







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
### 11.2配置主机名
>
> 分别编辑每台虚拟机的hostname文件,直接填写主机名,保存退出即可。
>
>
>
sudo vi /etc/hostname
>
> 第一台主机主机名为: hadoop01
> 第二台主机主机名为:hadoop02
> 第三台主机主机名为: hadoop03
>
>
>
### 11.3 配置每台虚拟机的映射
>
> 分别编辑每台虚拟机的hosts文件,在原有内容的基础上,填下以下内容:
> 注意:不要修改文件原来的内容,三台虚拟机的配置内容都一样。
>
>
>
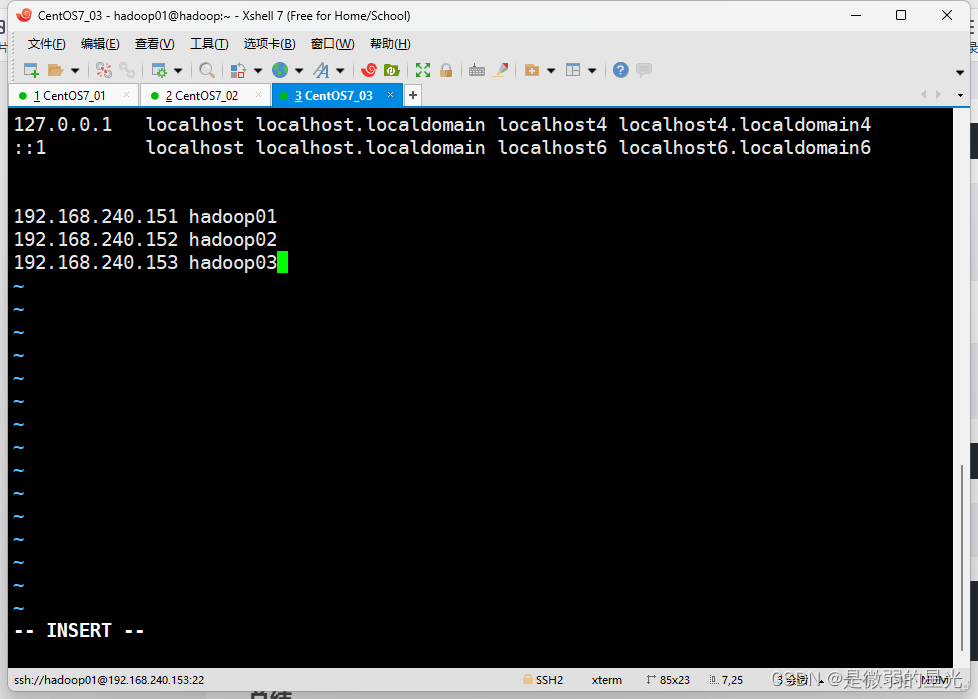
sudo vi /etc/hosts
>
> 添加内容如下:
>
>
>
192.168.240.151 hadoop01
192.168.240.152 hadoop02
192.168.240.153 hadoop03
>
> 效果如图
>
>
>
>
> 重新启动三台主机
>
>
>
---
## 十二、配置免密登录
### 12.1三台主机生成公钥和私钥
>
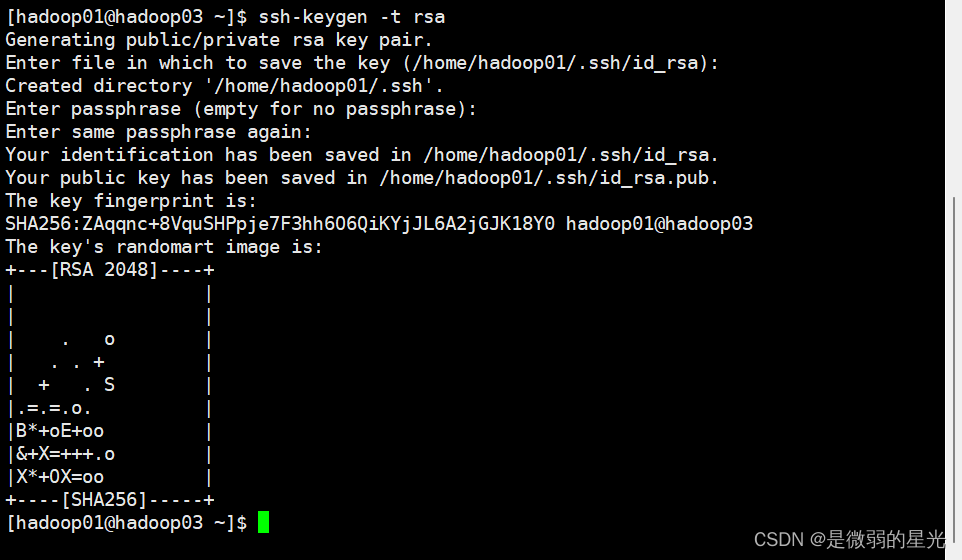
> 在三台机器执行以下命令,生成公钥与私钥
>
>
>
ssh-keygen -t rsa
>
> 执行该命令之后,按下三个回车即可,然后敲(三个回车),就会生成两个文件id\_rsa(私钥)、id\_rsa.pub(公钥)
> 默认保存在/home/hadoop01/.ssh
>
>
>
### 12.2拷贝公钥到同一台机器
>
> 三台机器将拷贝公钥到第一台机器
>
>
>
>
> 三台机器执行命令:
>
>
>
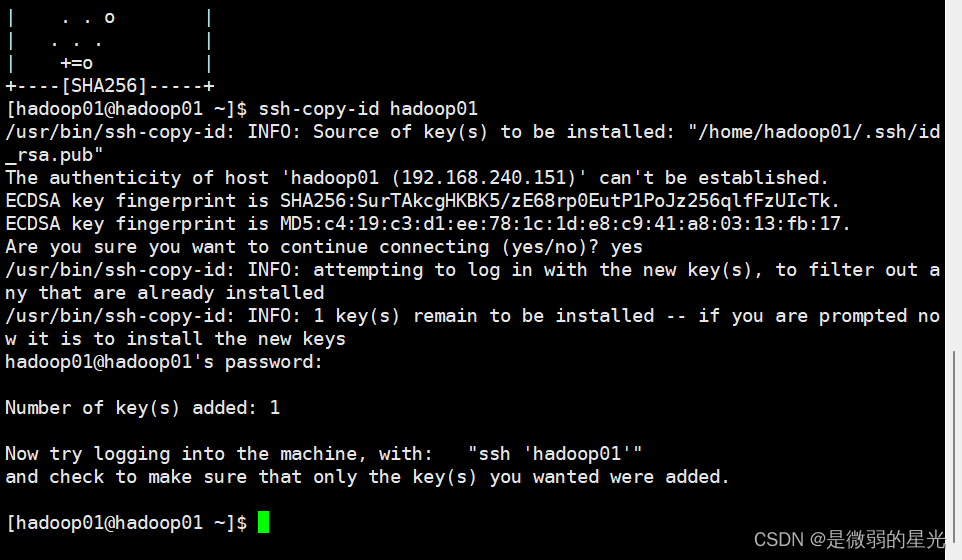
ssh-copy-id hadoop01
>
> 在执行该命令之后,需要输入yes和hadoop01的密码:
>
>
>
### 12.3复制第一台机器的认证到其他机器
>
> 将第一台机器的公钥拷贝到其他机器上
>
>
>
>
> 在第一台机器上指行以下命令
>
>
>
scp /home/hadoop01/.ssh/authorized_keys hadoop02:/home/hadoop01/.ssh
scp /home/hadoop01/.ssh/authorized_keys hadoop03:/home/hadoop01/.ssh
>
> 执行命令时,需要输入yes和对方的密码
>
>
>
### 12.4测试免密登录
>
> 可以在任何一台主机上通过ssh 主机名命令去远程登录到该主机,输入exit退出登录
> 例如:在hadoop01机器上,免密登录hadoop02机器,在hadoop01上输入:
>
>
>
ssh hadoop02
>
> 效果如下:
>
>
>

`注意:这里是不需要输入密码的,如果需要输入密码,则表明你的免密登录设置的有问题`
---
## 十三、配置java
### 13.1使用xftp上传jdk压缩包
>
> 在hadoop01 进入 **/home/hadoop01/software**目录上传 **jdk-8u241-linux-x64.tar.gz**
>
>
>
cd software
### 13.2解压jdk
>
> 解压压缩包到sever目录下:
>
>
>
tar -zxvf jdk-8u241-linux-x64.tar.gz -C ~/server
>
> 查看解压后的目录,目录中有 jdk1.8.0\_241 为 jdk 解压的目录
>
>
>
### 13.3配置环境变量
>
> 打开/etc/profile 配置文件,将下面配置拷贝进去。
> export 命令用于将 shell 变量输出为环境变量
>
>
>
sudo vi /etc/profile
>
> 通过键盘上下键 将光标拉倒最后面
>
>
>
>
> 然后输入 i, 将以下下内容输入即可
>
>
>
#set Javasource
export JAVA_HOME=/home/hadoop01/server/jdk1.8.0_241
export JRE_HOME=
J
A
V
A
H
O
M
E
/
j
r
e
e
x
p
o
r
t
C
L
A
S
S
P
A
T
H
=
.
:
JAVA_HOME/jre export CLASSPATH=.:
JAVAHOME/jreexportCLASSPATH=.:JAVA_HOME/lib:
J
R
E
H
O
M
E
/
l
i
b
:
JRE_HOME/lib:
JREHOME/lib:CLASSPATH
export PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:JRE_HOME/bin:$PATH
>
> 按esc键 然后 :wq 保存退出即可
>
>
>
>
> 重新加载环境变量:
>
>
>
source /etc/profile
>
> 将环境配置加入到/.bashrc
>
>
>
cat /etc/profile >> ~/.bashrc
`#远程ssh执行需要设置~/.bashrc的环境变量。`
`#非登入shell按如下顺序加载配置文件:1:/etc/bashrc 2:~/.bashrc`
### 13.4验证jdk是否安装成功
java -version
>
> 出现以下内容即成功:
>
>
>
[hadoop01@hadoop01 ~]$ java -version
java version “1.8.0_241”
Java™ SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot™ 64-Bit Server VM (build 25.241-b07, mixed mode)
---
## 十四、配置hadoop
### 14.1使用xftp上传hadoop压缩包
>
> 在hadoop01 进入 **/home/hadoop01/software**目录上传 **hadoop-3.3.0-Centos7-64-with-snappy.tar.gz**
>
>
>
cd software
### 14.2解压hadoop
>
> 解压压缩包到sever目录下:
>
>
>
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C ~/server
>
> 查看解压后的目录,目录中有hadoop-3.3.0 为 hadoop解压的目录
>
>
>
### 14.3配置环境变量
>
> 打开/etc/profile 配置文件,将下面配置拷贝进去。
>
>
>
sudo vi /etc/profile
>
> 通过键盘上下键 将光标拉倒最后面
>
>
>
>
> 然后输入 i, 将以下下内容输入即可
>
>
>
#set HadoopSource
export HADOOP_HOME=/home/hadoop01/server/hadoop-3.3.0
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
>
> 按esc键 然后 :wq 保存退出即可
>
>
>
>
> 重新加载环境变量:
>
>
>
source /etc/profile
>
> 将环境配置加入到/.bashrc
>
>
>
cat /etc/profile >> ~/.bashrc
### 14.4验证是否安装成功
whereis hdfs
>
> 出现以下内容即配置成功:
>
>
>
[hadoop01@hadoop01 ~]$ whereis hdfs
hdfs: /home/hadoop01/server/hadoop-3.3.0/bin/hdfs /home/hadoop01/server/hadoop-3.3.0/bin/hdfs.cmd
### 14.5修改hadoo配置文件
>
> 配置文件在 **/home/hadoop01/server/hadoop-3.3.0/etc/hadoop** 目录下
>
>
>
>
> 以下配置根据需要添加
>
>
>
#### 14.5.1core-site.xml
>
> 在 **/home/hadoop01/server/hadoop-3.3.0/** 目录下创建**tmp**文件夹
>
>
>
cd server/hadoop-3.3.0/
mkdir tmp
>
> 配置文件内容:
>
>
>
#### 14.5.2hdfs-site.xml
#### 14.5.3yarn-site.xml
#### 14.5.4mapred-site.xml
#### 14.5.5workers
>
> 删除原有内容,添加以下内容:
>
>
>
hadoop01
hadoop02
hadoop03
---
## 十五、分发文件到其他节点
### 15.1分发server下的所有文件到其他节点
scp -r /home/hadoop01/server hadoop01@hadoop02:/home/hadoop01/
scp -r /home/hadoop01/server hadoop01@hadoop03:/home/hadoop01/
### 15.2分发环境配置文件
scp ~/.bashrc hadoop02:~/.bashrc
scp ~/.bashrc hadoop03:~/.bashrc
>
> 分别在hadoop02与hadoop03中输入以下代码,是环境变量生效:
>
>
>
source ~/.bashrc
---
## 十六、格式化namenode
>
> 输入以下命令:
>
>
>
hdfs namenode -format
---
## 十七、启动hadoop
### 17.1启动hdfs
start-dfs.sh
### 17.2启动yarn
start-yarn.sh
### 17.3开启historyserver
mapred --daemon start historyserver
### 17.4一键启动
start-all.sh
### 17.5单个节点启动
[hadoop01@hadoop01 server]# hdfs --daemon start namenode
[hadoop01@hadoop01 server]# hdfs --daemon start datanode
[hadoop01@hadoop01 server]# yarn --daemon start resourcemanager
[hadoop01@hadoop01 server]# yarn --daemon start nodemanager
[hadoop01@hadoop01 server]# mapred --daemon start historyserver
[hadoop01@hadoop02 ~]# hdfs --daemon start secondarynamenode
[hadoop01@hadoop02 ~]# yarn --daemon start nodemanager
[hadoop01@hadoop02 ~]# hdfs --daemon start datanode
[hadoop01@hadoop03 ~]# yarn --daemon stop nodemanager
[hadoop01@hadoop03 ~]# hdfs --daemon stop datanode
---
## 十八、测试
### 18.1查看进程
[hadoop01@hadoop01 ~]$ jps
30210 DataNode
30661 NodeManager
30524 ResourceManager
30047 NameNode
31695 Jps
[hadoop01@hadoop02 ~]$ jps
29762 DataNode
30306 Jps
29976 NodeManager
29883 SecondaryNameNode
[hadoop01@hadoop03 ~]$ jps
29595 NodeManager
29471 DataNode
29903 Jps
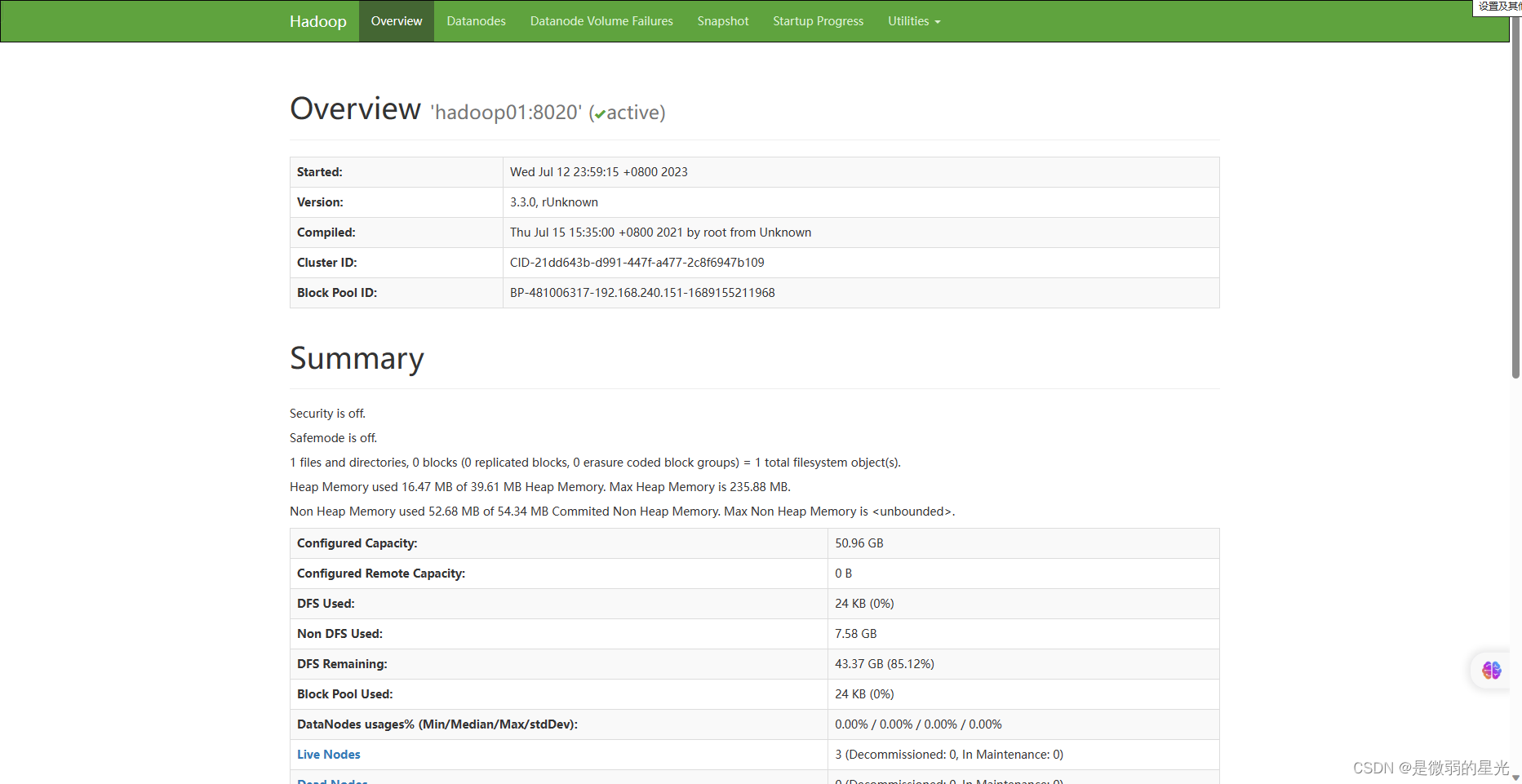
### 18.2HDFS界面
>
> http://192.168.240.151:
>
>
>
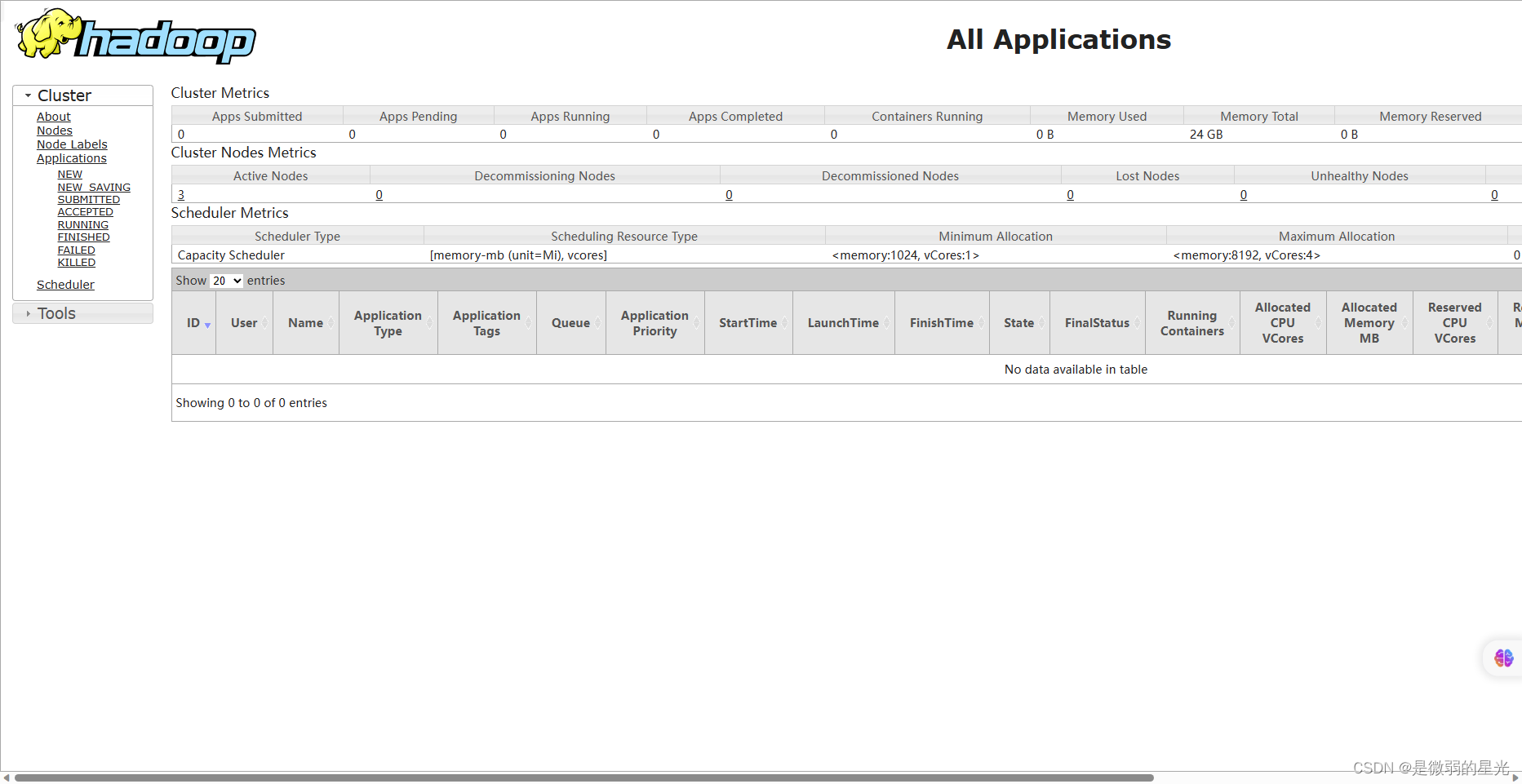
### 18.3YARN界面
>
> http://192.168.240.151:8088
>
>
>
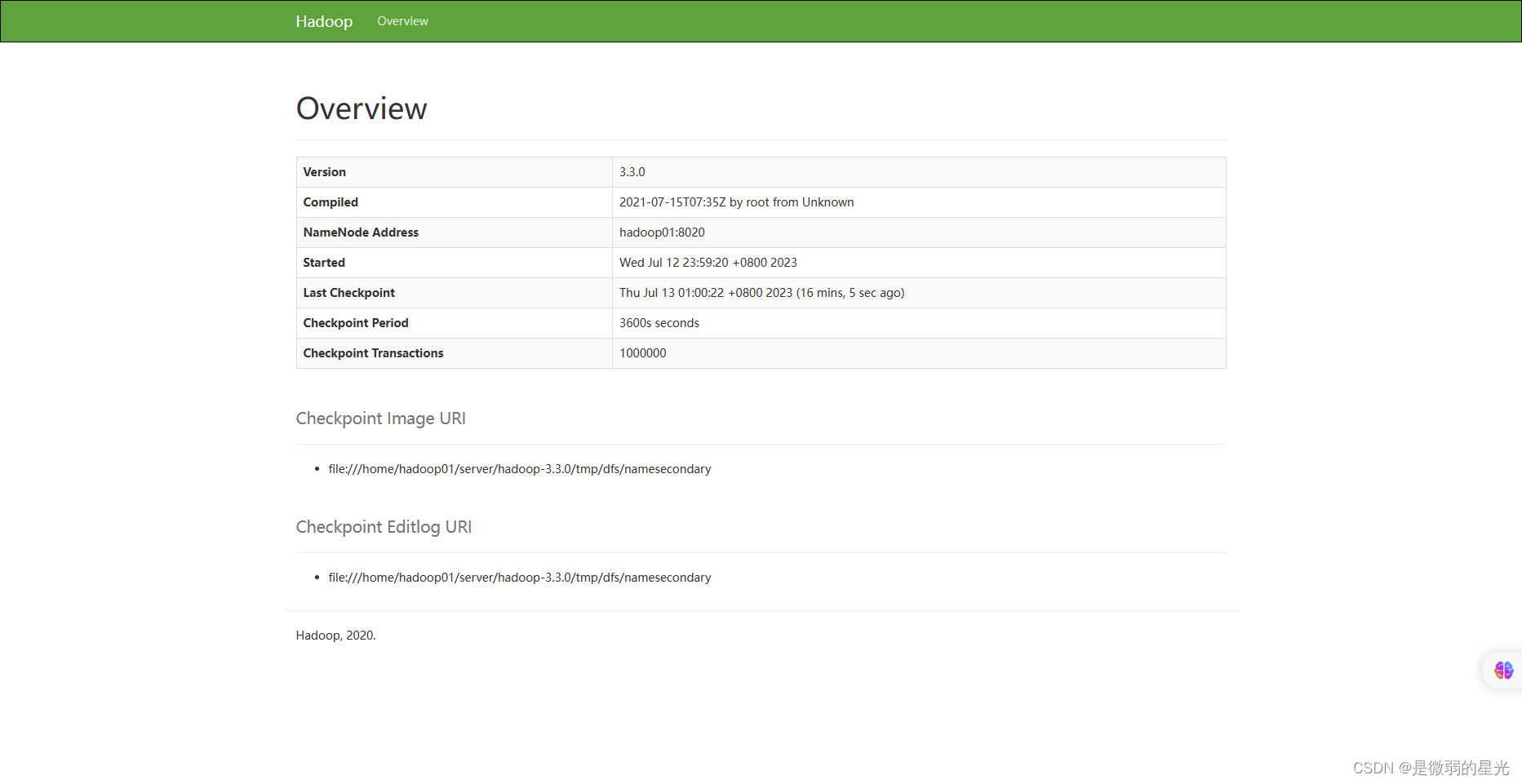
### 18.4MR界面
>
> http://192.168.240.152:9868
>
>
>
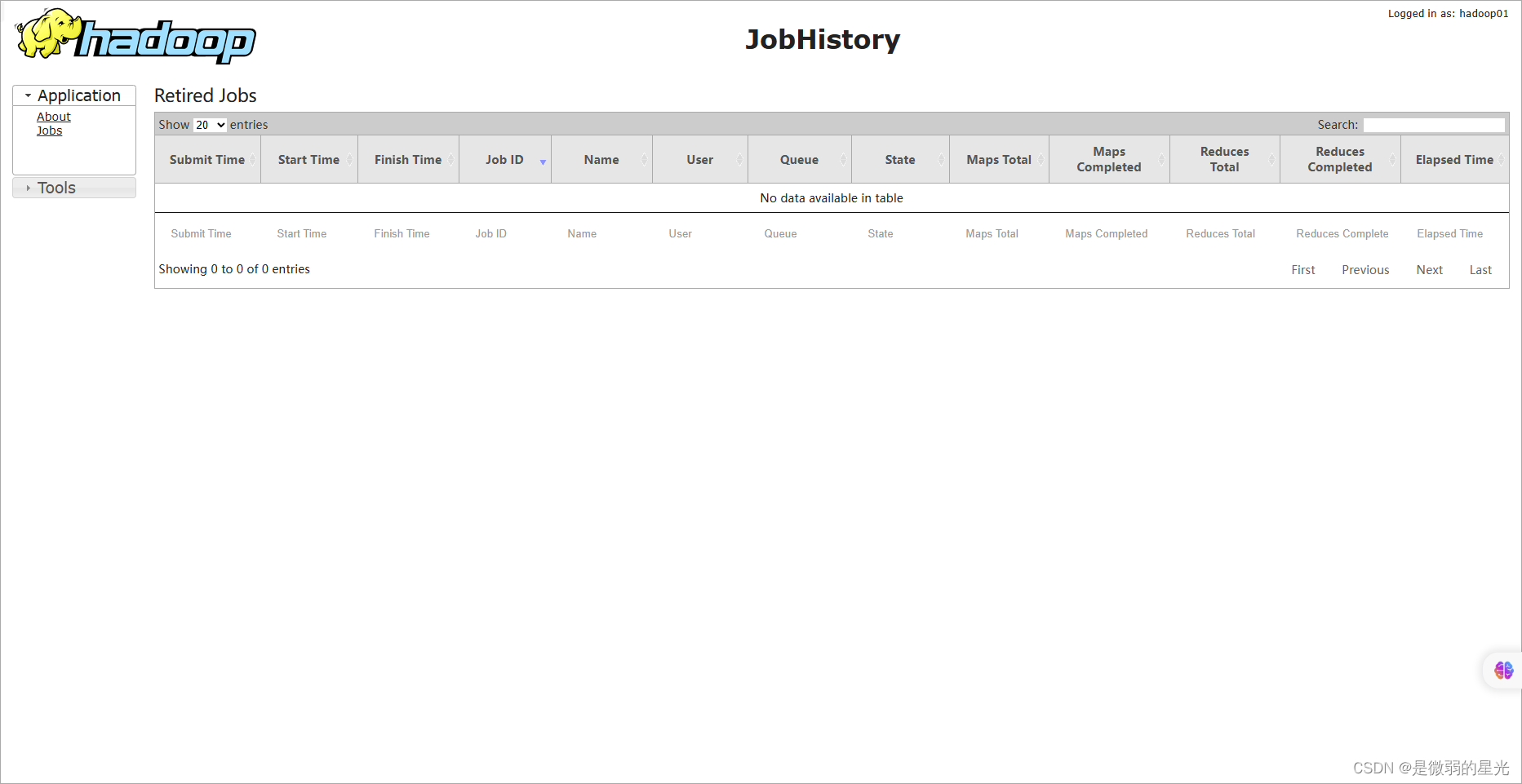
### 18.5historyserver
>
> http://192.168.240.151:19888
>
>
>
---
## 十九、关闭hadoop
### 19.1关闭hdfs
stop-dfs.sh
### 19.2关闭yarn
stop-yarn.sh
### 19.3关闭historyserver
mapred --daemon stop historyserver
### 19.4一键关闭
stop-all.sh

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
40.151:8088

18.4MR界面
http://192.168.240.152:9868

18.5historyserver
http://192.168.240.151:19888

十九、关闭hadoop
19.1关闭hdfs
stop-dfs.sh
19.2关闭yarn
stop-yarn.sh
19.3关闭historyserver
mapred --daemon stop historyserver
19.4一键关闭
stop-all.sh
[外链图片转存中...(img-IF1r56kW-1715630857697)]
[外链图片转存中...(img-60UUUcsR-1715630857697)]
[外链图片转存中...(img-dZ3rULh7-1715630857697)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**














 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









