








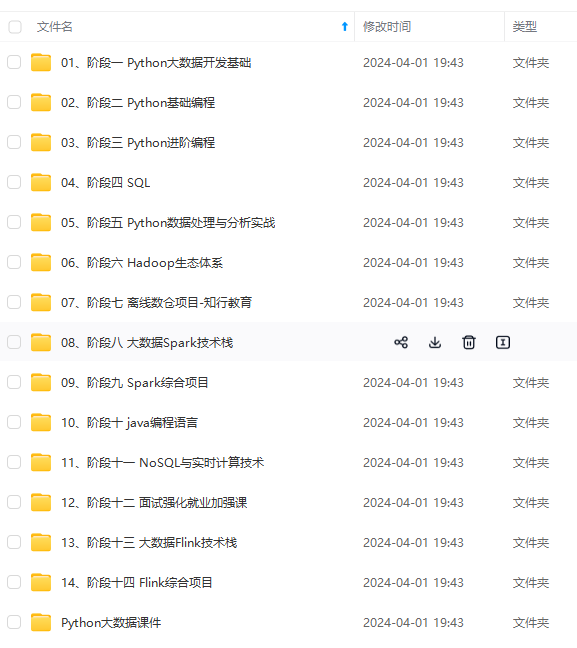
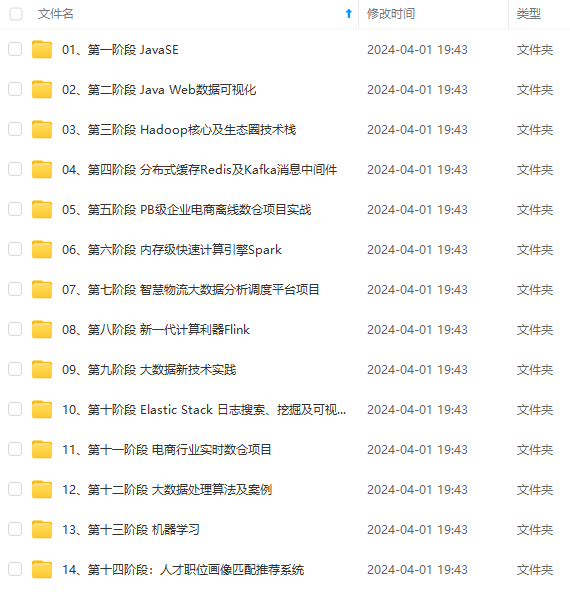
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
y_predict = DT.predict(test_x)
print(accuracy_score(y_predict, test_y))
if name == “main”:
train_and_evaluate()
#### 信息熵的计算
原题:[决策树的生成与训练-信息熵的计算\_牛客题霸\_牛客网 (nowcoder.com)](https://bbs.csdn.net/topics/618545628)")

这道题十分简单,我的做法是把下面的数据转换为numpy的ndarray矩阵取出最后一列,直接套公式:
import numpy as np
import pandas as pd
from collections import Counter
dataSet = pd.read_csv(‘dataSet.csv’, header=None).values[:, -1]
def calcInfoEnt(dataSet):
numEntres = len(dataSet)
cnt = Counter(dataSet) # 计数每个值出现的次数
probability_lst = [1.0 * cnt[i] / numEntres for i in cnt]
return -np.sum([p * np.log2§ for p in probability_lst])
if name == ‘main’:
print(calcInfoEnt(dataSet))
#### 信息增益的计算
原题:[决策树的生成与训练-信息增益\_牛客题霸\_牛客网 (nowcoder.com)](https://bbs.csdn.net/topics/618545628)")

import numpy as np
import pandas as pd
from collections import Counter
import random
dataSet = pd.read_csv(‘dataSet.csv’, header=None).values.T # 转置 5*15数组
def entropy(data): # data 一维数组
numEntres = len(data)
cnt = Counter(data) # 计数每个值出现的次数 Counter({1: 8, 0: 5})
probability_lst = [1.0 * cnt[i] / numEntres for i in cnt]
return -np.sum([p * np.log2§ for p in probability_lst]) # 返回信息熵
def calc_max_info_gain(dataSet):
label = np.array(dataSet[-1])
total_entropy = entropy(label)
max_info_gain = [0, 0]
for feature in range(4): # 4种特征 我命名为特征:0 1 2 3
f_index = {}
for idx, v in enumerate(dataSet[feature]):
if v not in f_index:
f_index[v] = []
f_index[v].append(idx)
f_impurity = 0
for k in f_index:
# 根据该特征取值对应的数组下标 取出对应的标签列表 比如分支1有多少个正负例 分支2有...
f_l = label[f_index[k]]
f_impurity += entropy(f_l) * len(f_l) / len(label) # 循环结束得到各分支混杂度的期望
gain = total_entropy - f_impurity # 信息增益IG
if gain > max_info_gain[1]:
max_info_gain = [feature, gain]
return max_info_gain
if name == ‘main’:
info_res = calc_max_info_gain(dataSet)
print(“信息增益最大的特征索引为:{0},对应的信息增益为{1}”.format(info_res[0], info_res[1]))
#### 使用梯度下降对逻辑回归进行训练
原题:[使用梯度下降对逻辑回归进行训练\_牛客题霸\_牛客网 (nowcoder.com)](https://bbs.csdn.net/topics/618545628)")
import numpy as np
import pandas as pd
def generate_data():
datasets = pd.read_csv(‘dataSet.csv’, header=None).values.tolist()
labels = pd.read_csv(‘labels.csv’, header=None).values.tolist()
return datasets, labels
def sigmoid(X):
hx = 1/(1+np.exp(-X))
return hx
#code end here
def gradientDescent(dataMatIn, classLabels):
alpha = 0.001 # 学习率,也就是题目描述中的 α
iteration_nums = 100 # 迭代次数,也就是for循环的次数
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(dataMatrix) # 返回dataMatrix的大小。m为行数,n为列数。
weight_mat = np.ones((n, 1)) #初始化权重矩阵
for i in range(iteration_nums):
hx=sigmoid(dataMatrix*weight_mat)
weight_mat-=alpha*dataMatrix.transpose()*(hx-labelMat)
return weight_mat
if name == ‘main’:
dataMat, labelMat = generate_data()
print(gradientDescent(dataMat, labelMat))


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









