







import paddle
import paddle.nn as nn
from paddle.io import Dataset
from utils.data import load_vocab
class IMDBDataset(Dataset):
def __init__(self, examples, word2id_dict):
super(IMDBDataset, self).init()
# 词典,用于将单词转为字典索引的数字
self.word2id_dict = word2id_dict
# 加载后的数据集
self.examples = self.words_to_id(examples)
def words\_to\_id(self, examples):
tmp_examples = []
for idx, example in enumerate(examples):
seq, label = example
# 将单词映射为字典索引的ID, 对于词典中没有的单词用[UNK]对应的ID进行替代
seq = [self.word2id_dict.get(word, self.word2id_dict['[UNK]']) for word in seq.split(" ")]
label = int(label)
tmp_examples.append([seq, label])
return tmp_examples
def \_\_getitem\_\_(self, idx):
seq, label = self.examples[idx]
return seq, label
def \_\_len\_\_(self):
return len(self.examples)
加载词表
word2id_dict= load_vocab(“./dataset/vocab.txt”)
实例化Dataset
train_set = IMDBDataset(train_data, word2id_dict)
dev_set = IMDBDataset(dev_data, word2id_dict)
test_set = IMDBDataset(test_data, word2id_dict)
print(‘训练集样本数:’, len(train_set))
print(‘样本示例:’, train_set[4])
>
> 训练集样本数: 25000
> 样本示例: ([2, 976, 5, 32, 6860, 618, 7673, 8, 2, 13073, 2525, 724, 14, 22837, 18, 164, 416, 8, 10, 24, 701, 611, 1743, 7673, 7, 3, 56391, 21652, 36, 271, 3495, 5, 2, 11373, 4, 13244, 8, 2, 2157, 350, 4, 328, 4118, 12, 48810, 52, 7, 60, 860, 43, 2, 56, 4393, 5, 2, 89, 4152, 182, 5, 2, 461, 7, 11, 7321, 7730, 86, 7931, 107, 72, 2, 2830, 1165, 5, 10, 151, 4, 2, 272, 1003, 6, 91, 2, 10491, 912, 826, 2, 1750, 889, 43, 6723, 4, 647, 7, 2535, 38, 39222, 2, 357, 398, 1505, 5, 12, 107, 179, 2, 20, 4279, 83, 1163, 692, 10, 7, 3, 889, 24, 11, 141, 118, 50, 6, 28642, 8, 2, 490, 1469, 2, 1039, 98975, 24541, 344, 32, 2074, 11852, 1683, 4, 29, 286, 478, 22, 823, 6, 5222, 2, 1490, 6893, 883, 41, 71, 3254, 38, 100, 1021, 44, 3, 1700, 6, 8768, 12, 8, 3, 108, 11, 146, 12, 1761, 4, 92295, 8, 2641, 5, 83, 49, 3866, 5352], 0)
>
>
>
##### 1.3 封装DataLoader
在构建 Dataset 类之后,我们构造对应的 DataLoader,用于批次数据的迭代.和前几章的 DataLoader 不同,这里的 DataLoader 需要引入下面两个功能:
1. 长度限制:需要将序列的长度控制在一定的范围内,避免部分数据过长影响整体训练效果
2. 长度补齐:神经网络模型通常需要同一批处理的数据的序列长度是相同的,然而在分批时通常会将不同长度序列放在同一批,因此需要对序列进行补齐处理.
对于长度限制,我们使用max\_seq\_len参数对于过长的文本进行截断.
对于长度补齐,我们先统计该批数据中序列的最大长度,并将短的序列填充一些没有特殊意义的占位符 [PAD],将长度补齐到该批次的最大长度,这样便能使得同一批次的数据变得规整.比如给定两个句子:
* 句子1: This movie was craptacular.
* 句子2: I got stuck in traffic on the way to the theater.
将上面的两个句子补齐,变为:
* 句子1: This movie was craptacular [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
* 句子2: I got stuck in traffic on the way to the theater
具体来讲,本节定义了一个collate\_fn函数来做数据的截断和填充. 该函数可以作为回调函数传入 DataLoader,DataLoader 在返回一批数据之前,调用该函数去处理数据,并返回处理后的序列数据和对应标签。
另外,使用[PAD]占位符对短序列填充后,再进行文本分类任务时,默认无须使用[PAD]位置,因此需要使用变量seq\_lens来表示序列中非[PAD]位置的真实长度。seq\_lens可以在collate\_fn函数处理批次数据时进行获取并返回。需要注意的是,由于RunnerV3类默认按照输入数据和标签两类信息获取数据,因此需要将序列数据和序列长度组成元组作为输入数据进行返回,以方便RunnerV3解析数据。
代码实现如下:
from functools import partial
def collate_fn(batch_data, pad_val=0, max_seq_len=256):
seqs, seq_lens, labels = [], [], []
max_len = 0
for example in batch_data:
seq, label = example
# 对数据序列进行截断
seq = seq[:max_seq_len]
# 对数据截断并保存于seqs中
seqs.append(seq)
seq_lens.append(len(seq))
labels.append(label)
# 保存序列最大长度
max_len = max(max_len, len(seq))
# 对数据序列进行填充至最大长度
for i in range(len(seqs)):
seqs[i] = seqs[i] + [pad_val] * (max_len - len(seqs[i]))
return (paddle.to_tensor(seqs), paddle.to_tensor(seq_lens)), paddle.to_tensor(labels)
>
> 下面我们自定义一批数据来测试一下collate\_fn函数的功能,这里假定一下max\_seq\_len为5,然后定义序列长度分别为6和3的两条数据,传入collate\_fn函数中。
>
>
>
max_seq_len = 5
batch_data = [[[1, 2, 3, 4, 5, 6], 1], [[2,4,6], 0]]
(seqs, seq_lens), labels = collate_fn(batch_data, pad_val=word2id_dict[“[PAD]”], max_seq_len=max_seq_len)
print("seqs: ", seqs)
print("seq_lens: ", seq_lens)
print("labels: ", labels)
>
> seqs: Tensor(shape=[2, 5], dtype=int64, place=CPUPlace, stop\_gradient=True,
> [[1, 2, 3, 4, 5],
> [2, 4, 6, 0, 0]])
> seq\_lens: Tensor(shape=[2], dtype=int64, place=CPUPlace, stop\_gradient=True,
> [5, 3])
> labels: Tensor(shape=[2], dtype=int64, place=CPUPlace, stop\_gradient=True,
> [1, 0])
>
>
>
可以看到,原始序列中长度为6的序列被截断为5,同时原始序列中长度为3的序列被填充到5,同时返回了非`[PAD]`的序列长度。
接下来,我们将collate\_fn作为回调函数传入DataLoader中, 其在返回一批数据时,可以通过collate\_fn函数处理该批次的数据。 这里需要注意的是,这里通过partial函数对collate\_fn函数中的关键词参数进行设置,并返回一个新的函数对象作为collate\_fn。
在使用DataLoader按批次迭代数据时,最后一批的数据样本数量可能不够设定的batch\_size,可以通过参数drop\_last来判断是否丢弃最后一个batch的数据。
max_seq_len = 256
batch_size = 128
collate_fn = partial(collate_fn, pad_val=word2id_dict[“[PAD]”], max_seq_len=max_seq_len)
train_loader = paddle.io.DataLoader(train_set, batch_size=batch_size, shuffle=True, drop_last=False, collate_fn=collate_fn)
dev_loader = paddle.io.DataLoader(dev_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn)
test_loader = paddle.io.DataLoader(test_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn)
#### 二、模型构建
本实践的整个模型结构如图6.15所示.
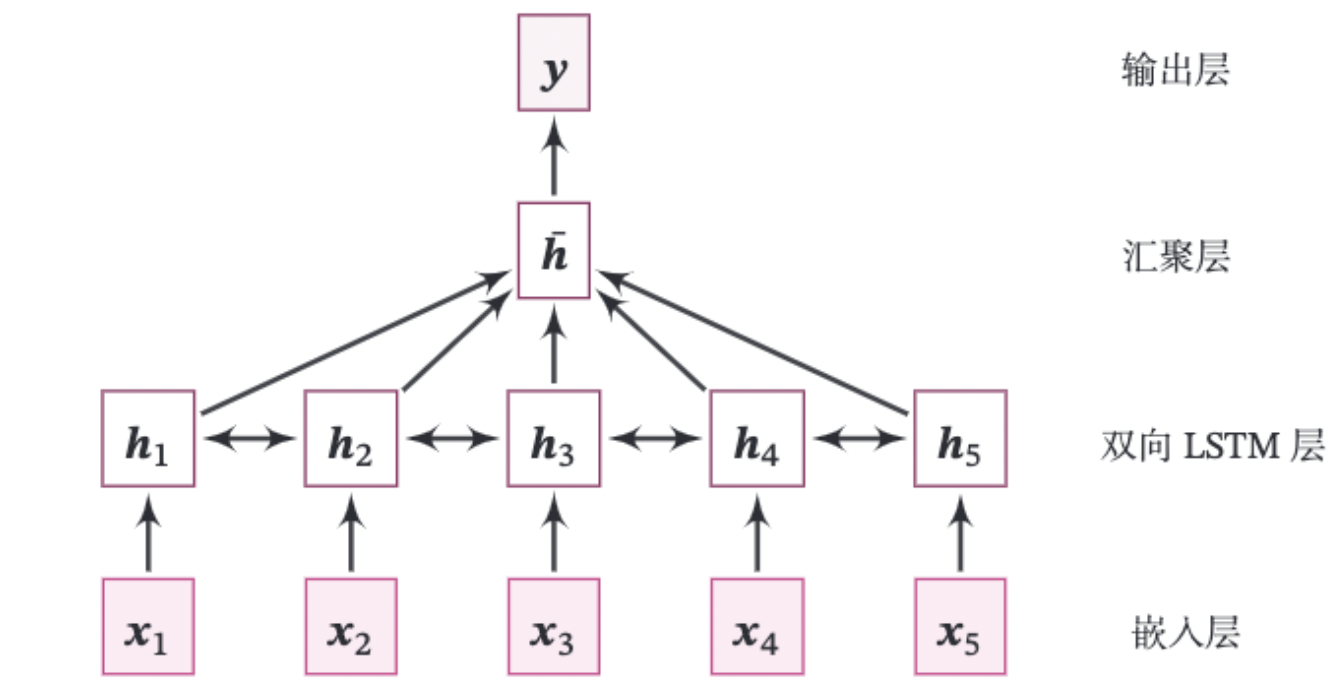
图6.15 基于双向LSTM的文本分类模型结构
由如下几部分组成:
(1)嵌入层:将输入的数字序列进行向量化,即将每个数字映射为向量。这里直接使用飞桨API:paddle.nn.Embedding来完成。
>
> class paddle.nn.Embedding(num\_embeddings, embedding\_dim, padding\_idx=None, sparse=False, weight\_attr=None, name=None)
>
>
>
该API有两个重要的参数:num\_embeddings表示需要用到的Embedding的数量。embedding\_dim表示嵌入向量的维度。
paddle.nn.Embedding会根据[num\_embeddings, embedding\_dim]自动构造一个二维嵌入矩阵。参数padding\_idx是指用来补齐序列的占位符[PAD]对应的词表ID,那么在训练过程中遇到此ID时,其参数及对应的梯度将会以0进行填充。在实现中为了简单起见,我们通常会将[PAD]放在词表中的第一位,即对应的ID为0。
(2)双向LSTM层:接收向量序列,分别用前向和反向更新循环单元。这里我们直接使用飞桨API:paddle.nn.LSTM来完成。只需要在定义LSTM时设置参数direction为bidirectional,便可以直接使用双向LSTM。
>
> 思考: 在实现双向LSTM时,因为需要进行序列补齐,在计算反向LSTM时,占位符[PAD]是否会对LSTM参数梯度的更新有影响。如果有的话,如何消除影响?
> 注:在调用paddle.nn.LSTM实现双向LSTM时,可以传入该批次数据的真实长度,paddle.nn.LSTM会根据真实序列长度处理数据,对占位符[PAD]进行掩蔽,[PAD]位置将返回零向量。
>
>
>
(3)聚合层:将双向LSTM层所有位置上的隐状态进行平均,作为整个句子的表示。
(4)输出层:输出层,输出分类的几率。这里可以直接调用paddle.nn.Linear来完成。
>
> **动手练习6.5**:改进第6.3.1.1节中的LSTM算子,使其可以支持一个批次中包含不同长度的序列样本。
>
>
>
上面模型中的嵌入层、双向LSTM层和线性层都可以直接调用飞桨API来实现,这里我们只需要实现汇聚层算子。需要注意的是,虽然飞桨内置LSTM在传入批次数据的真实长度后,会对[PAD]位置返回零向量,但考虑到汇聚层与处理序列数据的模型进行解耦,因此在本节汇聚层的实现中,会对[PAD]位置进行掩码。
**汇聚层算子**
汇聚层算子将双向LSTM层所有位置上的隐状态进行平均,作为整个句子的表示。这里我们实现了AveragePooling算子进行隐状态的汇聚,首先利用序列长度向量生成掩码(Mask)矩阵,用于对文本序列中[PAD]位置的向量进行掩蔽,然后将该序列的向量进行相加后取均值。代码实现如下:
将上面各个模块汇总到一起,代码实现如下:
class AveragePooling(nn.Layer):
def __init__(self):
super(AveragePooling, self).init()
def forward(self, sequence_output, sequence_length):
sequence_length = paddle.cast(sequence_length.unsqueeze(-1), dtype="float32")
# 根据sequence\_length生成mask矩阵,用于对Padding位置的信息进行mask
max_len = sequence_output.shape[1]
mask = paddle.arange(max_len) < sequence_length
mask = paddle.cast(mask, dtype="float32").unsqueeze(-1)
# 对序列中paddling部分进行mask
sequence_output = paddle.multiply(sequence_output, mask)
# 对序列中的向量取均值
batch_mean_hidden = paddle.divide(paddle.sum(sequence_output, axis=1), sequence_length)
return batch_mean_hidden
**模型汇总**
将上面的算子汇总,组合为最终的分类模型。代码实现如下:
class Model_BiLSTM_FC(nn.Layer):
def __init__(self, num_embeddings, input_size, hidden_size, num_classes=2):
super(Model_BiLSTM_FC, self).init()
# 词典大小
self.num_embeddings = num_embeddings
# 单词向量的维度
self.input_size = input_size
# LSTM隐藏单元数量
self.hidden_size = hidden_size
# 情感分类类别数量
self.num_classes = num_classes
# 实例化嵌入层
self.embedding_layer = nn.Embedding(num_embeddings, input_size, padding_idx=0)
# 实例化LSTM层
self.lstm_layer = nn.LSTM(input_size, hidden_size, direction=“bidirectional”)
# 实例化聚合层
self.average_layer = AveragePooling()
# 实例化输出层
self.output_layer = nn.Linear(hidden_size * 2, num_classes)
def forward(self, inputs):
# 对模型输入拆分为序列数据和mask
input_ids, sequence_length = inputs
# 获取词向量
inputs_emb = self.embedding_layer(input_ids)
# 使用lstm处理数据
sequence_output, _ = self.lstm_layer(inputs_emb, sequence_length=sequence_length)
# 使用聚合层聚合sequence\_output
batch_mean_hidden = self.average_layer(sequence_output, sequence_length)
# 输出文本分类logits
logits = self.output_layer(batch_mean_hidden)
return logits
#### 三、模型训练
本节将基于RunnerV3进行训练,首先指定模型训练的超参,然后设定模型、优化器、损失函数和评估指标,其中损失函数使用`paddle.nn.CrossEntropyLoss`,该损失函数内部会对预测结果使用`softmax`进行计算,数字预测模型输出层的输出`logits`不需要使用softmax进行归一化,定义完Runner的相关组件后,便可以进行模型训练。代码实现如下。
import time
import random
import numpy as np
from nndl import Accuracy, RunnerV3
np.random.seed(0)
random.seed(0)
paddle.seed(0)
指定训练轮次
num_epochs = 3
指定学习率
learning_rate = 0.001
指定embedding的数量为词表长度
num_embeddings = len(word2id_dict)
embedding向量的维度
input_size = 256
LSTM网络隐状态向量的维度
hidden_size = 256
实例化模型
model = Model_BiLSTM_FC(num_embeddings, input_size, hidden_size)
指定优化器
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, beta1=0.9, beta2=0.999, parameters= model.parameters())
指定损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
指定评估指标
metric = Accuracy()
实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
模型训练
start_time = time.time()
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=10, log_steps=10, save_path=“./checkpoints/best.pdparams”)
end_time = time.time()
print("time: ", (end_time-start_time))
>

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
t_time))
[外链图片转存中…(img-cyte5Dgc-1714334414362)]
[外链图片转存中…(img-f6ydHYrn-1714334414362)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









