







 本文介绍了聚类分析的基本概念,重点讨论了如何衡量两笔数据的相似性,包括二元变量、混合类别型和数值型变量的相似性衡量方法,以及曼哈顿距离和欧式距离的计算。通过对距离矩阵的理解,为后续的聚类算法选择和群组特征描述奠定了基础。
本文介绍了聚类分析的基本概念,重点讨论了如何衡量两笔数据的相似性,包括二元变量、混合类别型和数值型变量的相似性衡量方法,以及曼哈顿距离和欧式距离的计算。通过对距离矩阵的理解,为后续的聚类算法选择和群组特征描述奠定了基础。
因为我们需要将他们根据这个特点来进行聚类
2.如何根据相似性将类似的成员分在同一群(算法的选择)
3.怎么去描述各群的特征。
实现我们解决第一个问题
如何衡量两笔数据的相似性
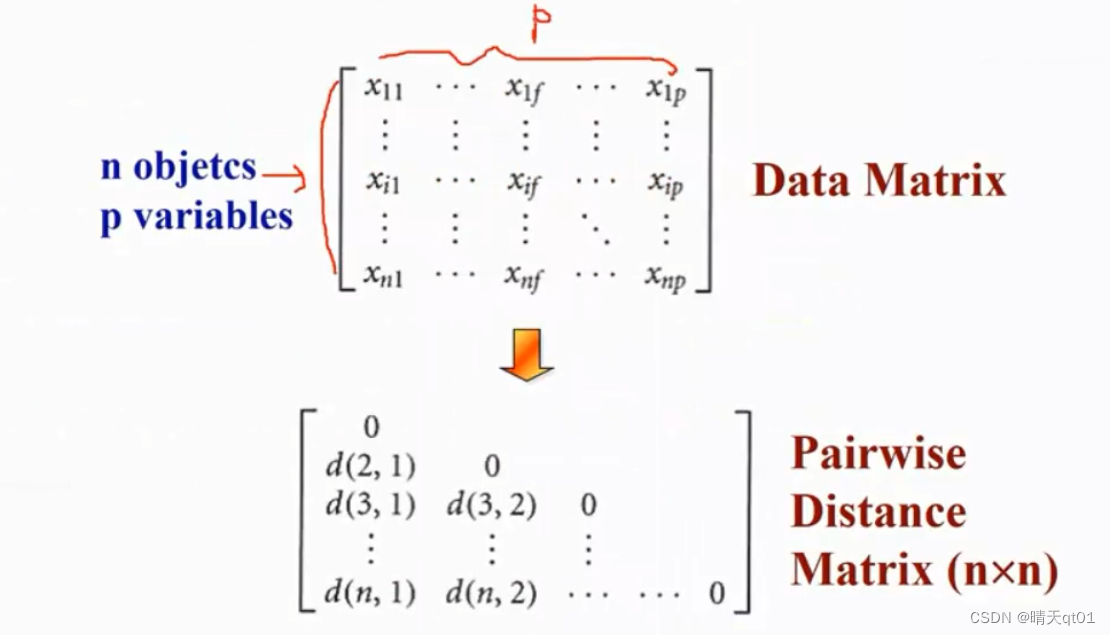
这里有n笔记录,p个字段。这个一般就是我们的数据。接下来我们需要计算它们之间彼此的距离,这里使用的是pairwise的距离,下表是两两一对的距离矩阵。
自己和自己的距离一定是0,说明相似性为百分百,距离越小,相似性越大。所以我们只需要看上三角或者下三角就可以。
距离矩阵的每个距离我们要如何计算?X下面用3种方式进行说明。
二元变量的相似性的衡量方法

这里用的是二变量的两个比较常用的公式,这种二元变量通常使用在推荐系统,有还是没有,有代表顾客对这个商品感兴趣,没有代表顾客对这个商品不感兴趣。这些都是属于二元变量。
在顾客中推荐购买这两种商品的相似度的时候经常用这两个公式。
它们是如何去计算的呢,首先它们需要产生上面的交叉表。Contingency table。需要两个对象i和j我们要看i和j的相似度。
q是代表两个字段都是1的个数,r+s代表一个是1,一个是0的个数(就是二者不相同的个数),tdaib都是0的个数
总共有几笔记录数就是q+r+s+t
我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2964
2964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









