







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
for(int i = 0;i < 100000;i++){
set.add(i + 1);
}
long start = System.currentTimeMillis();
for(int j = 1; j<=100000;j++) {
int temp = j;
boolean contains = set.contains(temp);
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start)); //time: 5
}
### Hash结构效率高,那为什么索引结构要设计成树型呢?
>
>
> **于排序查询的SQL需求: 分组:group by 排序:order by 比较:**
>
>
> **哈希型的索引,[时间复杂度](https://bbs.csdn.net/topics/618545628)会退化为O(n),而树型的“有序”特性,依然能够保持O(log(n)) 的高效率。 任何脱离需求的设计都是耍流氓。 多说一句,InnoDB并不支持哈希索引。**
>
>
>
**Hash索引适用存储引擎如表所示:**

**Hash索引的适用性:**

**采用自适应 Hash 索引目的是方便根据 SQL 的查询条件加速定位到叶子节点,特别是当 B+ 树比较深的时 候,通过自适应 Hash 索引可以明显提高数据的检索效率。**
**我们可以通过 innodb\_adaptive\_hash\_index 变量来查看是否开启了自适应 Hash,比如:**
show variables like ‘%adaptive_hash_index’;

### 二叉搜索树
**如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。**
**1. 二叉搜索树的特点**
**2. 查找规则**
****
**创造出来的二分搜索树如下图所示:**
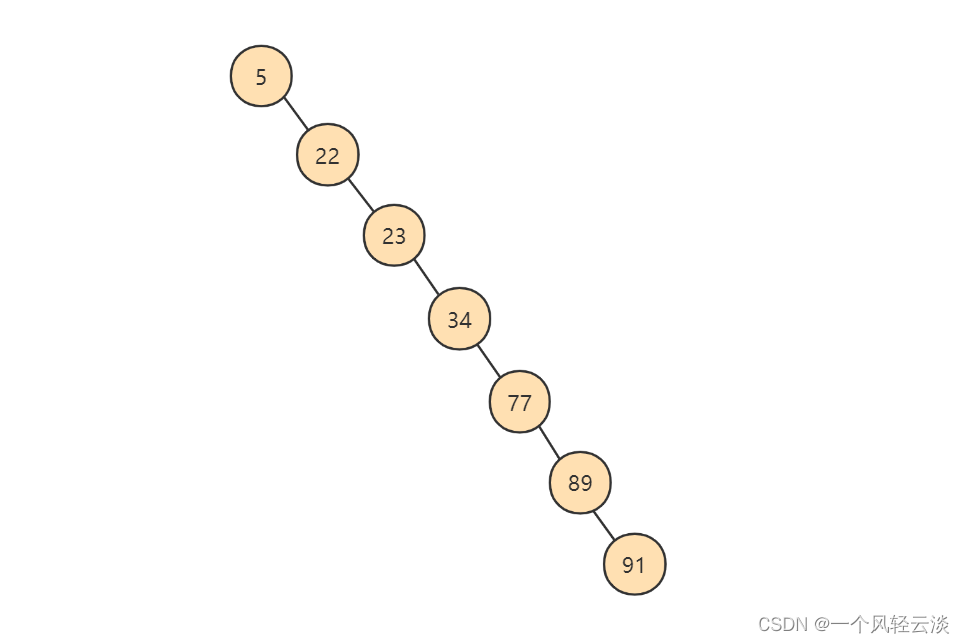
**为了提高查询效率,就需要 减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量 降低树的高度 ,需要把 原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。**
### AVL树
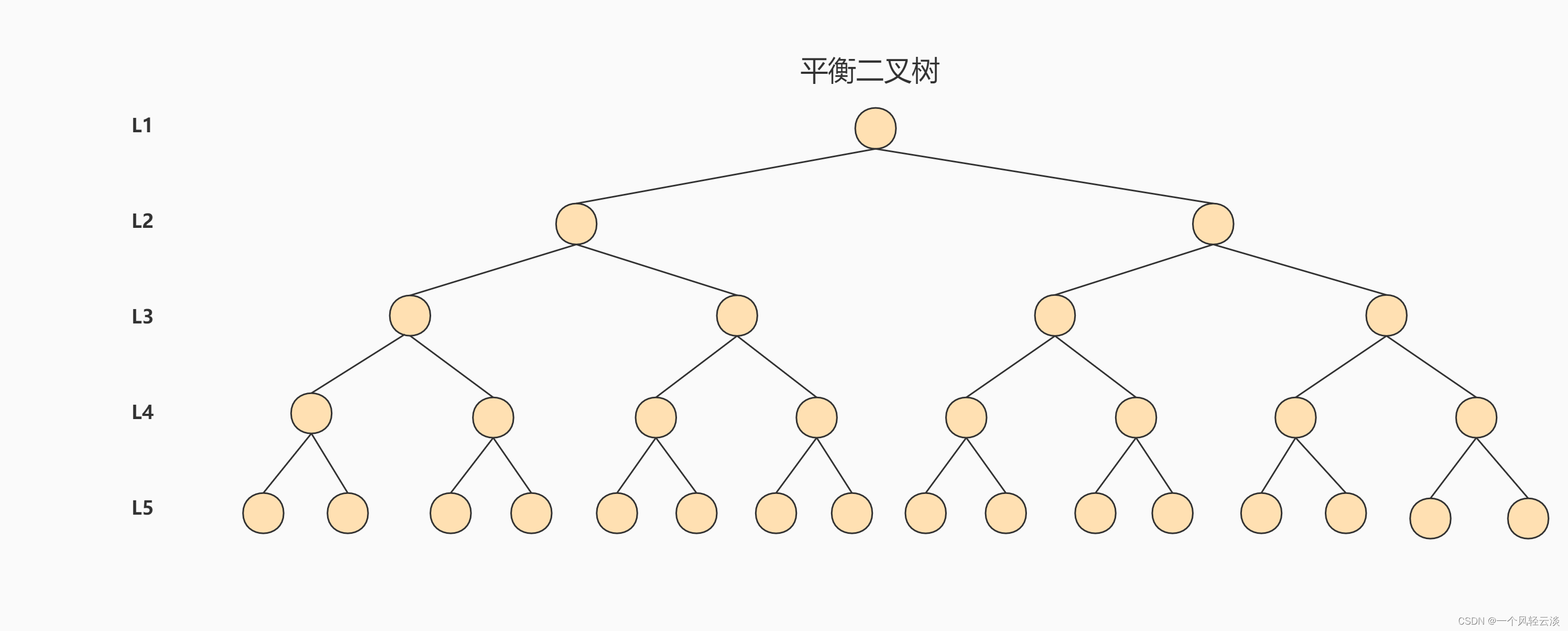
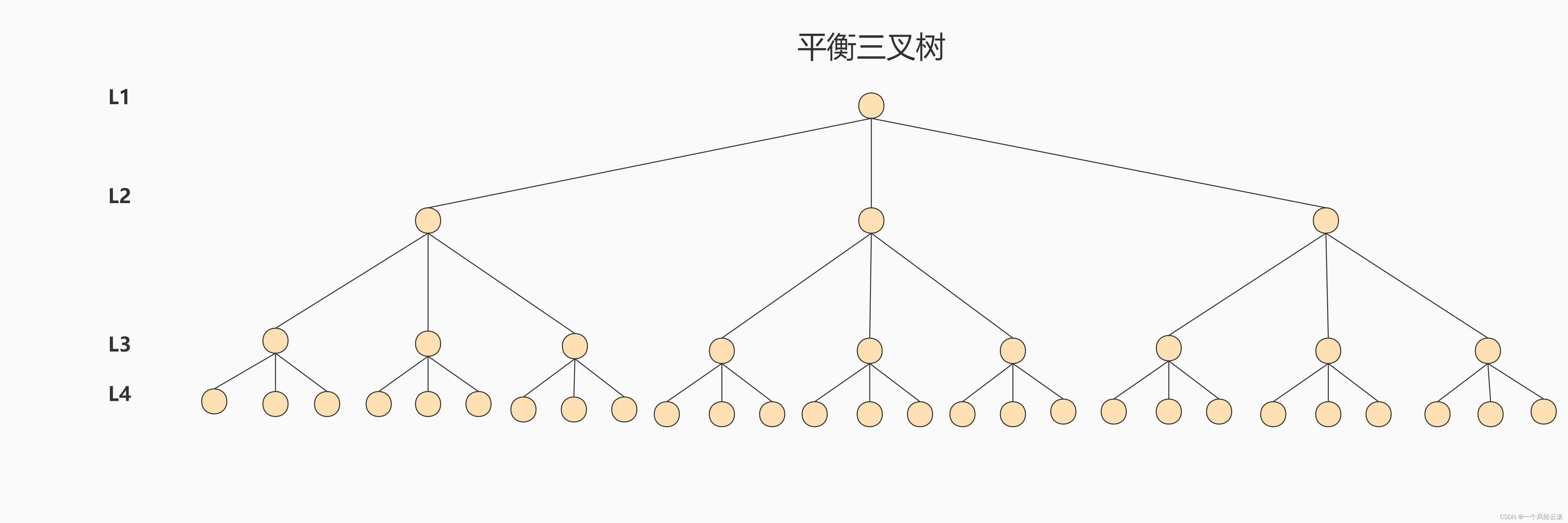
**针对同样的数据,如果我们把二叉树改成 M 叉树 (M>2)呢?当 M=3 时,同样的 31 个节点可以由下面 的三叉树来进行存储:**
### B-Tree
**B 树的结构如下图所示:**
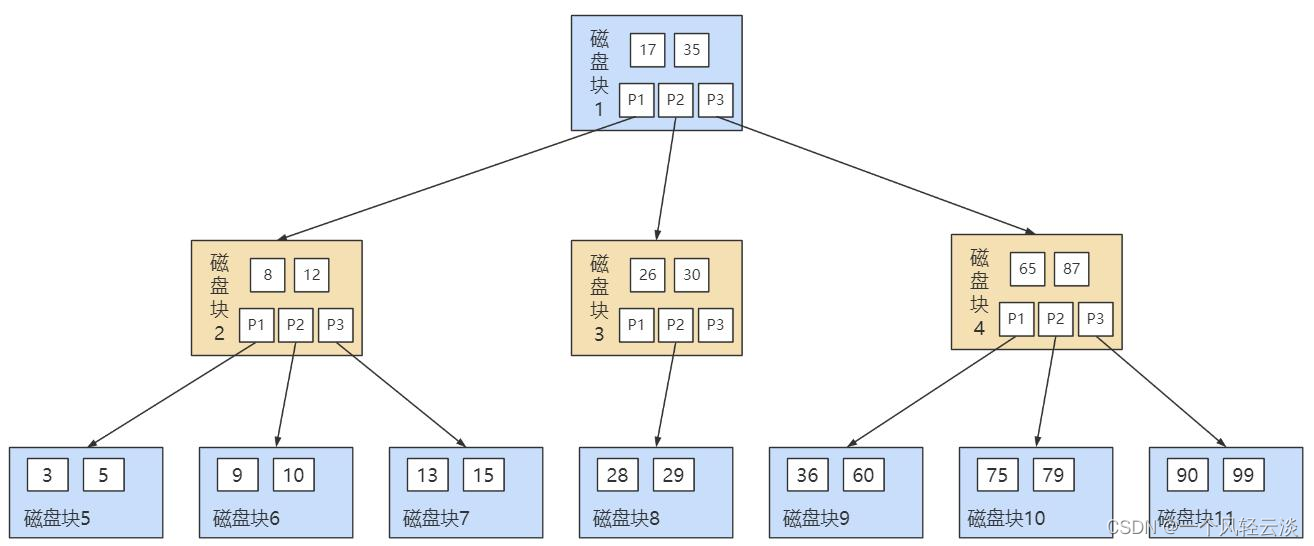
**一个 M 阶的 B 树(M>2)有以下的特性:**
**1. 根节点的儿子数的范围是 [2,M]。**
**2. 每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为**
**[ceil(M/2), M]。**
**3. 叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为 [ceil(M/2), M]。**
**4. 假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i] 。此时 k-1 个关键字相当于划分了 k 个范围,也就是对应着 k 个指针,即为:P[1], P[2], …,P[k],其中 P[1] 指向关键字小于 Key[1] 的子树,P[i] 指向关键字属于 (Key[i-1], Key[i]) 的子树,P[k]**
**指向关键字大于 Key[k-1] 的子树。**
**5. 所有叶子节点位于同一层。 上面那张图所表示的 B 树就是一棵 3 阶的 B 树。我们可以看下磁盘块 2,里面的关键字为(8,12),它 有 3 个孩子 (3,5),(9,10) 和 (13,15),你能看到 (3,5) 小于 8,(9,10) 在 8 和 12 之间,而 (13,15)大于 12,刚好符合刚才我们给出的特征。 然后我们来看下如何用 B 树进行查找。假设我们想要 查找的关键字是 9 ,那么步骤可以分为以下几步:**
* **1. 我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;**
* **2. 按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;**
* **3. 按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。**
**你能看出来在 B 树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后在内存中进行比 较,这个时间就是可以忽略不计的。而读取磁盘块本身需要进行 I/O 操作,消耗的时间比在内存中进行 比较所需要的时间要多,是数据查找用时的重要因素。 B 树相比于平衡二叉树来说磁盘 I/O 操作要少 , 在数据查询中比平衡二叉树效率要高。所以 只要树的高度足够低,IO次数足够少,就可以提高查询性能 。**
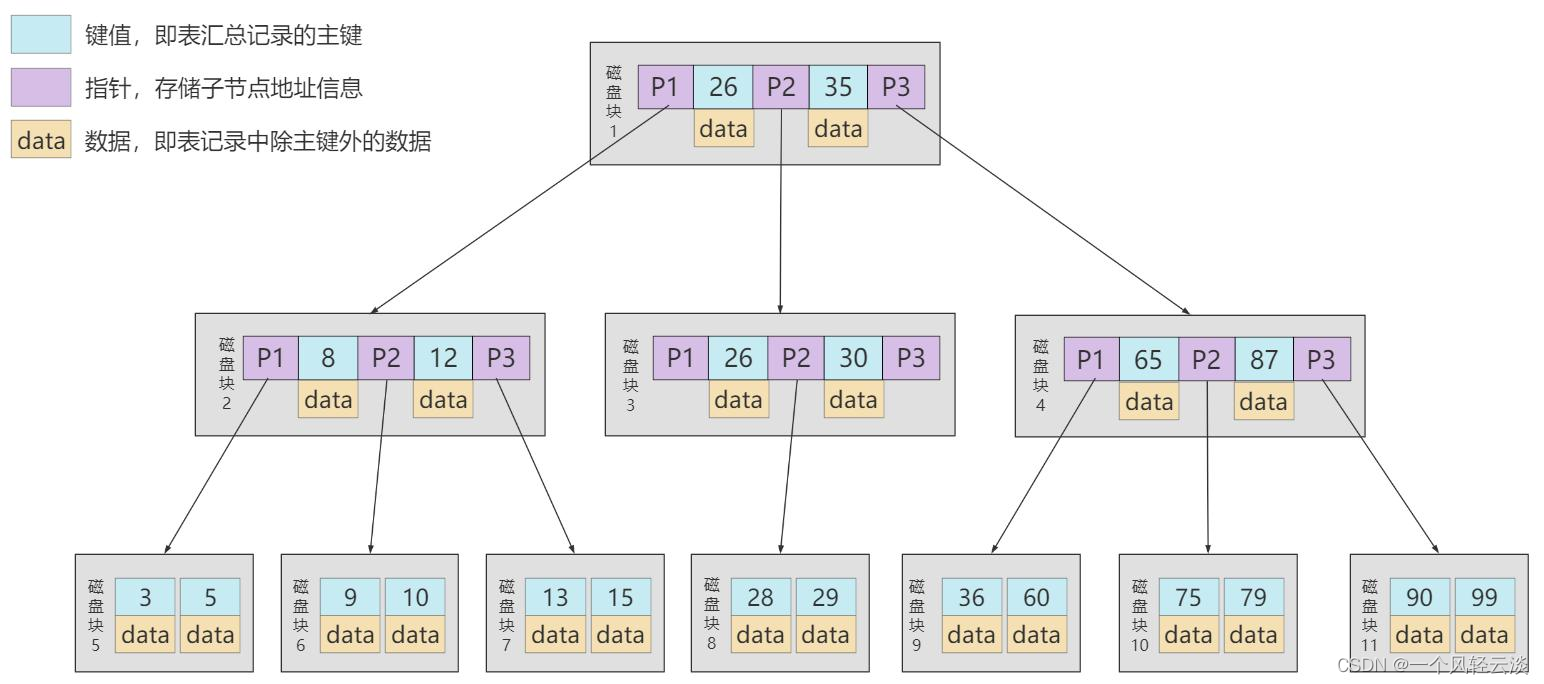
### B+Tree

**B+ 树和 B 树的差异:**



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 2697
2697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









