







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
高性能其实我们就可以理解为高并发,而高并发问题可以简单分为:高并发读、高并发写、读写同时高并发3类。
1、侧重于高并发读的场景,比如搜索引擎;电商商品搜索;电商系统的商品详情展示等。
2、侧重于高并发写的场景,比如广告扣费系统:用户的每次浏览或点击都需要对余额做扣减。
3、读写高并发的场景,比如电商库存系统和秒杀系统;支付系统和微信红包;微博朋友群。
应对高并发读和高并发写的策略有所不同,下面通过一些案例分析在不用场景可采取的策略。
一、高并发读
**策略一:**缓存银弹
如果高并发读流量扛不住了,相信很多人首先想到的是加缓存,它的本质就是空间换时间,下面列举几个典型的案例。
案例1:本地缓存(包括Nginx缓存和应用缓存) + Memached/Redis的集中缓存。
缓存的使用需要保障缓存的命中率,所以需要考虑好缓存的刷新策略和回收算法,以尽可能提高缓存的命中率。
缓存刷新策略:1、主动更新,当数据库中数据发生变更时,主动删除或者更新缓存中的数据;2、被动更新,当用户的查询请求到来时,如果缓存过期,再更新缓存。
缓存命中率:回收策略:基于空间;基于时间;基于对象应用(堆内缓存)。回收算法:FIFO(先进先出);LRU(最近最少使用);LFU(最不长使用)。
案例2: Mysql的Master/Slave
缓存策略很容易用来缓存各种结构相对简单的数据,但对于有的场景,需要用到多张表关联查询,比如后端Admin系统要操作复杂的业务数据,如果直接查业务系统的数据库,会影响C端用户的高并发访问。对于这种查询,可以为Mysql加一个或者多个Slave,来分担主库的读压力。当然也可以把多张表的关联结果放到缓存,但这会存在一个问题:在多张表中的任何一张表数据发生变化,缓存都得刷新。
案例3:CDN静态文件加速(动静分离)
在网站页面展示的内容中,分为静态内容和动态内容两部分。静态内容,比如图片,HTML,JS,CSS等文件。动态内容:需要根据用户信息或其他信息(比如当前时间)实时生成并返回给用户的信息。对于静态内容,常用的策略就是CDN。一个静态文件缓存到了全网的各个节点,当第一个用户访问的时候,离用户最近的节点没有缓存数据,CDN就会去源系统抓取文件缓存到该节点,后续用户访问就可直接从这个节点获取静态内容。
**策略二:**并发读
无论是读还是写,串行改并行都是一个常用的策略。
案例1:异步RPC
如果多个RPC调用之间没有耦合关系,可以通过采用并行调用的方式来减少查询处理耗时。
案例2: 冗余请求
客户端首先向一台服务器发送请求,在一定时间内没有收到服务端的响应,则立马给另外一台(或者多台)发送同样的请求,客户端等待一个响应到达之后,终止其他请求的处理。上面“一定时间”定义为:95%请求的响应时间。对于这种方式,Google公司的测试数据表示:采用这种方法,可以仅用2%的额外请求将系统99.9%的请求响应时间从1800ms降到了74ms.
策略三: 重读轻写
案例1: 微博或朋友圈Feeds流
微博首页或者微信朋友圈都有类似的查询场景:用户关注了n个人(或者有n个好友),每个人都在不断地发微博或朋友圈,系统需要把这n个人发布的内容按时间排序成一个列表,这就是微博Feeds流。Feeds流是一个持续更新并展示给用户的信息流。它将用户主动订阅的若干消息源组合在一起形成内容聚合器,帮助用户持续地获取最新的订阅源内容。
在这种场景下,如果单纯只靠一个用户关系表和内容发布表,这种数据模型无法满足高并发查询请求的。我们可以采取重写轻读的方法做数据扩散。假设某个用户有1000个粉丝,发布一条微博之后,只要写入自己的收件箱就返回成功,然后异步把这条微博推送给1000个粉丝的收件箱,也就是写扩散,这样每个用户读Feeds流时就不用做实时聚合了,只需要查自己的收件箱就可以。
案例2: 多表关联查询:宽表与搜索引擎
在策略一中提到一种场景:后端需要对业务数据做多表关联查询时,通过Slave解决,这种方法适合没有分库的情况。
如果数据库已经分库,那么需要从多个库查询数据聚合,这就无法使用数据库的排序和分页功能,此时也只能采用重读轻写的思路,把关联数据提前计算好,存在一个地方,读的时候直接查询聚合好的数据。也可以用ES类的搜索引擎来实现,把多表关联的结果做成一个个文档,放在搜索引擎里面,也可以做到灵活排序和分页查询。
我们也可以称这种方式为“数据异构”。分库分表中有一个最为常见的场景,为了提升数据库的查询能力,我们都会对数据库做分库分表操作。比如订单库,开始的时候我们是按照订单ID维度去分库分表,那么后来的业务需求想按照商家维度去查询,此时查询某一个商家下的所有订单就非常麻烦,这个时候我们通过数据异构把存储一张商家维度的订单表就可解决这一问题。
总结:读写分离
不论时加缓存、动静分离,还是重读轻写(数据异构),其本质都是读写分离,也就是微服务架构经常提到的CQRS(Comman Query Responsibitlity Separation)
下图总结了读写分离架构的典型模型,该模型有几个典型特征:
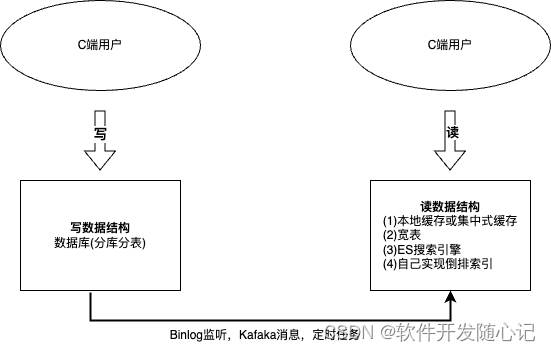
(1)分别为读写设计不同的数据结构。把系统分为读和写两个不同的视角来设计,各自设计高并发读和高并发写的数据结构或数据模型。可以看到,缓存其实是读写分离的一个简化,或者说是一个特例,左边写(DB)和右边读(缓存)其实用的基本一样的数据结构。
(2)写的这一端,通常也是在线业务DB,通过分库分表抵抗压力。读的这一端,为了扛住高并发压力,针对不通的业务场景,可能是缓存,也可能是提前join好的宽表,或者是ES搜索引擎,如果ES的性能不足,则可以自己建立倒排索引和搜索引擎。
(3)读和写的串联。定时任务把业务数据库中的数据转换为适合高并发读的数据结构,或者是写的一端把数据变更完成后发送消息给读的一端消费消息,或者读的一端直接监听数据库中的binlog,监听数据变化来更新读的一端的数据。
(4)读比写有延迟。因为左边写的数据是实时变化的,然后读的一端消费消息,读取端肯定会有所延迟,但和写之间是最终一致性,而不是强一致性,在绝大部分场景下应该是不影响业务的。
二、高并发写
**策略一:**数据分片
数据分片就是对要处理的数据或请求分成多份并行处理。
案例1: 数据库的分库分表。
分表后,虽然数据请求还是在一台机器上,但是可以更加充分利用机器的CPU,内存等资源。分库后,可以利用多台机器的资源。
案例2: JDK ConcurrentHashMap的实现
ConcurrentHashMap在内部分成了若干了槽,也就是若干个HashMap,这些槽可以并发的读写,槽与槽之间是独立的,不会发生数据互斥。
案例3: Kafka的partition
在Kafaka中,一个topic表示一个逻辑上的消息队列,但物理上会分散到多个partition上存储,partition之间也是相互独立的,也就提高了topic的并发量。
案例4: ES的分布式索引
在搜索引擎里有一个基本的策略就是分布式索引。当为一个比较的数据集建立索引时,索引本身也会很大,无法并发查询,可以把数据集分成n份,建成n个小索引,一个请求过来之后,可以并行的在n个索引上查询,再把结果集进行合并。
**策略二:**任务分片
数据分片是对要处理的数据或者请求进行分片,而任务分片是对处理程序本身进行分片。现实生活中工厂的流水线作业就是任务分片的例子。
案例1:CPU指令流水线
一致CPU指令可以拆成“取指”,“译码”,“执行”,“回写”四个阶段,四个阶段可以并行执行。
案例2: Map/Reduce
把任务拆解同时运行,归并排序算法也是这种思想,在时间复杂度上明显降低。
案例3: 1+N+M的网络模型

在服务端的网络编程中,不论时Tomcat,Netty, 还是Linux的epoll,都是基于这个1+N+M的网络模型。把一个请求的处理分成了三个工序:监听、I/O,业务逻辑处理。1个监听线程负责监听客户端socket请求;N个I/O线程负责对Socket进行读写,N约等于CPU的核数,M个线程负责对请求进行逻辑处理。进一步讲,Work线程还可以拆分成解码,业务逻辑处理,编码等环节。进一步提升并发度。
**策略三:**异步化
异步化常用接口表和队列术两种方式,接口表就是服务端收到请求后,把请求体写到接口表中,通过定时任务异步处理接口表中的请求数据。队列术就是把请求放到消息队列中,通过异步消息消费任务异步处理。此外,消息队列在系统解耦,数据同步,流量削峰等场景中也有广泛的使用。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-3RK12GQ3-1713192045134)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









