







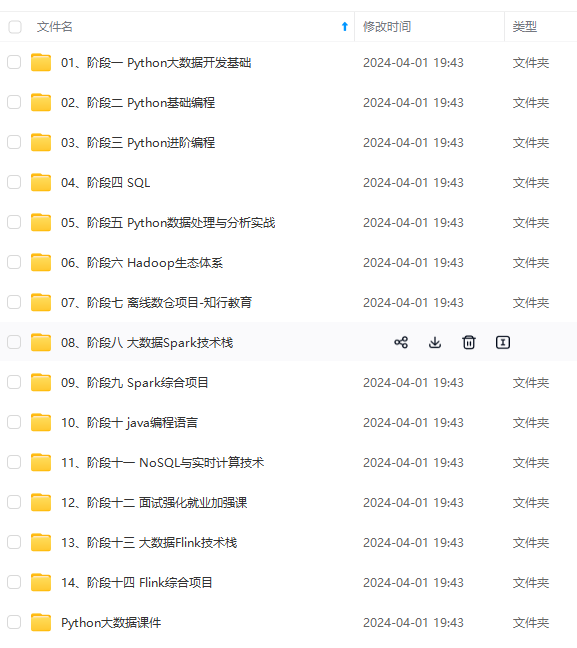
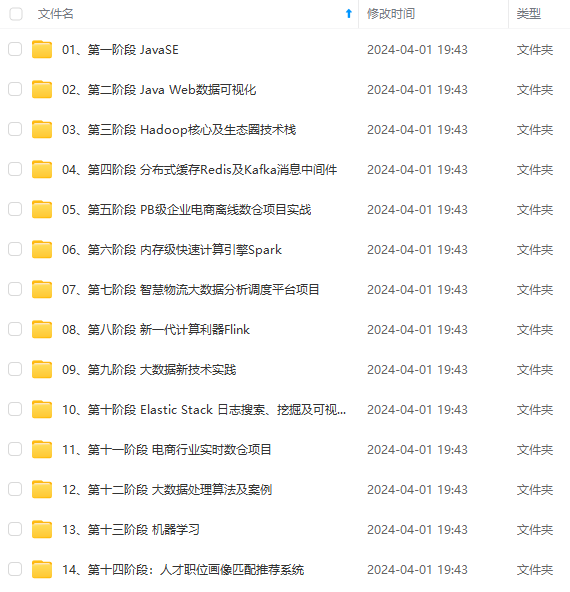
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
1 Kafka基础面试篇
Kafka的那些设计让它有如此高的性能?
- 1.partition,producer和consumer端的批处理:提高并行度;
- 2.页缓存:大量使用页缓存,内存操作比磁盘操作快很多,数据写入直接写道页缓存,由操作系统负责刷盘,数据读取也是直接命中页缓存,从内存中直接拿到数据;
- 3.零拷贝:如果数据读取命中了页缓存,数据会从页缓存直接发送到网卡进行数据传输,省略了用户态和内核态的切换以及多次的数据拷贝;
- 4.顺序读写:Kafka的数据是顺序追加的,避免了低效率的随机读写;
- 5.优秀的文件存储机制:分区规则设置合理的话,所有消息都可以均匀的分不到不同分区,分区日志还可以分段,相当于举行文件被平均分配为多个相对较小的文件,便于文件维护和清理;
- 索引文件:Kafka含有.index和.timeindex索引,以稀疏索引的方式进行构造,查找时可以根据二分法在索引文件中快速定位到目标数据附近位置,然后再.log文件中顺序读取到目标数据;
Kafka的那些设计让它有如此高的性能:分区,顺序写磁盘,0-copy,稀疏索引利用二分查找找到对应数据,批量文件压缩
-
Kafka的用途有哪些?使用场景如何?
- 异步处理,发送短信
- 应用解耦
- 流量削锋
- 日志处理
- 消息通讯
-
Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
- ISR :In-Sync Replicas 副本同步队列
- AR :Assigned Replicas 所有副本
- ISR是由leader维护,follower从leader同步数据有一些延迟(包括 延迟时间replica.lag.time.max.ms 和 延迟条数replica.lag.max.message 两个维度,当前最新的版本0.10.x中只支持 replica.lag.time.max.ms 这个维度),任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。
注:AR = ISR + OSR
-
Kafka中的HW、LEO、LSO、LW等分别代表什么?
- 在Kafka中,HW(High Watermark)表示消费者可见的最高偏移量,
- LEO(Log End Offset)表示当前分区的最高偏移量,
- LSO(Log Start Offset)表示当前分区的最低偏移量,

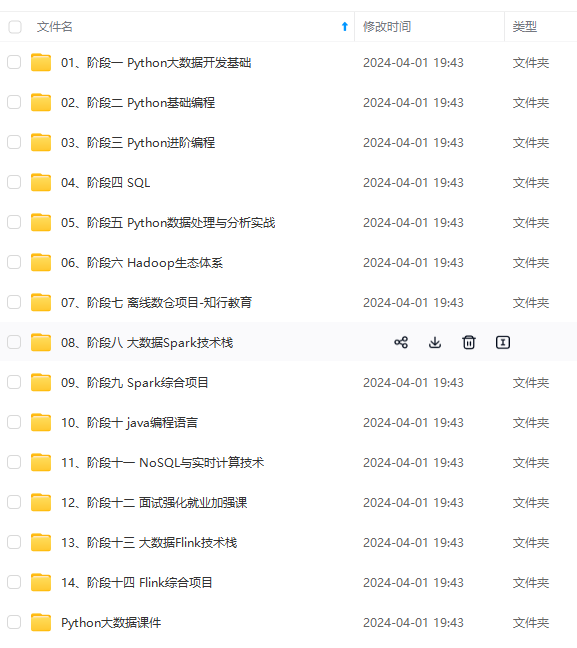
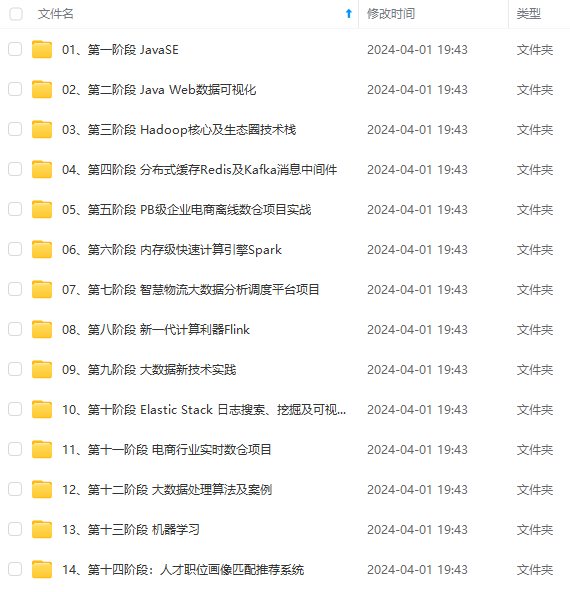
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









