







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
| 2 | elasticsearch_indices_search_query_time_seconds | counter | 查询总时间 性能 |
| 3 | elasticsearch_indices_search_fetch_total | counter | 提取总数 |
| 4 | elasticsearch_indices_search_fetch_time_seconds | counter | 花费在提取上的总时间 |
| 5 | elasticsearch_indices_get_time_seconds | counter | GET请求总时间 |
| 6 | elasticsearch_indices_get_missing_total | counter | 丢失的文件的GET请求总数 |
| 7 | elasticsearch_indices_get_missing_time_seconds | counter | 花费在文档丢失的GET请求上的总时间 |
| 8 | elasticsearch_indices_get_exists_time_seconds | counter | 花费在文档存在的GET请求上的总时间 |
| 9 | elasticsearch_indices_get_exists_total | counter | 存在的文件的GET请求总数 |
| 10 | elasticsearch_indices_get_total | counter | GET请求总次数 |
2.2 索引性能指标
ES 写入流程介绍
ES 的任意节点都可以作为协调节点(coordinating node)接受请求,当协调节点接受到请求后进行一系列处理,然后通过_routing 字段找到对应的 primary shard,并将请求转发给 primary shard, primary shard 完成写入后,将写入并发发送给各 replica, raplica 执行写入操作后返回给 primary shard, primary shard 再将请求返回给协调节点。大致流程如下图:
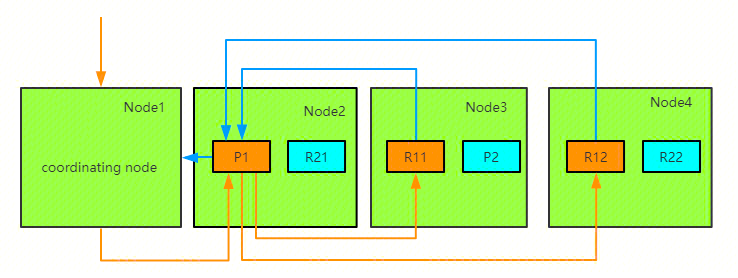
整体写入流程如下图所示:
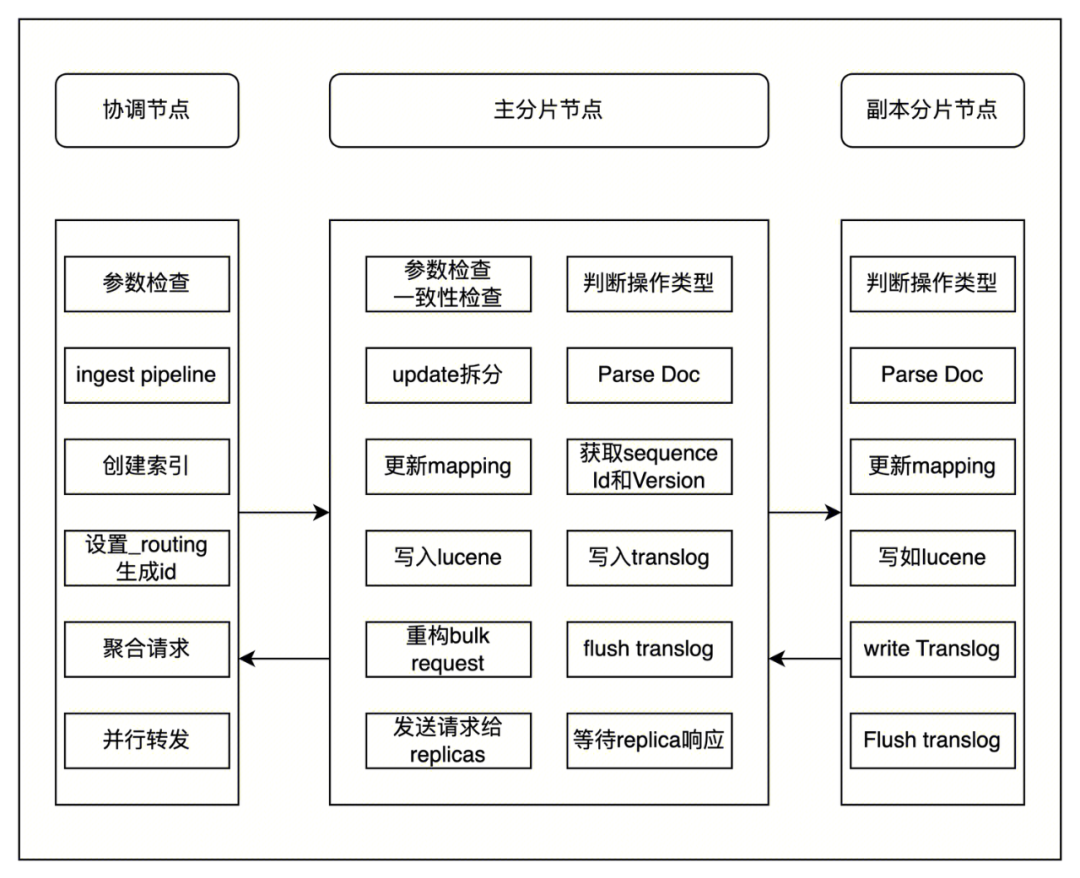
说明
近实时性-refresh 操作:当一个文档写入 Lucene 后是不能被立即查询到的,ElasticSearch 提供了一个 refresh 操作,会定时地调用 Lucene 的 reopen (新版本为 openIfChanged)为内存中新写入的数据生成一个新的 Segment,此时被处理的文档均可以被检索到。refresh 操作的时间间隔由 refresh_interval 参数控制,默认为1s, 当然还可以在写入请求中带上 refresh 表示写入后立即 refresh,另外还可以调用 refresh API 显式 refresh。
merge 操作:由于 refresh 默认间隔为1s,因此会产生大量的小 Segment,为此 ES 会运行一个任务检测当前磁盘中的 Segment,对符合条件的 Segment 进行合并操作,减少 Lucene 中的 Segment 个数,提高查询速度,降低负载。不仅如此,merge 过程也是文档删除和更新操作后,旧的 Doc 真正被删除的时候。用户还可以手动调用 _forcemerge API 来主动触发 merge,以减少集群的 Segment 个数和清理已删除或更新的文档。
Translog:当一个文档写入 Lucence 后是存储在内存中的,即使执行了 refresh 操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此 ES 增加了 Translog。
当进行文档写操作时会先将文档写入 Lucene,然后写入一份到 Translog,写入 Translog 是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置 index.Translog.durability 和 index.Translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。由于 Translog 是追加写入,因此性能比较好。与传统的分布式系统不同,这里是先写入 Lucene 再写入 Translog,原因是写入 Lucene 可能会失败,为了减少写入失败回滚的复杂度,因此先写入 Lucene。
flush 操作:每30分钟或当Translog 达到一定大小(由index.Translog.flush_threshold_size 控制,默认512mb), ES 会触发一次 flush 操作,此时 ES 会先执行 refresh 操作将 buffer 中的数据生成 Segment,然后调用 Lucene 的 commit 方法将所有内存中的 Segment fsync 到磁盘。此时 Lucene 中的数据就完成了持久化,会清空 Translog 中的数据(6.x版本为了实现 sequenceIDs,不删除 Translog)。
相关指标
根据上述流程可知,对于一个写入较为频繁的系统,refresh 和 flush 操作相关的指标较为重要,merge 相关的指标也需要关注,同时整个写入的耗时,搜索文档总数也需要关注,故而需要关注的写入相关指标为:
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_indices_indexing_index_total | counter | 被索引的文档总数 |
| 2 | elasticsearch_indices_indexing_index_time_seconds_total | counter | 索引文档花费的总时间 |
| 3 | elasticsearch_indices_refresh_total | counter | 索引refresh的总数 |
| 4 | elasticsearch_indices_refresh_time_seconds_total | counter | refresh索引总共话费的时间 |
| 5 | elasticsearch_indices_flush_total | counter | flush索引到磁盘的总数 |
| 6 | elasticsearch_indices_flush_time_seconds | counter | flush索引到磁盘的总花费时间 |
| 7 | elasticsearch_indices_merges_total | counter | Total merges(merge操作总次数) |
| 8 | elasticsearch_indices_merges_total_time_seconds_total | counter | 索引merge操作总花费时间 |
| 9 | elasticsearch_indices_merges_Docs_total | counter | merge的文档总数 |
| 10 | elasticsearch_indices_merges_total_size_bytes_total | counter | merge的数据量合计 |
| 11 | elasticsearch_indices_indexing_delete_total | counter | 索引的文件删除总数 |
| 12 | elasticsearch_indices_indexing_delete_time_seconds_total | counter | 索引的文件删除总时间 |
2.3 内存使用和垃圾回收指标
ES 是使用 Java 进行编写,运行在 JVM 之上,故而 ES 会以两种方式使用节点上的全部可用内存:JVM 堆和文件系统缓存(file system cache),因此,在 ES 运行期间,整个 JVM 的垃圾回收持续时间和频率将很值得监控。
相关指标:
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_jvm_gc_collection_seconds_sum | counter | JVM GC垃圾回收时间 |
| 2 | elasticsearch_jvm_gc_collection_seconds_count | counter | JVM GC 垃圾搜集数 |
| 3 | elasticsearch_jvm_memory_committed_bytes | gauge | JVM最大使用内存限制 |
| 4 | elasticsearch_jvm_memory_max_bytes | gauge | 配置的最大jvm值 |
| 5 | elasticsearch_jvm_memory_pool_max_bytes | counter | JVM内存最大池数 |
| 6 | elasticsearch_jvm_memory_pool_peak_max_bytes | counter | 最大的JVM内存峰值 |
| 7 | elasticsearch_jvm_memory_pool_peak_used_bytes | counter | 池使用的JVM内存峰值 |
| 8 | elasticsearch_jvm_memory_pool_used_bytes | gauge | 目前使用的JVM内存池 |
| 9 | elasticsearch_jvm_memory_used_bytes | gauge | JVM内存使用量 |
2.4 主机级别网络系统指标
主机级别资源及网络使用情况也需要关注。
相关指标
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_process_cpu_percent | gauge | CPU使用率 |
| 2 | elasticsearch_filesystem_data_free_bytes | gauge | 磁盘可用空间 |
| 3 | elasticsearch_process_open_files_count | gauge | ES进程打开的文件描述符 |
| 4 | elasticsearch_transport_rx_packets_total | counter | ES节点之间网络入流量 |
| 5 | elasticsearch_transport_tx_packets_total | counter | ES节点之间网络出流量 |
2.5 集群健康和节点可用性指标
ES 是按集群部署的,需要关注集群相关指标。
相关指标
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_cluster_health_status | gauge | 集群状态,green( 所有的主分片和副本分片都正常运行)、yellow(所有的主分片都正常运行,但不是所有的副本分片都正常运行)red(有主分片没能正常运行)值为1的即为对应状态 |
| 2 | elasticsearch_cluster_health_number_of_data_nodes | gauge | node节点的数量 |
| 3 | elasticsearch_cluster_health_number_of_in_flight_fetch | gauge | 正在进行的碎片信息请求的数量 |
| 4 | elasticsearch_cluster_health_number_of_nodes | gauge | 集群内所有的节点 |
| 5 | elasticsearch_cluster_health_number_of_pending_tasks | gauge | 尚未执行的集群级别更改 |
| 6 | elasticsearch_cluster_health_initializing_shards | gauge | 正在初始化的分片数 |
| 7 | elasticsearch_cluster_health_unassigned_shards | gauge | 未分配分片数 |
| 8 | elasticsearch_cluster_health_active_primary_shards | gauge | 活跃的主分片总数 |
| 9 | elasticsearch_cluster_health_active_shards | gauge | 活跃的分片总数(包括复制分片) |
| 10 | elasticsearch_cluster_health_relocating_shards | gauge | 当前节点正在迁移到其他节点的分片数量,通常为0,集群中有节点新加入或者退出时该值会增加 |
| 11 | elasticsearch_breakers_tripped | counter | 熔断发生次数 |
| 12 | elasticsearch_breakers_limit_size_bytes | gauge | 熔断内存限制大小 |
| 13 | elasticsearch_breakers_estimated_size_bytes | gauge | 熔断器内存大小 |
2.6 资源饱和度和错误
ElasticSearch 节点使用线程池来管理线程如何消耗内存和 CPU,所以需要监控线程相关的指标。
相关指标
| 序号 | 指标 | 类型 | 详情 |
|---|---|---|---|
| 1 | elasticsearch_thread_pool_completed_count | gauge | 线程池操作完成线程数 |
| 2 | elasticsearch_thread_pool_active_count | gauge | 线程池活跃线程数 |
| 3 | elasticsearch_thread_pool_largest_count | gauge | 线程池最大线程数 |
| 4 | elasticsearch_thread_pool_queue_count | gauge | 线程池中的排队线程数 |
| 5 | elasticsearch_thread_pool_active_count | gauge | 线程池的被拒绝线程数 |
| 6 | elasticsearch_indices_fielddata_memory_size_bytes | gauge | fielddata缓存的大小(字节) |
| 7 | elasticsearch_indices_fielddata_evictions | gauge | 来自fielddata缓存的驱逐次数 |
3. 监控大盘
Prometheus 监控服务提供了开箱即用的 Grafana 监控大盘,根据预设大盘可以直接监控 ES 集群各类重要指标状态,能够进行问题的快速定位。本文集群大盘使用了腾讯云 ES 作为数据源,腾讯云 Elasticsearch Service(ES)是云端全托管海量数据检索分析服务,拥有高性能自研内核,集成X-Pack。ES 支持通过自治索引、存算分离、集群巡检等特性轻松管理集群,也支持免运维、自动弹性、按需使用的 Serverless 模式。使用 ES 您可以高效构建信息检索、日志分析、运维监控等服务,它独特的向量检索还可助您构建基于语义、图像的AI深度应用。
3.1 集群大盘
集群大盘提供了集群相关的监控信息,包括了集群节点、分片、资源利用率、熔断、线程池等监控信息。
集群概要

该监控提供集群概览信息,可大致概览集群状况,可以看出集群健康状况、节点数、数据节点、熔断器熔断次数、利用率、集群 pending 任务数、ES 进程打开的文件描述符等信息。集群健康监控 red 为1,green 时为5,yellow 为23。
分片监控(Shards)

分片监控提供集群中的主节点数、副本节点数,同时提供正在初始化的、正在迁移的、延迟分配的、未分配的分片信息。
熔断监控(Breakers)

该监控提供各类熔断器熔断的次数,以及熔断内存使用量。可以通过该监控去排查熔断发生的熔断器类别、熔断限制、熔断发生时的内存使用量以及是哪个节点发生的熔断。
- Tripped for breakers:分析各类型的熔断器熔断的次数;
- Estimated size in bytes of breaker:分析给类型熔断器熔断内存使用量。
节点监控

- Load average:分析各节点的短期平均负载;
- CPU usage:分析 CPU 使用率;
- GC count:分析 JVM GC 运行次数;
- GC time:分析 JVM GC 运行时间。
节点监控提供了各节点的短期平均负载、CPU 使用情况、JVM GC 运行相关数据、数据存储使用情况、网络使用情况等。可以通过该监控发现并快速定位节点资源问题。

- JVM memory usage:分析 JVM 内存使用量、内存最大限制以及池内存使用峰值;
- JVM memory committed:分析各区域提交内存使用量;
- Disk usage:分析数据存储使用情况;
- Network usage:分析网络使用情况,包括发送和接收。
线程池监控(Thread Pool)
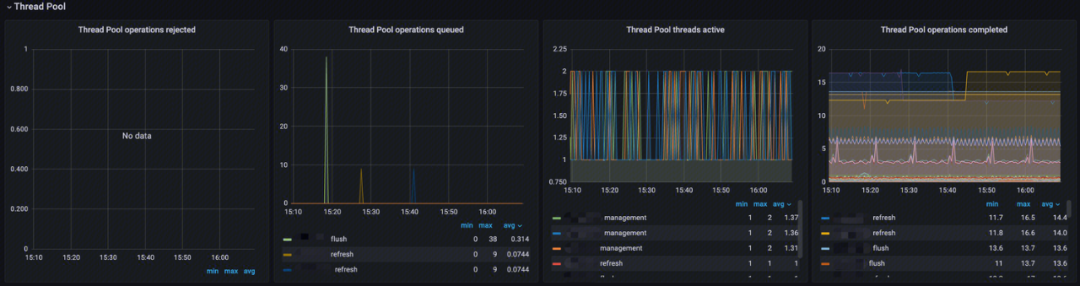
- Thread Pool operations rejected:分析线程池中各类型操作拒绝率;
- Thread Pool operations queued:分析线程池中各类型线程排队数;
- Thread Pool threads active:分析线程池中各类型活跃线程数;
- Thread Pool operations completed:分析线程池中各类型线程完成数。
3.2 索引大盘
Translog

该监控提供 Translog 相关指标
- Total Translog Operations:分析 Translog 操作总数;
- Total Translog size in bytes:查看 Translog 内存使用趋势,分析性能是否影响写入性能。
文档(Documents)
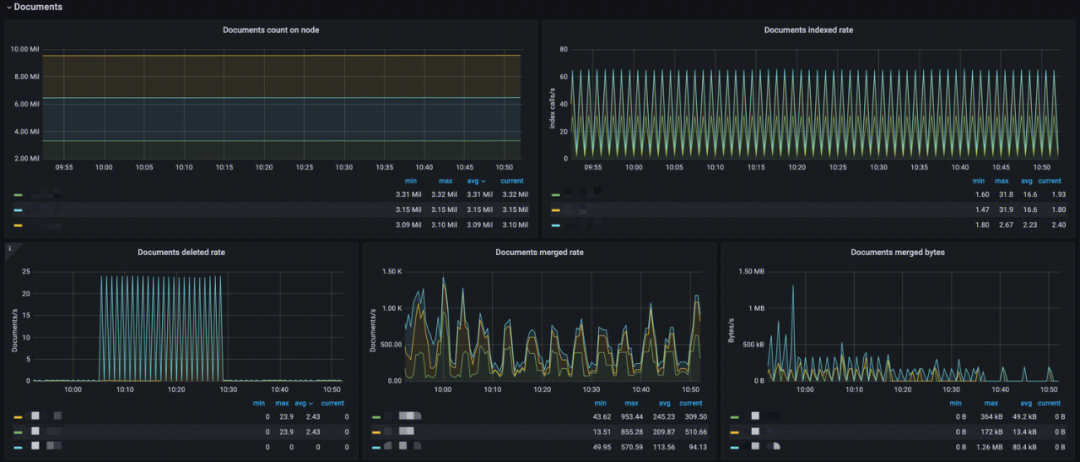
- Documents count on node:分析节点 Index 文档数,看索引是否过大;
- Documents indexed rate:分析 Index 索引速率;
- Documents deleted rate:分析 Index 文档删除速率;
- Documents merged rate:分析索引文档 merge 速率;
- Documents merged bytes:分析 Index merge 内存大小。
延时
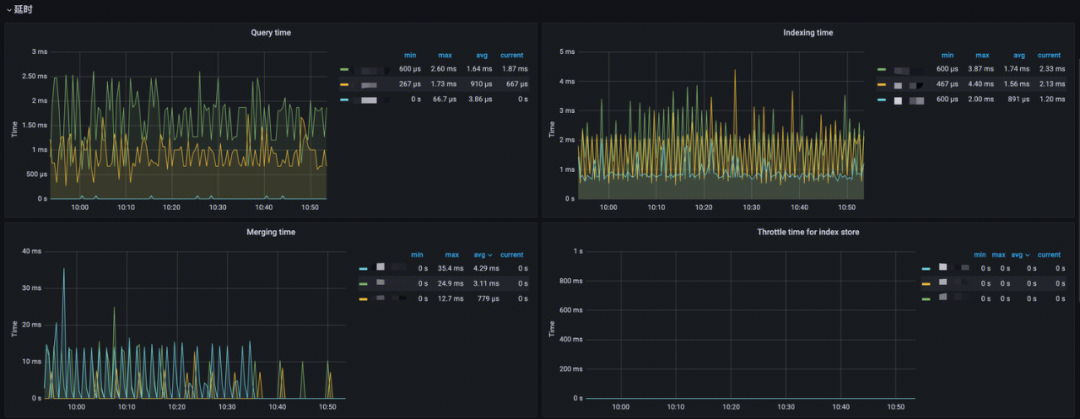
- Query time:分析 Index 查询耗时;
- Indexing time:分析索引文档耗时;
- Merging time:分析索引 merge 操作耗时;
- Throttle time for index store:Index 写入限制时间,分析 merge 与写入的合理性。
索引操作次数及耗时(Total Operation stats)
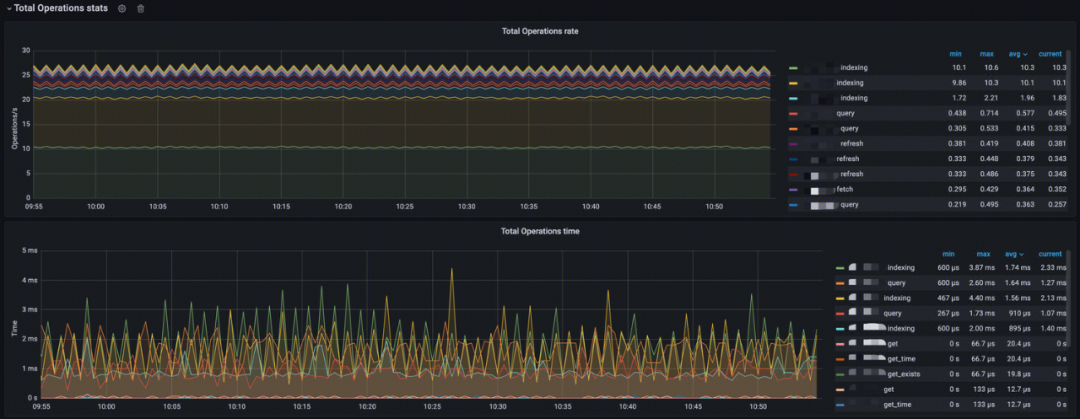
- Total Operations rate:分析 Index 索引操作速率、查询速率、查询 fetch 速率,merge 速率、refresh 速率、flush 速率、GET 存在的速率、GET 不存在的速率、GET操作速率、Index 删除速率;
- Total Operations time:分析 Index 索引操作耗时、查询耗时、查询 fetch 耗时,merge 耗时、refresh 耗时、flush 耗时、GET 存在的耗时、GET 不存在的耗时、GET操作耗时、Index 删除耗时。
线程池(Thread Pool)
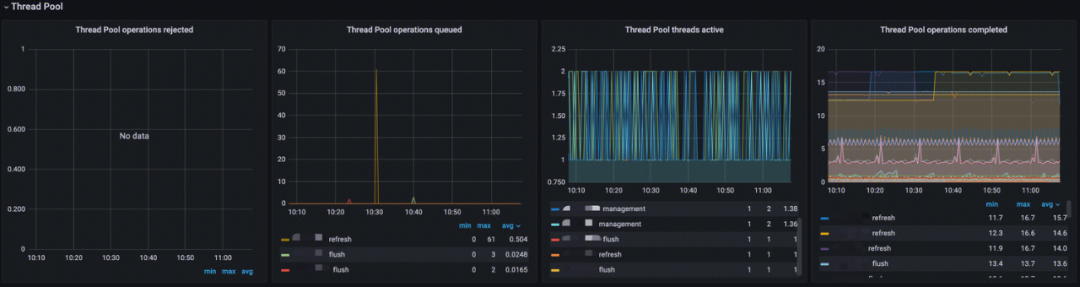
- Thread Pool operations rejected:分析线程池中各类型操作拒绝率;
- Thread Pool operations queued:分析线程池中各类型线程排队数;
- Thread Pool threads active:分析线程池中各类型活跃线程数;
- Thread Pool operations completed:分析线程池中各类型线程完成数。
缓存(Caches)

- Field data memory size:分析 Fielddata 缓存大小;
- Field data evictions:分析 Fielddata 缓存达到驱逐限制后驱逐的数据的速率;
- Query cache size:分析查询缓存大小;
- Query cache evictions:分析 Query 缓存达到驱逐限制后驱逐的数据的速率;
- Evictions from filter cache:分析过滤查询达到驱逐限制后驱逐的数据的速率。
段(Segments)
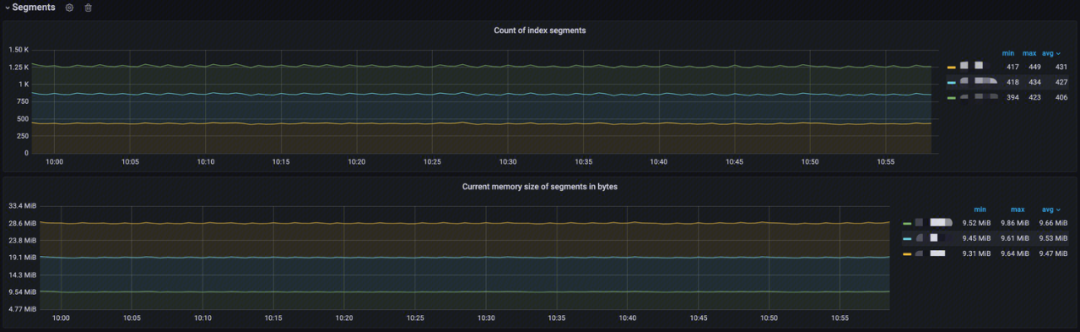
- Documents count on node:分析节点上的索引 Segment 计数;
- Current memory size of Segments in bytes:分析当前索引 Segment 内存大小。
4. 典型问题场景
4.1 ElasticSearch 查询性能差
ElasticSearch 查询性能变差的原因有很多,需要通过监控指标判断具体症状,然后根据症状进行相应处理。
非活动状态下资源利用率也很高
每个分片都消耗资源(CPU/内存)。即使没有索引/搜索请求,分片的存在也会产生集群开销。
- 原因:集群中分片太多,以至于任何查询的执行速度看起来都很慢;
- 排查方法:检查集群大盘中的分片监控,查看分片是否过多
- 解决方案:减少分片计数,实施冻结索引和/或添加附加节点来实现负载平衡。考虑结合使用 ElasticSearch 中的热/温架构(非常适合基于时间的索引)以及滚动/收缩功能,以高效管理分片计数。要想顺利完成部署,最好先执行适当的容量计划,以帮助确定适合每个搜索用例的最佳分片数。
线程池存在大量的“rejected”
线程池中存在大量拒绝,从而导致查询不能被正常执行。
- 原因:查询面向的分片太多,超过了集群中的核心数。这会在搜索线程池中造成排队任务,从而导致搜索拒绝。另一个常见原因是磁盘 I/O 速度慢,导致搜索排队或在某些情况下 CPU 完全饱和;
- 排查方法:查看集群大盘线程池监控中的拒绝率监控,判断是否有大量拒绝;
- 解决方案:创建索引时采用1个主分片:1个副本分片 (1P:1R) 模型。使用索引模板是一个在创建索引时部署此设置的好方法。(ElasticSearch 7.0 或更高版本将默认 1P:1R)。ElasticSearch 5.1 或更高版本支持搜索任务取消,这对于取消任务管理 API 中出现的慢查询任务非常有用。
高 CPU 使用率和索引延迟
指标相关性表明,当集群不堪重负时,CPU 使用率和索引延迟都会很高。
- 原因:集群索引量大会影响搜索性能。
- 排查方法:查看索引大盘节点监控中的 CPU 使用率、JVM CPU 使用率监控查看 CPU 利用率,然后通过延时告警中的索引耗时面板查看索引延迟状况;
- 解决方案:提高 refresh 间隔 index.refresh_ interval 至30s,通常有助于提高索引性能。这可以确保分片不必因为每1秒默认创建一个新分段而造成工作负载增大。
副本分片增加后延迟增大
在副本分片计数增加(例如,从1增加到2)后,可以观察到查询延迟。如果存在较多的数据,那么缓存的数据将很快被逐出,从而导致操作系统页面错误增加。
- 原因:文件系统缓存没有足够的内存来缓存索引中经常查询的部分。ElasticSearch 的查询缓存实现了 LRU 逐出策略:当缓存变满时,将逐出最近使用最少的数据,以便为新数据让路。
- 排查方法:在分片有增加时,查看索引大盘延时中的查询耗时监控,观察查询延迟是否增大,若有增大,查看索引大盘缓存面板中的查询缓存及查询缓存驱逐监控,缓存变高,驱逐量增大,就是该问题;
- 解决方案:为文件系统缓存留出至少50%的物理 RAM。内存越多,缓存的空间就越大,尤其是当集群遇到 I/O 问题时。假设堆大小已正确配置,任何剩余的可用于文件系统缓存的物理 RAM 都会大大提高搜索性能。除了文件系统缓存,ElasticSearch 还使用查询缓存和请求缓存来提高搜索速度。所有这些缓存都可以使用搜索请求首选项进行优化,以便每次都将某些搜索请求路由到同一组分片,而不是在不同的可用副本之间进行交替。这将更好地利用请求缓存、节点查询缓存和文件系统缓存。
共享资源时利用率高
操作系统显示出持续的高 CPU/磁盘 I/O 利用率。停止第三方应用程序后,可以看到性能会提高。
- 原因:其他进程(例如 Logstash)和 ElasticSearch 本身之间存在资源(CPU 和/或磁盘 I/O)争用。
- 排查方法:查看集群大盘节点监控面板中的 CPU、磁盘、网络等利用率监控,发现持续居高,此时停止第三方应用,就会发现 CPU、磁盘、网络等利用率下降,同时性能提高;
- 解决方案:避免在共享硬件上与其他资源密集型应用程序一起运行 ElasticSearch。
4.2 ElasticSearch索引性能差
ElasticSearch 索引性能变差的原因同样有很多,具体情况具体分析。
硬件资源不足
硬件资源是一切的基础,其性能决定着运行在其上的集群的性能上限。
- 原因:硬盘速度慢、CPU 负载高、内存不足等会导致写入性能下降;
- 排查方法:查看集群大盘节点监控面板中的 CPU、磁盘、网络等利用率监控,各指标持续居高;
- 解决方案:升级硬件、增加节点或者使用更快的存储设备。
索引设置不当
索引的分片、副本数及刷新时间间隔等均会影响索引性能。
- 原因:不合理的索引设置,如过多的分片数、不合理的副本数、不适当的刷新间隔等会影响写入性能。分片越多会导致写入变慢,多副本会极大的影响写入吞吐,刷新操作属于代价很高的操作,过于频繁的刷新操作会影响集群整体性能;
- 排查方法:查看集群大盘中的分片大盘,查看分片数、副本数是否过多,判断其合理性;
- 解决方案:优化索引设置,调整分片和副本数量,增大刷新间隔等。
索引压力过大
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
引性能。
- 原因:不合理的索引设置,如过多的分片数、不合理的副本数、不适当的刷新间隔等会影响写入性能。分片越多会导致写入变慢,多副本会极大的影响写入吞吐,刷新操作属于代价很高的操作,过于频繁的刷新操作会影响集群整体性能;
- 排查方法:查看集群大盘中的分片大盘,查看分片数、副本数是否过多,判断其合理性;
- 解决方案:优化索引设置,调整分片和副本数量,增大刷新间隔等。
索引压力过大
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-gCqjaNA1-1713191855710)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









