







 本文介绍了Hive在大数据生态中的角色,详细讲解了Hive的系统架构,包括用户接口、驱动模块和元数据存储。探讨了HQL如何转化为MapReduce作业,特别讨论了join和group by的实现原理。此外,提供了详尽的Hive环境配置教程,涉及Hive、MySQL的安装与配置,并将MySQL设为Hive的元数据存储数据库。最后,通过一系列实验练习,展示了Hive的基本操作,如新建数据库、表、分区,数据导入、查询与统计分析。
本文介绍了Hive在大数据生态中的角色,详细讲解了Hive的系统架构,包括用户接口、驱动模块和元数据存储。探讨了HQL如何转化为MapReduce作业,特别讨论了join和group by的实现原理。此外,提供了详尽的Hive环境配置教程,涉及Hive、MySQL的安装与配置,并将MySQL设为Hive的元数据存储数据库。最后,通过一系列实验练习,展示了Hive的基本操作,如新建数据库、表、分区,数据导入、查询与统计分析。
2.3 生态系统
- Hive依赖于HDFS 存储数据、
- Hive依赖于MapReduce 处理数据
- 在某些场景下Pig可以作为Hive的替代工具
- HBase 提供数据的实时访问
- Pig主要用于数据仓库的ETL环节
- Hive主要用于数据仓库海量数据的批处理分析

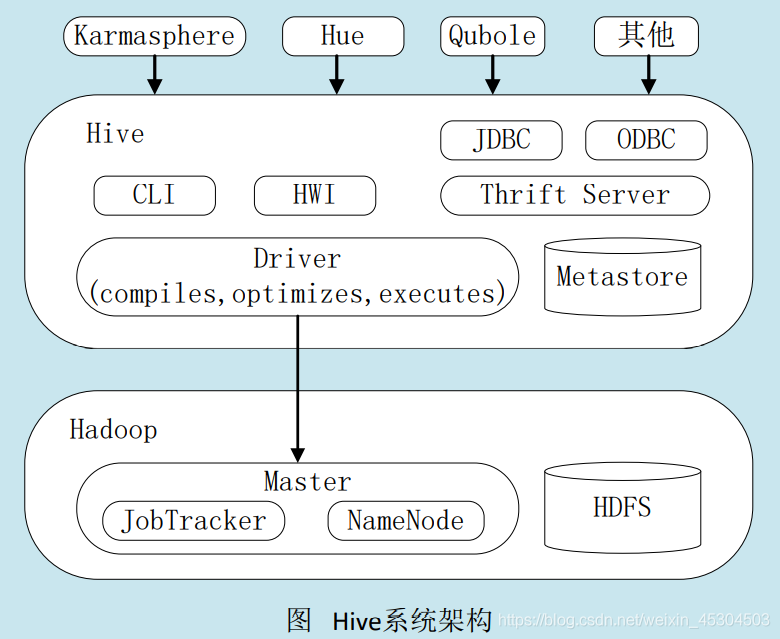
3. Hive系统架构
- 用户接口模块。包括CLI、HWI、JDBC、ODBC、Thrift Server
- 驱动模块(Driver)。包括编译器、优化器、执行器等,负责把HiveQL语句转换成一系列MapReduce作业
- 元数据存储模块(Metastore)。是一个独立的关系型数据库(自带derby数据库,或MySQL数据库)
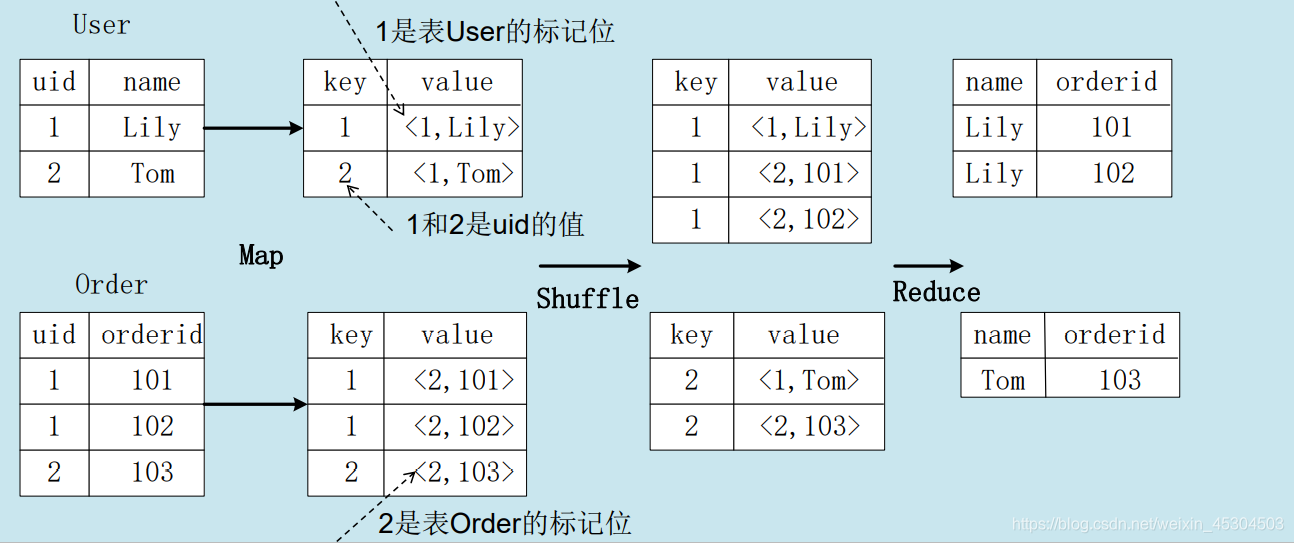
4. HQL转成MapReduce作业的原理
4.1 join的实现原理
select name, orderid from user join order on user.uid=order.uid;
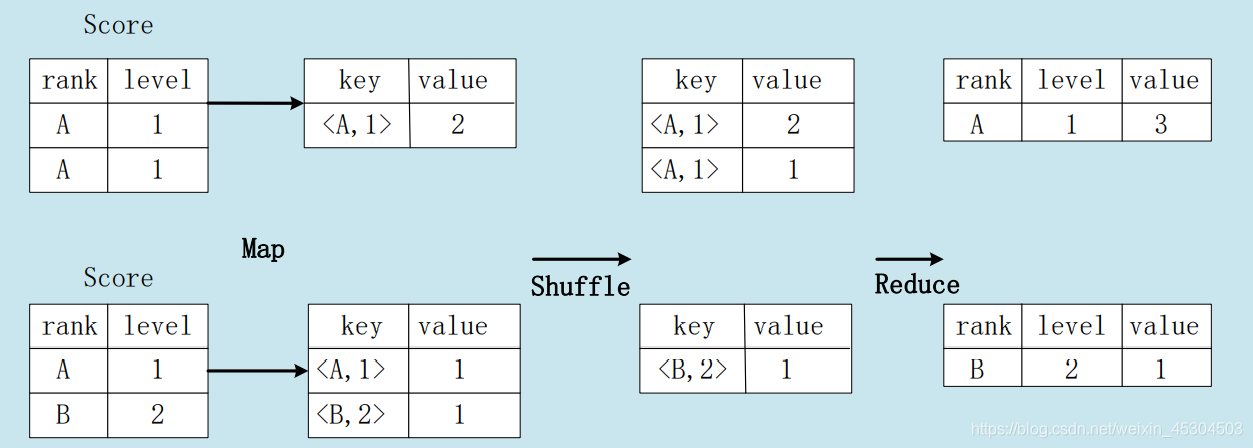
4.2 group by的实现原理
存在一个分组(Group By)操作,其功能是把表Score的不同片段按照rank和level的组合值进行合并,计算不同rank和level的组合值分别有几条记录:
select rank, level ,count(\*) as value from score group by rank, level
5. 实验练习
5.1 环境配置
5.1.1 HIVE
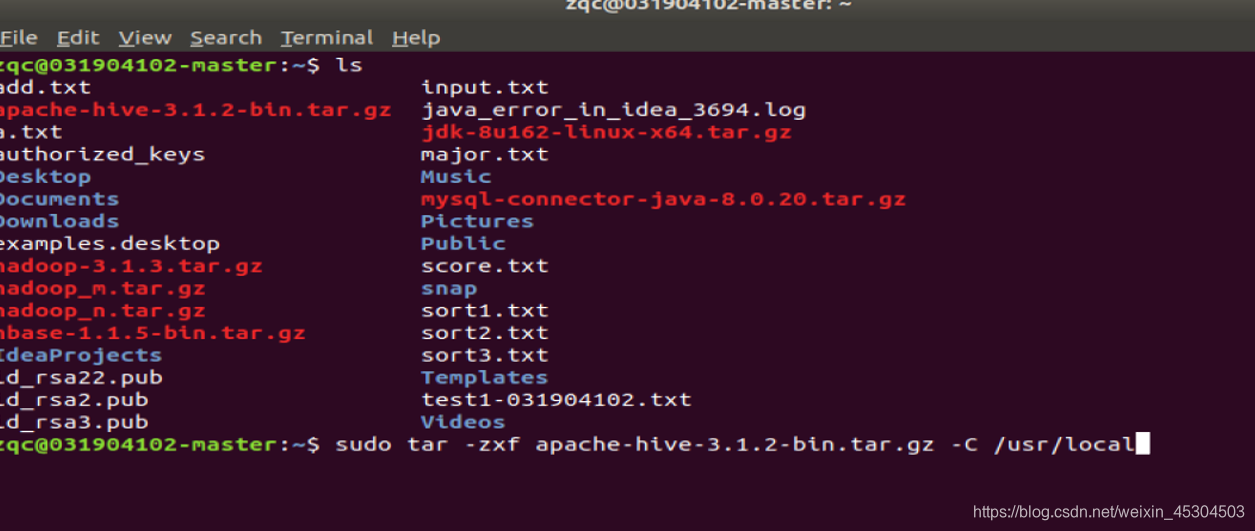
将Hive解压到/usr/local中

更改名字

更改hive目录所有者和所在用户组

环境配置

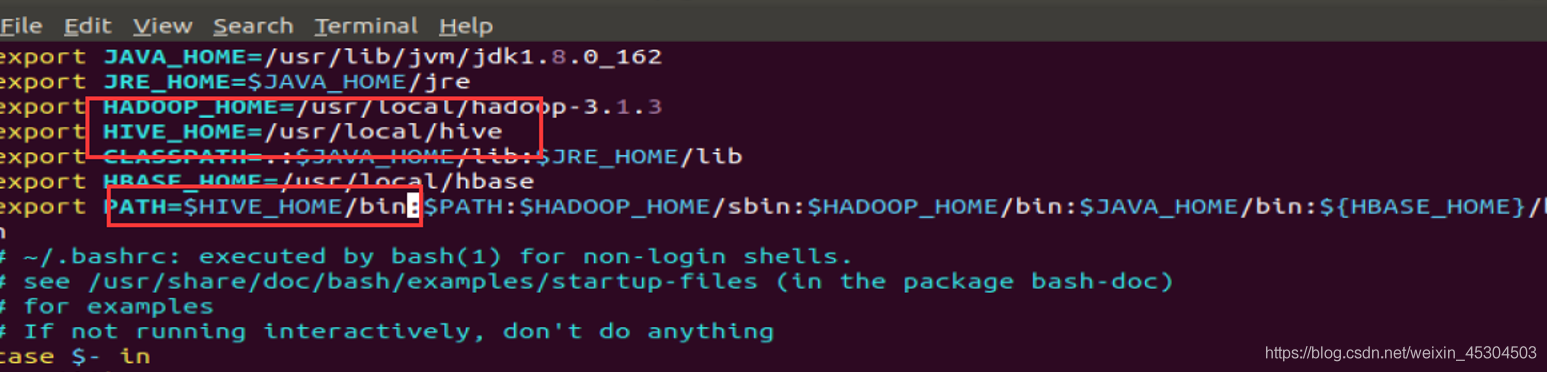
使环境生效

5.1.2 MYSQL
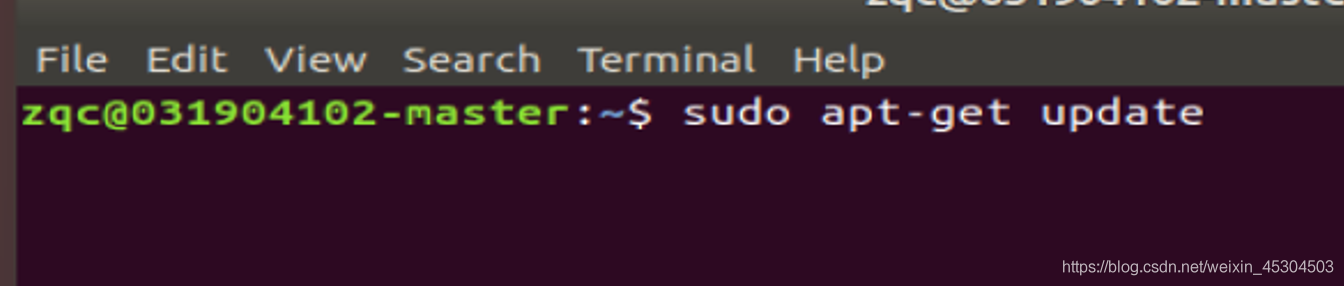
更新软件源
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









