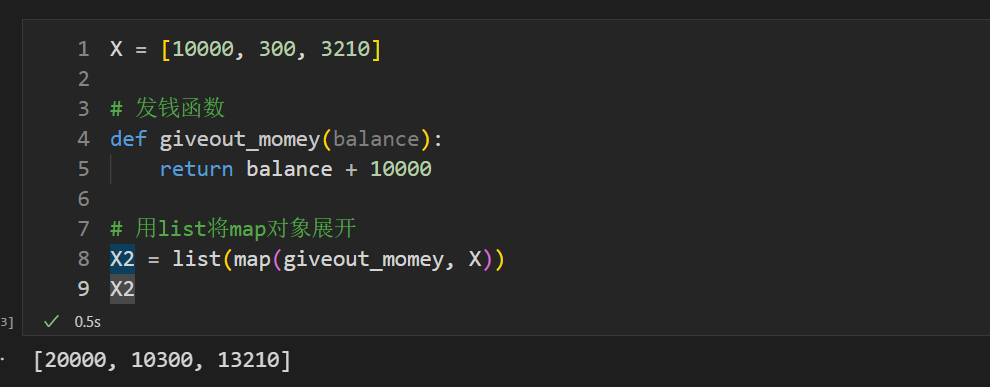
##### 7.2.1.1 常规def函数实现
X = [10000, 300, 3210]
def giveout_momey(balance):
return balance + 10000
X2 = list(map(giveout_momey, X)) # map返回值为map对象,用list将其展开
X2
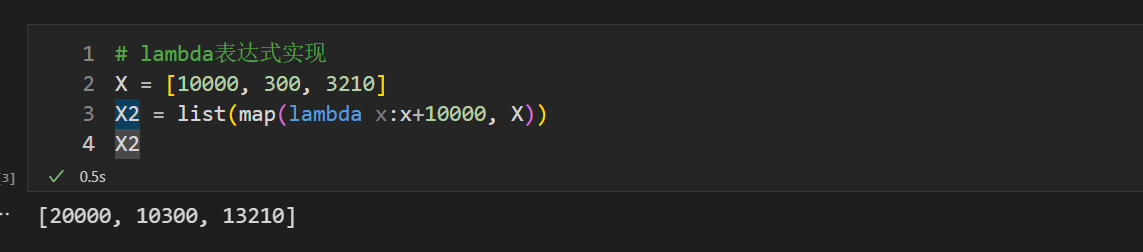
##### 7.2.1.2 lambda表达式实现
giveout\_money发钱函数很简单,可以使用lambda表达式来代替
lambda表达式实现
X = [10000, 300, 3210]
X2 = list(map(lambda x:x+10000, X))
X2
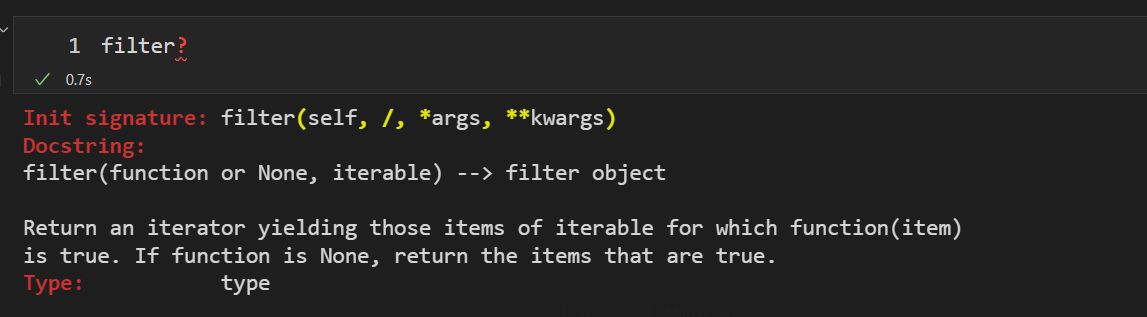
#### 7.2.2 filter函数
过滤函数,按照函数将迭代对象中每一个元素都调用一次func方法,会得到True/False,如果True留下,如果是False丢弃
举例:挑出万元户
挑出万元户
X = [10000, 300, 3210]
list(filter(lambda x:x>=10000, X))

* reduce
接收两个参数,把一个函数作用在一个序列上,reduce会把结果继续和序列的下一个元素做累计计算
from functools import reduce
X = [10, 3, 2, 7, 9, 8]
reduce(lambda x, y:x+y, [10, 3, 2, 7, 9, 8])
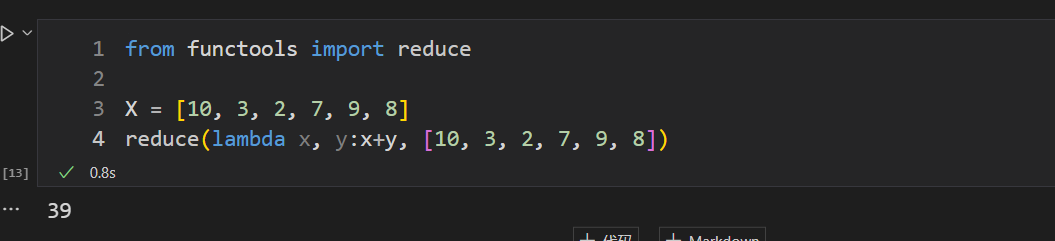
计算逻辑:先取10和3,求和后为13,然后再取后一个元素2,再做累加为15,再取后一个元素7…,直至累加完全部元素,最后返回一个值
#### 7.2.3 sorted
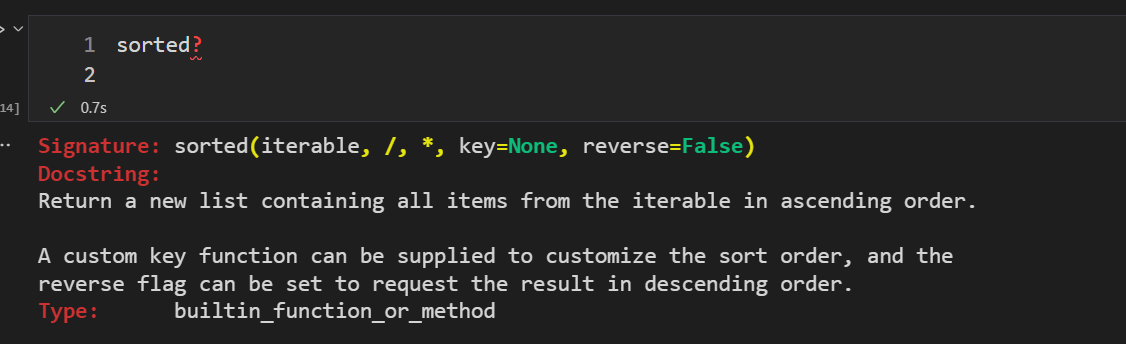
如果指定了key,那么会根据key指定规则排序,对每个元素使用函数,得到返回值,再根据返回值排序,第三个参数为升序/倒序选项,返回值为排序后的可迭代对象
举例:对学生的科目成绩(语文、数学、英语)排序
X = [
(“lily”, 100, 95, 66), # 姓名、语文、数学、英语
(“lucy”, 99, 86, 100),
(“zuck”, 100, 69, 90),
(“nick”, 99, 86, 89)
]
排序规则
def sort_rule(x):
return x[1], x[2], x[3]
升序排序reverse=False
sorted(X, key=lambda x:(x[1], x[2], x[3]), reverse=True)
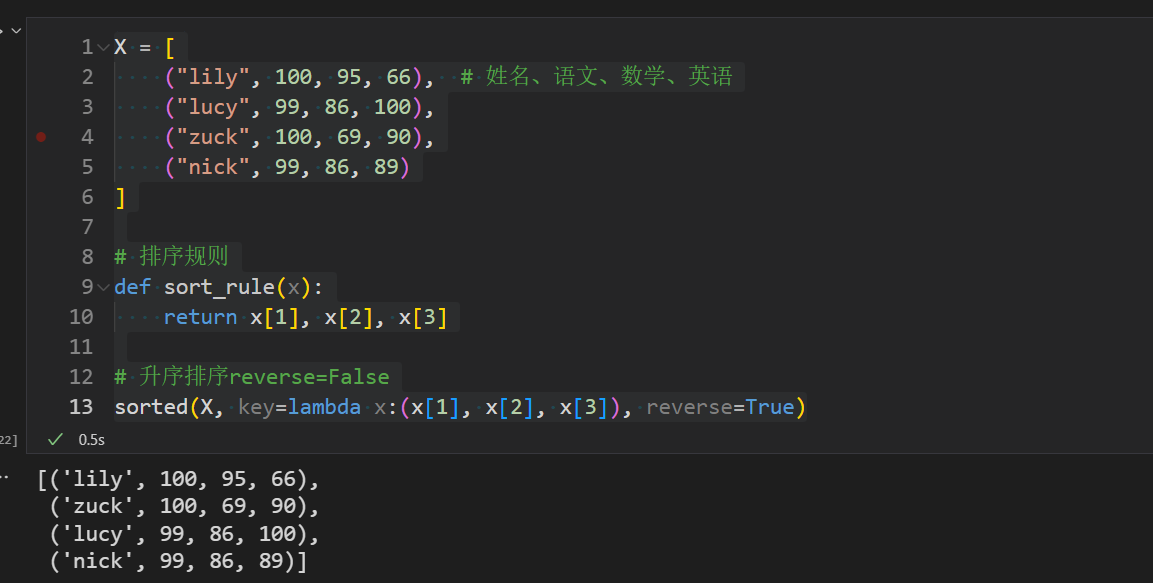
排序逻辑是按照语文、数学、英文的成绩来分组排序,先排语文,如果语文成绩一致,则再排数学,若数学一致则再排英语。
>
> [(‘lily’, 100, 95, 66), # lily的语文成绩和zuck一样好,则继续排数学,lily数学比zuck小,因此lily排第1
>
>
> (‘zuck’, 100, 69, 90), # zuck的语文成绩比nick和lucy都要好,因此zuck排第2
>
>
> (‘lucy’, 99, 86, 100), # lucy的语文成绩和nick一样,则继续排数学,lucy的数学成绩和nick一样,则继续排英语,lucy的英语好于nick,则排第3
>
>
> (‘nick’, 99, 86, 89)] # nick排最后
>
>
>
注意事项:此处lambda表达式的主体为(x[1], x[2], x[3]),为什么要加上小括号变成元组呢,因为lambda表达式仅支持一个表达式,变成元组后就符合lambda表达式的规则,否则就只能用def函数来实现。
参考链接:


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
第1
>
>
> (‘zuck’, 100, 69, 90), # zuck的语文成绩比nick和lucy都要好,因此zuck排第2
>
>
> (‘lucy’, 99, 86, 100), # lucy的语文成绩和nick一样,则继续排数学,lucy的数学成绩和nick一样,则继续排英语,lucy的英语好于nick,则排第3
>
>
> (‘nick’, 99, 86, 89)] # nick排最后
>
>
>
注意事项:此处lambda表达式的主体为(x[1], x[2], x[3]),为什么要加上小括号变成元组呢,因为lambda表达式仅支持一个表达式,变成元组后就符合lambda表达式的规则,否则就只能用def函数来实现。
参考链接:
[外链图片转存中...(img-dhkETimZ-1714438074419)]
[外链图片转存中...(img-sngjBA69-1714438074420)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









