







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
把一个文件追加到另一个文件尾部,因为HDFS只适合文件的追加。
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
把一个文件从HDFS复制到本地
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
显示目录信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
显示文件内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
创建文件夹
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
从HDFS的一个路径拷贝到HDFS的另外一个路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
在 HDFS 目录中移动文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
显示一个文件的末尾 1kb 的数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
删除文件或文件夹
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
递归删除目录及目录里面内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
-du 统计文件夹的大小信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
设置 HDFS 中文件的副本数量
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt
HDFS的写数据流程
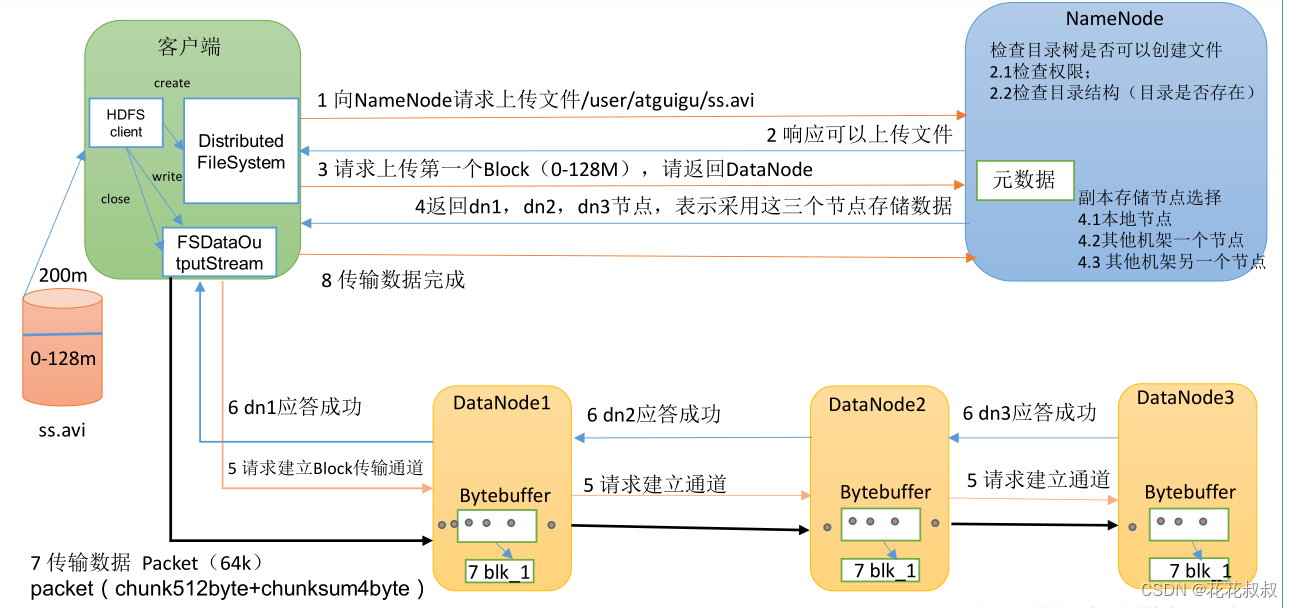
- 要将ss.avi上传到HDFS中,客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在。
- NameNode 返回是否可以上传。(没有的话就可以上传啦)
- 客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
- NameNode 返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3。(dn1,dn2,dn3这三个dn存三份儿数据)
- 客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。(先建立管道通信)
- dn1、dn2、dn3 逐级应答客户端。(返回消息的管道确立)
- 客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet会放入一个应答队列等待应答。
- 当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)。
网络拓扑- 节点距离计算
节点距离就是NameNode通过计算要将数据存储到哪几个DataNode当中,选择最优的DataNode。
节点距离:两个节点到达最近的共同祖先的距离总和。

机架感知
这个就是副本存储数据的选择,在很多的DataNode当中,选择较合适的DataNode存储副本。
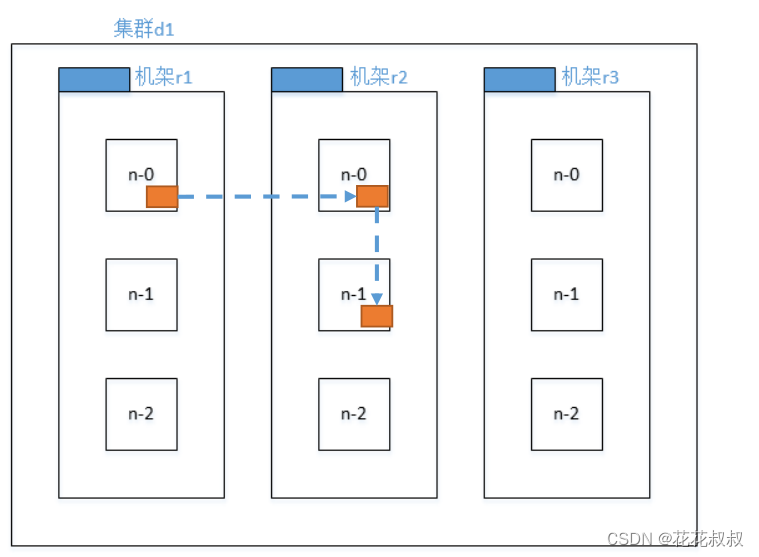
第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本在另一个机架的随机一个节点。
第三个副本在第二个副本所在机架的随机节点。
HDFS的读数据流程

(1)客户端通过 DistributedFileSystem 向 NameNode 请求下载文件,NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
(2)挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。串行传输的。
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









