









网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
目录~python
个人昵称:lxw-pro
个人主页:欢迎关注 我的主页
个人感悟: “失败乃成功之母”,这是不变的道理,在失败中总结,在失败中成长,才能成为IT界的一代宗师。
分析班级BMI指数
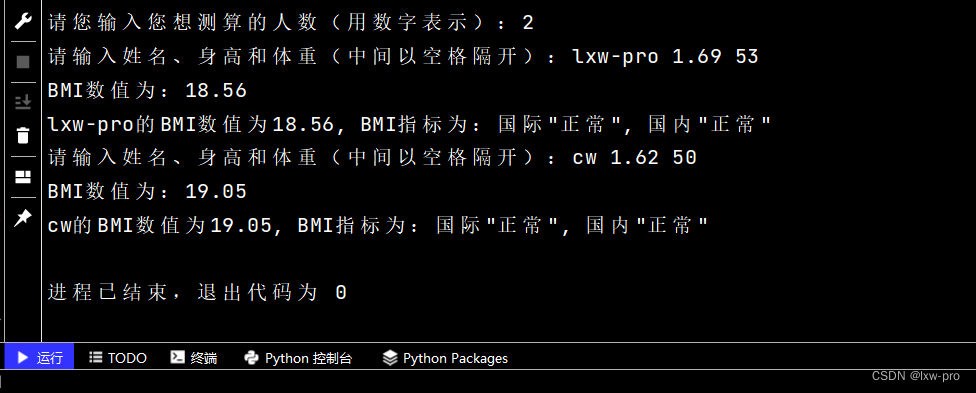
n = int(input("请您输入您想测算的人数(用数字表示):"))
for i in range(n):
classBmi = input("请输入姓名、身高和体重(中间以空格隔开):").split(' ')
name = classBmi[0]
height = eval(classBmi[1])
weight = eval(classBmi[2])
bmi = weight / pow(height, 2)
print("BMI数值为:{:.2f}".format(bmi))
who, nat = "", ""
if bmi < 18.5:
who, nat = "偏瘦", "偏瘦"
elif 18.5 <= bmi < 24:
who, nat = "正常", "正常"
elif 24 <= bmi < 25:
who, nat = "正常", "偏胖"
elif 25 <= bmi < 28:
who, nat = "偏胖", "偏胖"
elif 28 <= bmi < 30:
who, nat = "偏胖", "偏胖"
else:
who, nat = "肥胖", "肥胖"
print('{0}的BMI数值为{1}, BMI指标为:国际"{2}", 国内"{3}"'.format(name, format(bmi, '.2f'), who, nat))
运行效果如下:
分析年级BMI指数
gradeBmis = [[('20级大数据一班', "王平", 1.66, 55), ('20级大数据一班', '王恰', 1.65, 52), ('20级大数据一班', '周馓', 1.75, 66)],
[('20级大数据二班', "仁济", 1.66, 64), ('20级大数据二班', '范德萨', 1.72, 66), ('20级大数据二班', '陈琳', 1.76, 56)]]
for classes in gradeBmis:
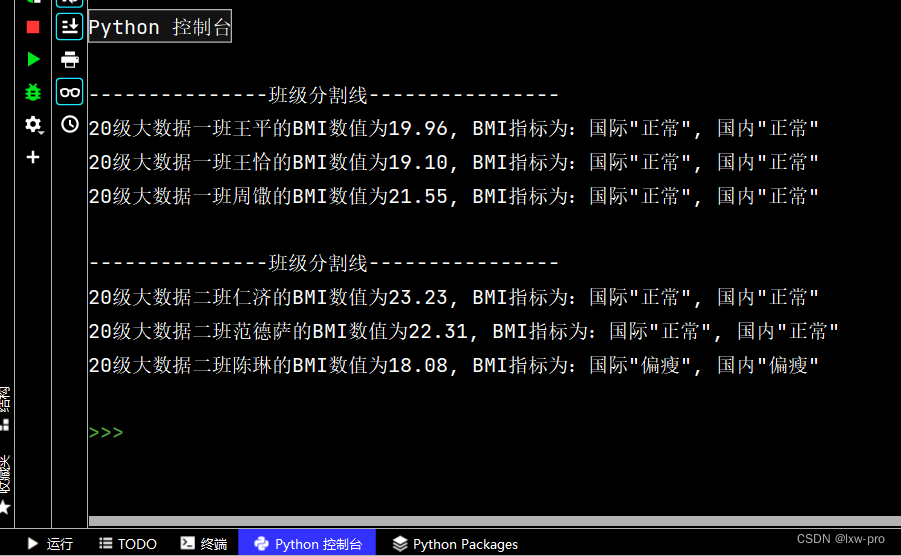
print("\n---------------班级分割线----------------")
for person in classes:
className, name, height, weight = person[0], person[1], person[2], person[3]
who, nat = "", ""
bmi = weight / pow(height, 2)
if bmi < 18.5:
who, nat = "偏瘦", "偏瘦"
elif 18.5 <= bmi < 24:
who, nat = "正常", "正常"
elif 24 <= bmi < 25:
who, nat = "正常", "偏胖"
elif 25 <= bmi < 28:
who, nat = "偏胖", "偏胖"
elif 28 <= bmi < 30:
who, nat = "偏胖", "偏胖"
else:
who, nat = "肥胖", "肥胖"
print('{0}{1}的BMI数值为{2}, BMI指标为:国际"{3}", 国内"{4}"'.format(className, name, format(bmi, '.2f'), who, nat))
运行效果如下:
————————————————————————————————————————————
Pandas 每日一练:
# -\*- coding = utf-8 -\*-
# @Time : 2022/7/28 20:34
# @Author : lxw\_pro
# @File : pandas-10 练习.py
# @Software : PyCharm
import pandas as pd
lxw = pd.read_excel("site.xlsx")
print(lxw)
运行结果为:
Unnamed: 0 Unnamed: 0.1 create_dt ... yye sku_cost_prc lrl
0 0 1 2016-11-30 ... 8.8 6.77 30.00%
1 1 2 2016-11-30 ... 7.5 5.77 30.00%
2 2 3 2016-11-30 ... 5.0 3.85 30.00%
3 3 4 2016-11-30 ... 19.6 7.54 30.00%
4 4 5 2016-12-02 ... 13.5 10.38 30.00%
.. ... ... ... ... ... ... ...
751 751 752 2016-12-31 ... 1.0 0.77 30.00%
752 752 753 2016-12-31 ... 2.0 1.54 30.00%
753 753 754 2016-12-31 ... 1.0 0.77 30.00%
754 754 755 2016-12-31 ... 7.6 2.92 30.00%
755 755 756 2016-12-31 ... 3.3 2.54 30.00%
[756 rows x 8 columns]
61、以lxw的列名创建一个dataframe
lm = pd.DataFrame(columns=lxw.columns.to_list())
print(lm)
运行结果为:
Empty DataFrame
Columns: [Unnamed: 0, Unnamed: 0.1, create_dt, sku_cnt, sku_sale_prc, yye, sku_cost_prc, lrl]
Index: []
62、打印所有利润率不是数字的行
for i in range(len(lxw)):
if type(lxw.iloc[i, 6]) != float:
lm = lm.append(lxw.loc[i])
print(lm)
运行结果为:
Unnamed: 0 Unnamed: 0.1 create_dt ... yye sku_cost_prc lrl
0 0 1 2016-11-30 ... 8.8 6.77 30.00%
1 1 2 2016-11-30 ... 7.5 5.77 30.00%
2 2 3 2016-11-30 ... 5.0 3.85 30.00%
3 3 4 2016-11-30 ... 19.6 7.54 30.00%
4 4 5 2016-12-02 ... 13.5 10.38 30.00%
.. ... ... ... ... ... ... ...
751 751 752 2016-12-31 ... 1.0 0.77 30.00%
752 752 753 2016-12-31 ... 2.0 1.54 30.00%


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









