







UUID虽然能够保证全局主键ID的唯一性,但是UUID并不具有有序性,会导致B+树索引在写的时候有过多的随机写操作(连续的ID会产生部分的顺序写);另外,由于在写的时候不能产生有顺序的append操作,而需要进行insert操作,将会读取整个B+树节点加到内存中,在插入这条记录后将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显。
(2)ID分组
虽然,UUID很方便,但由于他的一些弊端我们无法接受,所以在很多对一些性能要求较高的业务场景中,我们是很少使用UUID的,那我们还有没有什么其他方法哪?接下来让我们看一下ID分组的使用:

如上图所述,由1个数据库变成4个库,每个数据库设置不同的auto_increment初始值init,以及相同的增长步长step,以保证每个数据库生成的ID是不同的,改进后的架构保证了可用性,但缺点是:
- 丧失了ID生成的“绝对递增性”,但这个问题不大,我们的目标是趋势递增,不是绝对递增;
- 数据库的写压力依然很大,每次生成ID都要访问数据库;
- 可扩展性差;
我们可以想象的是,目前虽然我们的机器只有4台,然后由不同的init和不同的step,但是如果我们需要在其中再加一台机器的话,可想而知我们需要手动更新init和step,这是一件比较繁琐的事情!但有人可能会说了,我们可以直接把 step设置大一些,假如,我们预期数据最大规模的时候用100台数据库服务器就可以了,那我们就可以设置step为100。尽管如此,扩展性还不是很高!
3、还有什么操作哪?
上述我们讨论了一个一个的优缺点,当然,还有很多其他的主键ID生成方案。但总的来说,我们讨论问题的关键浮出水面:如何高效生成趋势有序的全局唯一ID,兼顾有序性、高性能、可扩展等因素!
这就需要我们今天的主角登场了,他就是:ID发号器!ID发号器的主要思想大致相同,但不同平台的实现方式可能会有所不同,本文主要介绍一下:Twitter公司的SnowFlake、如何自己实现一个ID发号器、Vesta框架。
三、SnowFlake简介
Twitter公司的SnowFlake算法就是著名的《雪花算法》,SnowFlake是通过Scala语言实现的,目前GitHub上已经看不到源代码了,只有一个2010年的版本,地址为:https://github.com/twitter/snowflake/releases/tag/snowflake-2010,因此很难在我们实际的项目中真正的使用到 ,我们更多的是采用雪花算法的思想,去构建自己属于自己的ID发号器。
1、SnowFlake原理
SnowFlake产生的ID是一个64位的整型,结构如下(每一部分用“-”符号分隔):
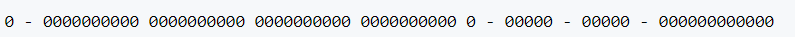
(1)1位:标识部分,在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以为0;
(2)41位:时间戳部分,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4598
4598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









